ディープラーニングが世間に広まるようになったのは、2012年頃。画像認識のコンペティションでディープラーニングのチームが圧勝してからだ。
このあたりから、ディープラーニングを使った機械学習モデルが各種state-of-the-artを更新していくこととなる。
DropoutはHinton氏によって2012年に提案された、ニューラルネットワークの過学習を防ぐためのシンプルかつパワフルな手法だ。
本記事では、
- Dropoutとはなにか
- Dropoutの実装方法
- Dropout最適化のコツ
を紹介する。
Dropoutとは何か
ニューラルネットワークの構造が複雑化していくにつれて、ニューロンの重みは訓練データセットに最適化されていってしまう。汎化作用が働かず、1つ1つのデータを暗記していくように、訓練データセットにしか使えない貧弱なモデルとなる。
訓練データの正答率は徐々に上がっていくが、テストデータの誤差は減少が止まり、また増加しはじめるのだ。このような状態を過学習という。
ニューラルネットワークの過学習を防ぐ方法は4つある。
- 訓練データセットを増やす
- モデルの複雑性を減らす
- Early Stopping(早期終了)
- モデルの複雑さにペナルティを与える(正則化)
Dropoutはニューラルネットワークの過学習を防ぐために提案されたテクニックで、一定の確率でランダムにニューロンを無視して学習を進める正則化の一種だ。
以下の図を見て欲しい。
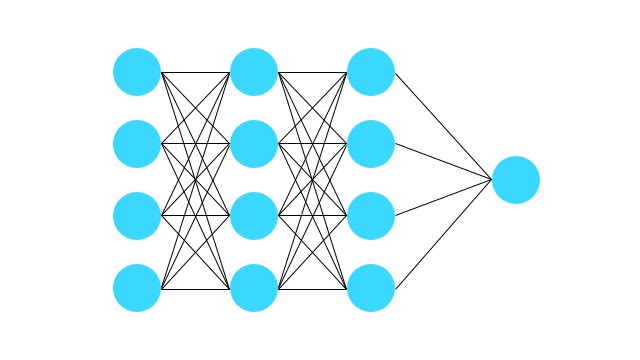
このように、ノード間が全て繋がったニューラルネットワークを下の図のように、学習時には一定の確率で無視する。
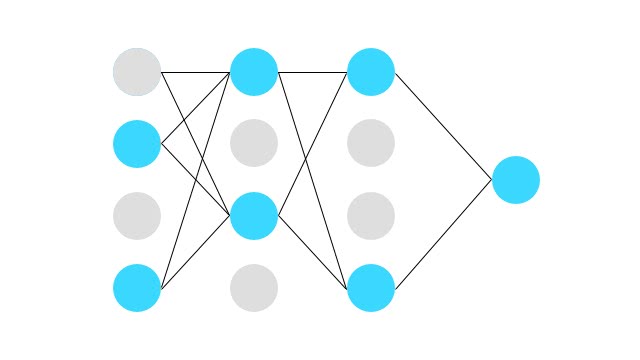
こうすると一時的に、ニューロンが活性化しなくなる。そして重みの更新もバックプロパゲーション時にされない。
機械学習の分野には、アンサンブル学習といって複数の認識器の出力結果を利用することで効果が上がることが分かっている。複数の構造を持つニューラルネットワークを個別に学習させ、各識別器の出力の平均値を認識結果とする。
Dropoutにはこれと同様の効果があり、複数の独立したニューラルネットワークを学習しているとみなすことができる。訓練時にランダムでニューロンを消去していくことで、毎回異なるニューラルネットワークを学習していることになる。
複数のニューラルネットワークの合議制で予測をすると、より良い結果になることが分かっているが、その分計算コストが増大する。 Dropoutはただ訓練時にランダムでニューロンを選択していくだけだ。これならお手軽にアンサンブル学習できる。
Dropoutを実装してみよう
それでは、Dropoutを試してみよう。TensorFlowのラッパーTFLearnを使って、クレジットカードの加入審査をニューラルネットワークで学習してみよう。
TFLearnのインストール
TensorFlowは事前にインストールしておこう。
- 機械学習ライブラリscikit-learn
- Deep LearningフレームワークTFLearn
をインストールする。
$ pip install sklearn tflearn
Dropoutを適用するコツ
実装する前に、Dropoutを適用していくコツを紹介しよう。提案者のHintonらは、チューニングの方法に関しても示唆している。
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Dropoutを使うときのいくつか便利なヒューリスティックスをあげている。
以下のような方針でDropoutを適用していこう。
- 控えめなサイズでニューラルネットワークを構築する
- 過学習を起こすまでネットワークのサイズを大きくしていく
- 過学習を起こしたら、入力層にDropout率0.2、隠れ層に0.5を適用する
- パラメータを微調整
- テスト時にはDropoutは使わない
クレジットカードの審査判定を自動化する
クレジットカードの審査判定を学習させてみる。
こちらから
「Data Foloder」をクリックしてcrx.dataをcredit.csvとして保存する。
headコマンドで中身を見てみよう。
$ head credit.csv
b,30.83,0,u,g,w,v,1.25,t,t,01,f,g,00202,0,+
a,58.67,4.46,u,g,q,h,3.04,t,t,06,f,g,00043,560,+
a,24.50,0.5,u,g,q,h,1.5,t,f,0,f,g,00280,824,+
b,27.83,1.54,u,g,w,v,3.75,t,t,05,t,g,00100,3,+
b,20.17,5.625,u,g,w,v,1.71,t,f,0,f,s,00120,0,+
b,32.08,4,u,g,m,v,2.5,t,f,0,t,g,00360,0,+
b,33.17,1.04,u,g,r,h,6.5,t,f,0,t,g,00164,31285,+
a,22.92,11.585,u,g,cc,v,0.04,t,f,0,f,g,00080,1349,+
b,54.42,0.5,y,p,k,h,3.96,t,f,0,f,g,00180,314,+
b,42.50,4.915,y,p,w,v,3.165,t,f,0,t,g,00052,1442,+
最後のカラムに判定結果が+/-で入っている。 残りはカテゴリ変数や連続値になっているようだ。
次に必要なライブラリをインポートしてCSVを読み込む。
from __future__ import print_function
import numpy as np
import tflearn
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, MinMaxScaler
from tflearn.datasets import titanic
from tflearn.data_utils import load_csv
data, labels = load_csv('credit.csv',
target_column=-1,
has_header=False,
categorical_labels=False, n_classes=2)target_columnは正解ラベルとなるので、-1を指定すると最後のカラムとなる。
n_classesには+と-の2クラス分類となるので2としておこう。
データの前処理をする。数値は0~1に正規化して、カテゴリ変数はone-hotベクトルとしよう。
def encode_label(data):
enc = LabelEncoder()
label_encoded = enc.fit_transform([[x] for x in data])
enc = OneHotEncoder()
return enc.fit_transform([[x] for x in label_encoded]).toarray()
def encode_number(data):
enc = MinMaxScaler()
return enc.fit_transform([[x] for x in data])
def encode_feature(data):
try:
return encode_number([float(x) for x in data])
except Exception:
if isinstance(data[0], str):
return encode_label(data)
return data
# Preprocessing function
def preprocess(data):
arr = np.array(data)
cols = []
for i in range(arr.shape[1]):
col = encode_feature(arr[:,i])
cols.append(col)
return np.column_stack(cols)
data = preprocess(data)
labels = encode_label(labels)訓練データとテストデータに分割する。 今回は690とデータ数は多くないので、末尾の20%をテストデータとしよう。
def split_data(x, y, test_size):
pos = round(len(x) * (1 - test_size))
trainX, trainY = x[:pos], y[:pos]
testX, testY = x[pos:], y[pos:]
return trainX, trainY, testX, testY
trainX, trainY, testX, testY = split_data(data, labels, 0.2)ニューラルネットワークを構築する
それでは、ニューラルネットワークを構築していこう。 今回は中間層2層としてみよう。
def create_model():
net = tflearn.input_data(shape=[None, 570])
net = tflearn.fully_connected(net, 128)
net = tflearn.fully_connected(net, 128)
net = tflearn.fully_connected(net, 2, activation='softmax')
net = tflearn.regression(net, loss='categorical_crossentropy')
return net
net = create_model()
model = tflearn.DNN(net)
model.fit(trainX, trainY, n_epoch=12, show_metric=True,
validation_set=(testX, testY),
run_id='credit_model')
print('Accuracy: {0:.3f}'.format(model.evaluate(testX, testY)[0]))まずはDropoutなしで実行
それでは実行してみる。
$ python credit.py
---------------------------------
Run id: credit_model
Log directory: /tmp/tflearn_logs/
---------------------------------
Training samples: 552
Validation samples: 138
--
Training Step: 9 | total loss: 0.67068
| Adam | epoch: 001 | loss: 0.67068 - acc: 0.6244 | val_loss: 0.64422 - val_acc: 0.7174 -- iter: 552/552
--
Training Step: 18 | total loss: 0.61664
| Adam | epoch: 002 | loss: 0.61664 - acc: 0.7623 | val_loss: 0.50971 - val_acc: 0.8261 -- iter: 552/552
--
Training Step: 27 | total loss: 0.41894
| Adam | epoch: 003 | loss: 0.41894 - acc: 0.8599 | val_loss: 0.35981 - val_acc: 0.8333 -- iter: 552/552
--
Training Step: 36 | total loss: 0.33703
| Adam | epoch: 004 | loss: 0.33703 - acc: 0.8717 | val_loss: 0.28218 - val_acc: 0.8986 -- iter: 552/552
--
Training Step: 45 | total loss: 0.34056
| Adam | epoch: 005 | loss: 0.34056 - acc: 0.8887 | val_loss: 0.28415 - val_acc: 0.9130 -- iter: 552/552
--
Training Step: 54 | total loss: 0.32153
| Adam | epoch: 006 | loss: 0.32153 - acc: 0.9001 | val_loss: 0.27940 - val_acc: 0.9203 -- iter: 552/552
--
Training Step: 63 | total loss: 0.24216
| Adam | epoch: 007 | loss: 0.24216 - acc: 0.9227 | val_loss: 0.24656 - val_acc: 0.9348 -- iter: 552/552
--
Training Step: 72 | total loss: 0.32444
| Adam | epoch: 008 | loss: 0.32444 - acc: 0.8979 | val_loss: 0.27628 - val_acc: 0.8986 -- iter: 552/552
--
Training Step: 81 | total loss: 0.34120
| Adam | epoch: 009 | loss: 0.34120 - acc: 0.8925 | val_loss: 0.26944 - val_acc: 0.8986 -- iter: 552/552
--
Training Step: 90 | total loss: 0.34746
| Adam | epoch: 010 | loss: 0.34746 - acc: 0.8859 | val_loss: 0.29678 - val_acc: 0.8623 -- iter: 552/552
--
Training Step: 99 | total loss: 0.33517
| Adam | epoch: 011 | loss: 0.33517 - acc: 0.9002 | val_loss: 0.30945 - val_acc: 0.8333 -- iter: 552/552
--
Training Step: 108 | total loss: 0.39214
| Adam | epoch: 012 | loss: 0.39214 - acc: 0.8826 | val_loss: 0.33030 - val_acc: 0.8406 -- iter: 552/552
--
Accuracy: 0.841TensorBoardで可視化してみよう。
$ tensorboard --logdir=/tmp/tflearn_logs
として、ブラウザからlocalhost:6006にアクセスする。
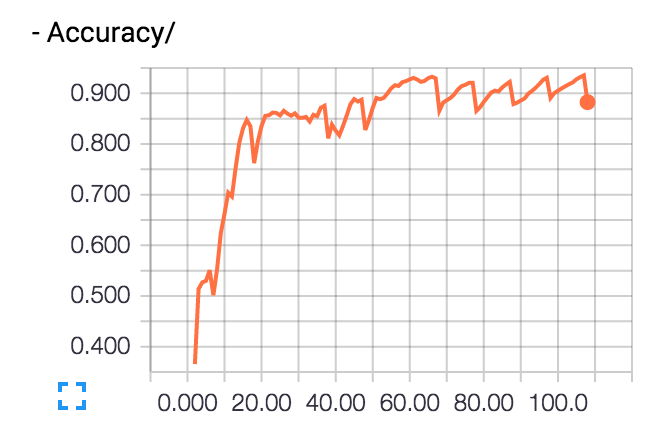
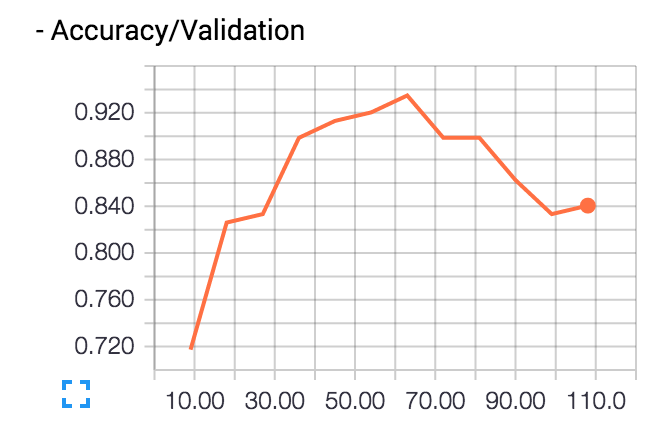
訓練データの正答率(Accuracy)は90%を超えていくが、 テストデータの正答率(Accuracy/Validation)は途中から下がっていく。
これが過学習だ。徐々に訓練データに最適化されていき汎化作用が働かなくなっていく。
隠れ層にDropout0.5、入力層に0.2で設定しよう
それではDropoutを適用していこう。
まずは、Hinton氏の提案通り入力層は0.2、隠れ層は0.5にしておく。
TFLearnのdropout関数は1-dropout率を指定する。
def create_model2():
net = tflearn.input_data(shape=[None, 570])
net = tflearn.dropout(net, 0.8)
net = tflearn.fully_connected(net, 128)
net = tflearn.dropout(net, 0.5)
net = tflearn.fully_connected(net, 128)
net = tflearn.dropout(net, 0.5)
net = tflearn.fully_connected(net, 2, activation='softmax')
net = tflearn.regression(net, loss='categorical_crossentropy')
return net
net = create_model2()
model = tflearn.DNN(net)
model.fit(trainX, trainY, n_epoch=12, show_metric=True,
validation_set=(testX, testY),
run_id='credit_model2')として実行しよう。
---------------------------------
Run id: credit_model3
Log directory: /tmp/tflearn_logs/
---------------------------------
Training samples: 552
Validation samples: 138
--
Training Step: 9 | total loss: 0.68215
Training Step: 9 | total loss: 0.68215cc: 0.6140 | val_loss: 0.66356 - val_acc: 0.6739 -- iter: 552/55| Adam | epoch: 001 | loss: 0.68215 - acc: 0.6140 | val_loss: 0.66356 - val_acc: 0.6739 -- iter: 552/552
--
Training Step: 18 | total loss: 0.64865
Training Step: 18 | total loss: 0.64865c: 0.7140 | val_loss: 0.56812 - val_acc: 0.8406 -- iter: 552/55| Adam | epoch: 002 | loss: 0.64865 - acc: 0.7140 | val_loss: 0.56812 - val_acc: 0.8406 -- iter: 552/552
--
Training Step: 27 | total loss: 0.50208
Training Step: 27 | total loss: 0.50208c: 0.8181 | val_loss: 0.40775 - val_acc: 0.8551 -- iter: 552/55| Adam | epoch: 003 | loss: 0.50208 - acc: 0.8181 | val_loss: 0.40775 - val_acc: 0.8551 -- iter: 552/552
--
Training Step: 36 | total loss: 0.42667
Training Step: 36 | total loss: 0.42667c: 0.8374 | val_loss: 0.31414 - val_acc: 0.8841 -- iter: 552/55| Adam | epoch: 004 | loss: 0.42667 - acc: 0.8374 | val_loss: 0.31414 - val_acc: 0.8841 -- iter: 552/552
--
Training Step: 45 | total loss: 0.38010
Training Step: 45 | total loss: 0.38010c: 0.8537 | val_loss: 0.28768 - val_acc: 0.9058 -- iter: 552/55| Adam | epoch: 005 | loss: 0.38010 - acc: 0.8537 | val_loss: 0.28768 - val_acc: 0.9058 -- iter: 552/552
--
Training Step: 54 | total loss: 0.33138
Training Step: 54 | total loss: 0.33138c: 0.8825 | val_loss: 0.27108 - val_acc: 0.9130 -- iter: 552/55| Adam | epoch: 006 | loss: 0.33138 - acc: 0.8825 | val_loss: 0.27108 - val_acc: 0.9130 -- iter: 552/552
--
Training Step: 63 | total loss: 0.36390
Training Step: 63 | total loss: 0.36390c: 0.8703 | val_loss: 0.28077 - val_acc: 0.9130 -- iter: 552/55| Adam | epoch: 007 | loss: 0.36390 - acc: 0.8703 | val_loss: 0.28077 - val_acc: 0.9130 -- iter: 552/552
--
Training Step: 72 | total loss: 0.40350
Training Step: 72 | total loss: 0.40350c: 0.8362 | val_loss: 0.29260 - val_acc: 0.9058 -- iter: 552/55| Adam | epoch: 008 | loss: 0.40350 - acc: 0.8362 | val_loss: 0.29260 - val_acc: 0.9058 -- iter: 552/552
--
Training Step: 81 | total loss: 0.38956
Training Step: 81 | total loss: 0.38956c: 0.8474 | val_loss: 0.31709 - val_acc: 0.8986 -- iter: 552/55| Adam | epoch: 009 | loss: 0.38956 - acc: 0.8474 | val_loss: 0.31709 - val_acc: 0.8986 -- iter: 552/552
--
Training Step: 90 | total loss: 0.40024
Training Step: 90 | total loss: 0.40024c: 0.8598 | val_loss: 0.30264 - val_acc: 0.9058 -- iter: 552/55| Adam | epoch: 010 | loss: 0.40024 - acc: 0.8598 | val_loss: 0.30264 - val_acc: 0.9058 -- iter: 552/552
--
Training Step: 99 | total loss: 0.31736
Training Step: 99 | total loss: 0.31736c: 0.8925 | val_loss: 0.27981 - val_acc: 0.9058 -- iter: 552/55| Adam | epoch: 011 | loss: 0.31736 - acc: 0.8925 | val_loss: 0.27981 - val_acc: 0.9058 -- iter: 552/552
--
Training Step: 108 | total loss: 0.40552
Training Step: 108 | total loss: 0.40552: 0.8602 | val_loss: 0.28479 - val_acc: 0.8986 -- iter: 552/55| Adam | epoch: 012 | loss: 0.40552 - acc: 0.8602 | val_loss: 0.28479 - val_acc: 0.8986 -- iter: 552/552
--
Accuracy: 0.899テストデータで正答率89.9%まで上がった。
TensorBoardで見てみても、先程テストデータで正答率が下がっていたのが抑制されているのが分かる。
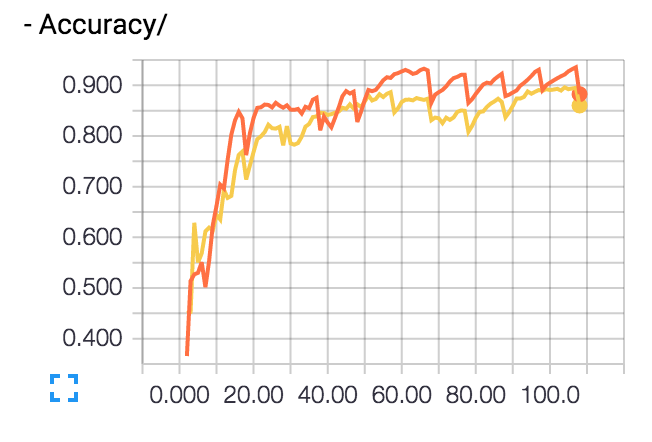
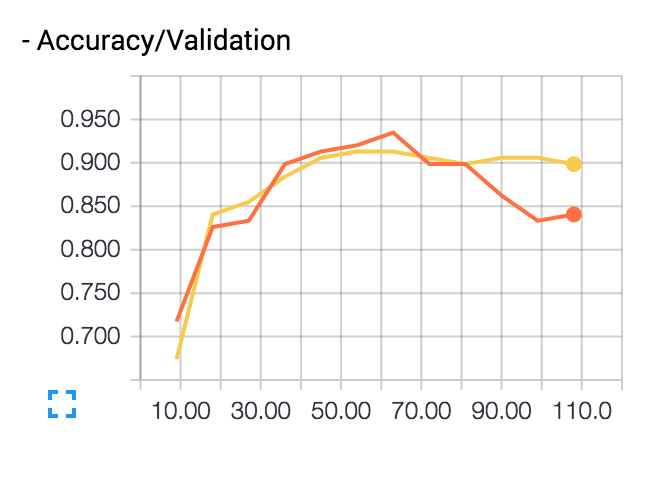
オレンジ色がDropoutなし、Dropout付きが黄色だ。
まとめ
本記事では、ニューラルネットワークのニューロンをランダムで取り除いて学習していくことで過学習を抑制できることを見てきた。
そして、Dropoutの使い方・最適化のコツも合わせて紹介した。
最近では、Dropoutの他にもモデルの過学習を防ぐ方法は他にもいくつか提案されている。
そちらも、後に紹介していきたい。