NumPyには、次元数や形状が揃っていない場合でも、プログラマが揃える処理を書かなくてもいいように簡単に計算を記述できるようになるブロードキャスト(Broadcasting)という機能が備わっています。
ブロードキャストは、NumPy配列が異なった次元・形状でも計算できるかを判断して処理するシンプルな4つのルールを元に行われます。
本記事では、ブロードキャストの仕組みとメリットを解説します。
ブロードキャストとは
ブロードキャストとは、例えば配列の要素同士の加算を行う時、それぞれの配列の形状(shape)が合致していない場合があります。そんなときに配列の形状を計算できるように合わせて計算を行うのがブロードキャスト機能です。
以下のコードを見てください。
In [1]: import numpy as np
In [2]: np.array([[1, 2, 3]]) + [1]
Out[2]: array([[2, 3, 4]])(1, 3)の形状の2次元NumPy配列と、1を要素に含む1次元リストを足し合わせることができます。
この機能があることで、手動で同じ要素を繰り返し入力して配列のshapeを合わせてから演算を行わせるといった余計な手間を省くことができます。また、一般的にPythonで各計算を記述することでコード量を多くするよりも、NumPyに処理を任せたほうが実行速度は速くなる傾向にあります。さらに、メモリの使用量を節約するといったメリットもあります。
ブロードキャストでは何が起こっているのか
ブロードキャストのシンプルなルールを把握しておくと、コードを読む際には素早く理解することができ、書く際には簡便に記述することが出来ます。公式サイトの説明にあるルールを紹介していきます。
ルール1. ブロードキャスト対象の配列の中で、次元数(ndim)が異なるときはshapeの先頭に1を入れることで調整する
np.array([[1, 2]])とnp.array([3, 4])を足し算する例で考えてみます。この場合、両者の次元数が異なります。np.array([[1, 2]])のshapeは、(1, 2)で次元数(ndim)が2あるのに対しnp.array([3, 4])のshapeは(2,)とndimが1となっています。
In [1]: import numpy as np
In [2]: a = np.array([[1, 2]])
In [3]: a.shape
Out[3]: (1, 2)
In [4]: b = np.array([3, 4])
In [5]: b.shape
Out[5]: (2,)ルール通りに考えると、np.array([3, 4])のshapeの先頭に1を入れます。つまり(1, 2)と変換されて計算されます。
In [6]: a + b
Out[6]: array([[4, 6]])np.array([3, 4]) → np.array([[3, 4]])とみなされて計算されるイメージです。
ルール2. 計算処理に用いることのできる配列は、各次元の要素数が、最も大きい値に等しい、もしくはちょうど1となっているようなものである
では、ブロードキャスト可能な条件を考えてみます。NumPyのブロードキャストのルールでは、各次元の要素数が最も大きい値に等しいかちょうど1の場合にブロードキャスト可能になります。
つまり、以下のような形状同士であれば、ブロードキャスト可能になります。
(1, 4, 3) ⇔ (2, 4, 3)
(2, 4, 1) ⇔ (2, 4, 3)
(2, 1, 3) ⇔ (2, 4, 3)
(2, 1, 1) ⇔ (2, 4, 3)
(1, 1, 1) ⇔ (2, 4, 3)
また、ルール1と組み合わせることで、以下のような次元が異なる場合でも先頭に1を追加すれば計算可能です。
(1, 3) ⇔ (2, 4, 3)
→ (1, 1, 3) ⇔ (2, 4, 3)
(1,) ⇔ (2, 4, 3)
→ (1, 1) ⇔ (2, 4, 3)
→ (1, 1, 1) ⇔ (2, 4, 3)
ルール3. 出力される配列のshapeは調整されたshapeのそれぞれの次元において最も要素数の多いものに合わせられる
計算の出力結果は、各次元の要素数の最大値が使用されます。従って、(1, 1, 3)と(4, 2, 1)とでブロードキャストする場合の出力形状は各次元の最大値をとって(4, 2, 3)となります。
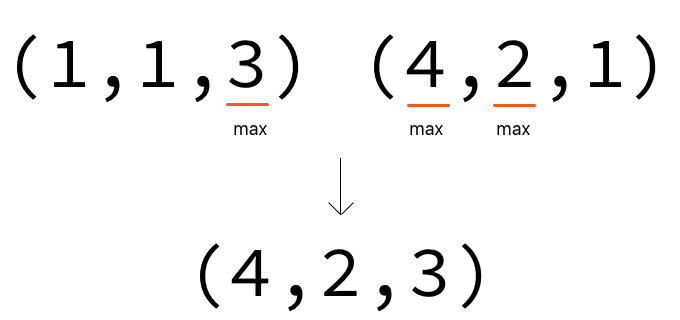
ルール4. 要素数が1となっている次元の軸については、値は全て同じものが繰り返される。
ブロードキャスト可能な条件と、ブロードキャスト後の形状は上記のルールで分かりました。しかしながら、両者の要素数が一致しない場合、どのようにして値を補うのでしょうか。
NumPyのブロードキャストは、対象の軸以外の要素を繰り返します。
例えば、3×2の2次元配列と要素数が2の1次元配列との足し算では、1次元配列の行を3回繰り返した2次元配列として計算されます。
具体的な例として、まずは1次元配列と2次元配列の加算の例を見てみます。
In [1]: import numpy as np
In [2]: a = np.array([1,2])
In [3]: b = np.array([[3,4],[2,3]])
In [4]: a
Out[4]: array([1, 2])
In [5]: b
Out[5]:
array([[3, 4],
[2, 3]])
In [7]: a.shape
Out[7]: (2,)
In [8]: b.shape
Out[8]: (2, 2)ここで、a+bを実行するとブロードキャストが適用されます。以下の図のようなイメージで変換されます。注意すべき点としては、配列aが拡張されているのは列方向ではなく、行方向だということです。
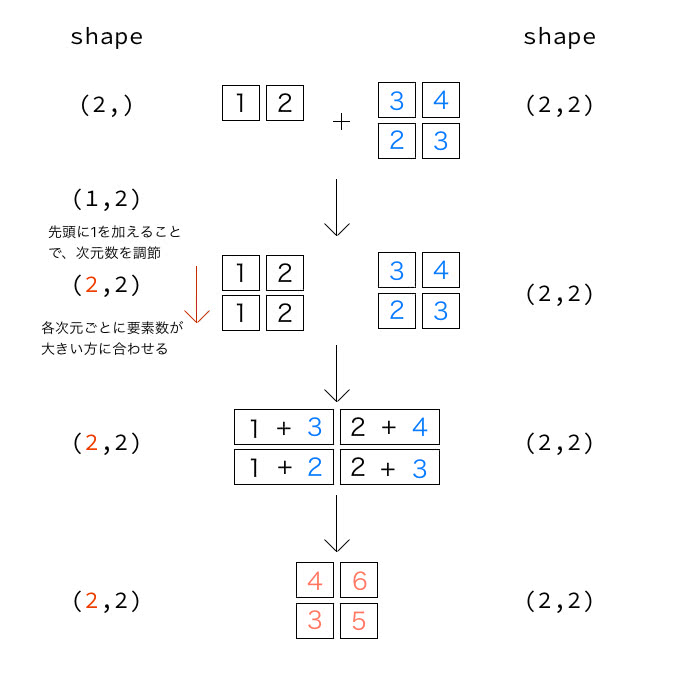
このように、aの形状(shape)を(2,)から次元数を合わせるために先頭に1をいれた形である(1, 2)に変換し直した後、行方向に要素をコピーしたものを拡張します。ここまでできたら、あとは対応する要素同士で足し算するだけです。実際にこのような結果になるか確かめてみましょう。
In [6]: a + b
Out[6]:
array([[4, 6],
[3, 5]])手順通り正しい結果が出力されました。
次は、少し複雑になりますが3次元の例を見ていきます。 下の3つの配列の和を考えていきましょう。
In [10]: a = np.array([[2], [1]])
In [11]: b = np.array([5])
In [12]: c = np.array([[[1, 2, 3], [4, 5, 6]],[[7, 8, 9], [10, 11, 12]]])
In [13]: a
Out[13]:
array([[2],
[1]])
In [14]: b
Out[14]: array([5])
In [15]:
In [15]: c
Out[15]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])まず、これらのshapeを確認していきます。
In [16]: a.shape
Out[16]: (2, 1)
In [17]: b.shape
Out[17]: (1,)
In [18]: c.shape
Out[18]: (2, 2, 3)では、これらの情報を基に、和をとったときに返される配列のshapeをまずは予想してみます。
最初に、ルール1 を使って次元数を合わせます。
次に、それぞれの次元においての要素数を合わせていきます。ルール2、3の通り次元数が1の要素を最大値に合わせます。
手順通りに計算すると、出力されるNumPy配列のshapeは(2, 2, 3)になりそうです。結果を確認してみます。
In [19]: a + b + c
Out[19]:
array([[[ 8, 9, 10],
[10, 11, 12]],
[[14, 15, 16],
[16, 17, 18]]])実際に(2, 2, 3)の形状のNumPy配列が出力されました。このshapeを合致させる感覚が分かれば、どの場合にブロードキャストが適用されるのかすぐにわかるようになるでしょう。