Pandasにはデータ間の差分をとる関数が実装されています。
1つは単純な差をとったdiff関数で、もう1つは変化の比率をとったpct_changeです。この関数を知っていると売上高の変化や、株価の変化率を簡単に取得することができます。
diff関数はNumPyでも実装されていますが、挙動が若干異なりますのでその辺りも解説していきます。
pct_change関数
まずは変化の比率を計算するpct_change関数です。
APIドキュメント
APIドキュメントは以下の通りです。
pandas.Series.pct_change(periods=1,fill_method=’pad’,limit=None,freq=None, **kwargs)
params:
| パラメータ名 | 型 | 概要 |
|---|---|---|
| periods | int | (省略可能)初期値1 差分の比率を取るデータの間隔を指定します。 |
| fill_method | ‘pad’,’bfill’,’ffill’など | (省略可能)初期値’pad’ NaN値が現れた時にどのように穴埋めをするかを指定します。 |
| limit | int | (省略可能)初期値None NaN値を穴埋めする時、前後の値を何回まで繰り返して良いかを指定します。デフォルトでは特に制限は設けられていません。 |
| freq | DateOffset,timedelta もしくはオフセットを記述したstr |
(省略可能)初期値None TimeSeriesデータにおいてどれくらいの間隔で値の差分の比率を取るかを指定します。 |
returns:
差分をとったDataFrameかSeriesが返されます。
引数periodsについて
引数periodsが少しとっつきにくいと感じたので簡単に図にして説明してみます。periodsは、以下の図のように参照している要素からの間隔のことです。
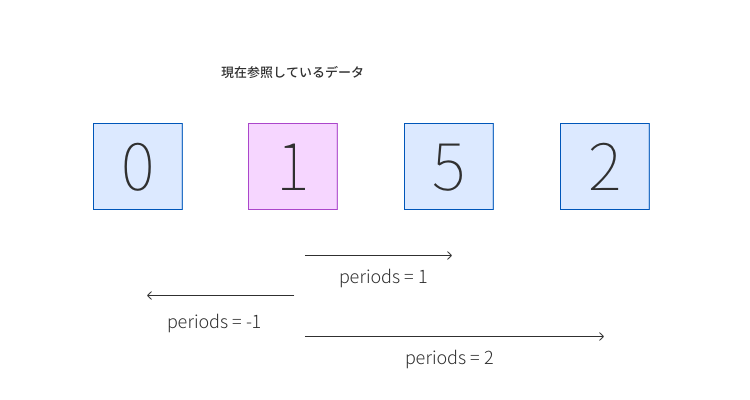
つまり差分をとるときにどれだけの間隔かを指定することができます。以下の図はperiods=1でdiffを適用した場合です。このように、参照しているデータを引くのが基本となります。引かれる値の所に計算結果が代入されることになります。
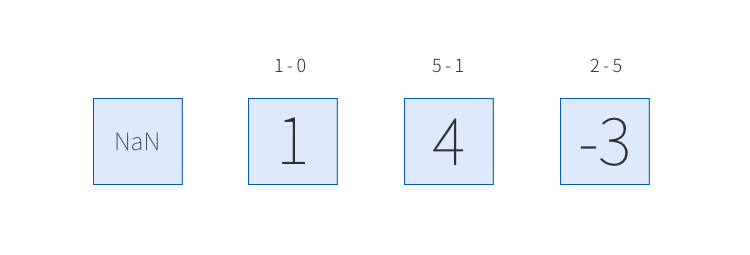
そのため、引く相手のいない値については欠損値となり、NaN値扱いとなります。
基本的な使い方
特に引数を指定しない場合は隣同士のデータ間で差分の比率を計算します。
In [13]: df['A']
Out[13]:
0 0
1 1
2 2
3 3
4 4
5 5
6 6
Name: A, dtype: int64
In [14]: df['A'].pct_change() # 隣り合う要素同士
Out[14]:
0 NaN
1 inf
2 1.000000
3 0.500000
4 0.333333
5 0.250000
6 0.200000
Name: A, dtype: float64
0が要素に含まれていたので無限を表すinfの値が出てしまいました。
periodsを変更する
引数periodsの扱いはperiods=1なら1つ先の値との差分の比率でperiods=-1の時は1つ前の値との差分の比率をとることになります。
In [15]: df
Out[15]:
A B
0 0 0
1 1 4
2 2 1
3 3 6
4 4 2
5 5 35
6 6 8
In [16]: df['A'].pct_change(periods=1) # デフォルト
Out[16]:
0 NaN
1 inf
2 1.000000
3 0.500000
4 0.333333
5 0.250000
6 0.200000
Name: A, dtype: float64
In [17]: df['A'].pct_change(periods=2) # 2個先のものとの差分の比率
Out[17]:
0 NaN
1 NaN
2 inf
3 2.000000
4 1.000000
5 0.666667
6 0.500000
Name: A, dtype: float64
In [18]: df['A'].pct_change(periods=-1) # 1つ前のものとの差分の比率
Out[18]:
0 -1.000000
1 -0.500000
2 -0.333333
3 -0.250000
4 -0.200000
5 -0.166667
6 NaN
Name: A, dtype: float64
欠損値の穴埋めをする
差分を計算する前に欠損値が含まれている場合は直前の値を自動的に取るようになっていますが、変えることもできます。
fill_method引数を色々変更してみましょう。
In [28]: sr_a
Out[28]:
0 0
1 1
2 2
3 None
4 4
5 5
6 6
Name: A, dtype: object
In [29]: sr_a.pct_change()
Out[29]:
0 NaN
1 inf
2 1.000000
3 0.000000
4 1.000000
5 0.250000
6 0.200000
Name: A, dtype: float64
In [30]: sr_a.pct_change(fill_method='bfill')
Out[30]:
0 NaN
1 inf
2 1.000000
3 1.000000
4 0.000000
5 0.250000
6 0.200000
Name: A, dtype: float64
limitを使って穴埋めする回数の制限が可能です。
回数の制限をすることで穴埋めされない箇所が1つあると2つ分の欠損値が発生します。
In [31]: sr_a[4] = None
In [32]: sr_a
Out[32]:
0 0
1 1
2 2
3 None
4 None
5 5
6 6
Name: A, dtype: object
In [33]: sr_a.pct_change(limit=2) # 2個連続しているのでlimit=2だと問題なく穴埋めできる
Out[33]:
0 NaN
1 inf
2 1.000000
3 0.000000
4 0.000000
5 1.500000
6 0.200000
Name: A, dtype: float64
In [34]: sr_a.pct_change(limit=1) # 1つまでに制限すると4番目にある値の穴埋めがされないので4,5番目の差分の比率が取れなくなる
Out[34]:
0 NaN
1 inf
2 1.000000
3 0.000000
4 NaN
5 NaN
6 0.200000
Name: A, dtype: float64
diff関数
APIドキュメント
diff関数のAPIドキュメントは以下の通りです。
Seriesにも同じ関数があり、違いとしてはaxis引数があるかどうかにあります。
pandas.DataFrame.diff(periods=1,axis=0)
params:
| パラメータ名 | 型 | 概要 |
|---|---|---|
| periods | int | (省略可能)初期値1 現在のデータからどれだけ進んだデータとの差分を取るかを指定します(負の値の場合は後ろの値との差分をさします)。 |
| axis | 0または’index’ 1または’columns’ |
(省略可能)初期値0 行間(axis=0or’index’)の差分を取るか列間(axis=1or’columns’)の差分を取るかを指定します。 |
returns:
差分をとったデータを格納しているDataFrameが返されます。
引数はシンプルに2つのみです。
単純に差分を取るだけで、差分を取る対象がどこにあるのかがポイントとなります。
参照しているデータ自体をどの値から引くかを指定するかと考えると分かりやすいかもしれません。
行間の差分を取る
行間の差分を取るときは特にaxis引数を指定する必要がないです。
一番単純な1つ隣の値を引いていきます。
In [1]: import pandas as pd
In [2]: df = pd.DataFrame({'A':[0, 1, 2, 3, 4, 5, 6],
...: 'B':[0, 4, 1, 6, 2, 35,8]})
...:
In [3]: df.diff() # 行間で差を取る
Out[3]:
A B
0 NaN NaN
1 1.0 4.0
2 1.0 -3.0
3 1.0 5.0
4 1.0 -4.0
5 1.0 33.0
6 1.0 -27.0
このとき、一番最初の値は1つ後ろの値が存在しないためNaN値となります。
列間の差分を取る
axis=1またはaxis='columns'とすれば良いです。
In [4]: df.diff(axis=1) # axis='columns'でも可能
Out[4]:
A B
0 NaN 0.0
1 NaN 3.0
2 NaN -1.0
3 NaN 3.0
4 NaN -2.0
5 NaN 30.0
6 NaN 2.0
periodsを変えて差分を取る距離を変更する
今度はperiods引数を変更して差分を取る距離を変えてみます。
デフォルトではperiods=1となっており、1つ後ろの値を引く値をとっていましたが、periods=2にすれば2つ先になります。
逆にperiods=-1とすれば1つ前の値をとります。
In [5]: df
Out[5]:
A B
0 0 0
1 1 4
2 2 1
3 3 6
4 4 2
5 5 35
6 6 8
In [6]: df.diff(periods=1) # デフォルト
Out[6]:
A B
0 NaN NaN
1 1.0 4.0
2 1.0 -3.0
3 1.0 5.0
4 1.0 -4.0
5 1.0 33.0
6 1.0 -27.0
In [7]: df.diff(periods=2)
Out[7]:
A B
0 NaN NaN
1 NaN NaN
2 2.0 1.0
3 2.0 2.0
4 2.0 1.0
5 2.0 29.0
6 2.0 6.0
In [8]: df.diff(periods=-1)
Out[8]:
A B
0 -1.0 -4.0
1 -1.0 3.0
2 -1.0 -5.0
3 -1.0 4.0
4 -1.0 -33.0
5 -1.0 27.0
6 NaN NaN
Seriesへの適用
Seriesへも適用可能です。
In [9]: df['A'].diff()
Out[9]:
0 NaN
1 1.0
2 1.0
3 1.0
4 1.0
5 1.0
6 1.0
Name: A, dtype: float64
shift関数を使った再現
shift関数を使ってdiff関数の挙動を再現することができます。
In [10]: df['A'] - df['A'].shift() # periods=1
Out[10]:
0 NaN
1 1.0
2 1.0
3 1.0
4 1.0
5 1.0
6 1.0
Name: A, dtype: float64
In [11]: df['A'] - df['A'].shift(periods=2)
Out[11]:
0 NaN
1 NaN
2 2.0
3 2.0
4 2.0
5 2.0
6 2.0
Name: A, dtype: float64
numpyのdiff関数との比較
diff関数ですと欠損値が出ず、データが減ったぶんだけ配列の長さが変化します。
また、差分の取り方が若干違っており、後ろ向きに取るやり方は実装されておらず前向きの差分の取り方のみ実装されています。
NumPyでは数値微分をするための機能が搭載されているためn階微分の数値微分を行うことが可能です。
NumPyのdiff関数の詳しい解説は以下の記事でしています。
要素の差分、足し合わせを計算するNumPyのdiff関数とcumsum関数の使い方 /features/numpy-diff.html
In [37]: import numpy as np
In [38]: np.diff(df) # 引数として直接指定できる
Out[38]:
array([[ 0],
[ 3],
[-1],
[ 3],
[-2],
[30],
[ 2]])
In [39]: df.apply(np.diff) # apply関数を使うとDataFrameのまま値が出力される
Out[39]:
A B
0 1 4
1 1 -3
2 1 5
3 1 -4
4 1 33
5 1 -27
In [40]: df.diff()
Out[40]:
A B
0 NaN NaN
1 1.0 4.0
2 1.0 -3.0
3 1.0 5.0
4 1.0 -4.0
5 1.0 33.0
6 1.0 -27.0
また、NumPyは型にかなりうるさいため、int型で渡された値はきっちりとint型で返されます。 Pandasではint型として渡したものもfloat型として処理されます。
まとめ
今回はデータ間の差分を取る関数について解説しました。
変化の割合を見るということでpct_change関数などは株価の変動の分析などでも使う場面があるかと思います。
Pandasですと手軽の求めることができるのでぜひ使ってみましょう。
また、pct_change関数でfreq引数についてまだ解説していませんが、時系列データについてはまた別途解説していく予定です。