
Pandasにおけるデータ構造DataFrameやSeriesにはデータをラベリングするインデックス名とカラム名が存在します。
仮に、以下のようなDataFrameを作るとします。
In [1]: import pandas as pd
In [2]: a = pd.DataFrame([[1,1,1,],[2,1,2],[3,2,3]],index=["one","two","three"], columns=["a","b","c"])
このとき、aはJupyter Notebook上で以下のように表示されます。
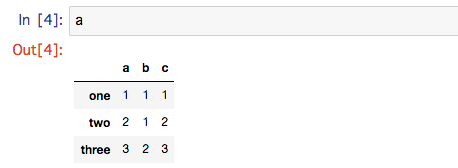
この、"a", "b","c"はカラム名で"one", "two", "three"はインデックス名となります。これはどちらもIndexオブジェクトであり、以下のように表示されます。
In [4]: a.index
Out[4]: Index(['one', 'two', 'three'], dtype='object')
In [5]: a.columns
Out[5]: Index(['a', 'b', 'c'], dtype='object')
今回はこのIndexオブジェクトについて詳しく解説していきます。この記事を読み終わる頃には自由自在にIndexオブジェクトを使えるようになっているはずです。
Indexオブジェクト
Indexオブジェクトは公式ドキュメントで以下のように説明されています。
Immutable ndarray implementing an ordered, sliceable set. The basic object storing axis labels for all pandas objects
これを訳してみると
変更不可能で順序付きのスライシングすることのできる集合を実装する多次元配列。全てのPandasのオブジェクトにおいて、軸ラベルを格納している基本的なオブジェクト。
といった感じになります。前半部分がぎこちない訳になってしまいましたが、Indexオブジェクトによって実装された集合は
- スライシングができる
- 順序が決まっている
- インデックスの内容を変更することができない
ものだということになります。
変更できないというのは、先程の例を使うと、aのindexを'one','two','three'じゃなくて'one', 'eight', 'three'に変えたいとします。このとき、以下のように代入によるインデックスを変更する操作をすることはできません。
In [6]: a.index[1] = 'eight'
---------------------------------------------------------------------------
(エラーメッセージが表示される)
TypeError: Index does not support mutable operations
代わりに変更したい場合は、rename()関数を使います。このとき、rename関数は中身を変更する破壊的な操作はせず、変更されたDataFrameを返します。
In [24]: a.rename(index={"two":"eight"})
Out[24]:
a b c
one 1 1 1
eight 2 1 2
three 3 2 3
このままだとaの中身は変わらないのでinplace=Trueにすることで、ようやくaの中身が変更されます。
n [25]: a
Out[25]:
a b c
one 1 1 1
two 2 1 2
three 3 2 3
In [27]: a.rename(index={"two":"eight"}, inplace=True)
In [28]: a
Out[28]:
a b c
one 1 1 1
eight 2 1 2
three 3 2 3
この関数を使う以外に、同じデータを使ってもう一度DataFrameを新しいインデックスで作り直す方法があります。
DataFrameにあるIndexオブジェクトを直接修正することができず、関数を駆使しないとうまくインデックス名やカラム名を変えることができないのは少々不便に感じるかもしれませんが、データを操作する時うっかり中身を変更するということがなくなるため、思ってもない操作でIndexの中身が変わってしまうバグに遭遇しにくくするような働きがあります。
直感的に操作できない分、インデックスに関する操作はしっかりと把握しておく必要があります。また、Pandasを操作する上では、メモリ効率などの必要な理由がない限りインデックスの変更は避けるべきです。
スライシングができるという部分に関してですが、Pythonのリスト型やNumPyの配列(ndarray)と同様にスライシングで要素を抜き出すことができるという意味です。
以下の操作でスライシングできます。
In [29]: a
Out[29]:
a b c
one 1 1 1
eight 2 1 2
three 3 2 3
In [30]: a.index[:1] # 0から1まで。終点の1は範囲に含まれないので今回は0の要素のみが抜き出される。
Out[30]: Index(['one'], dtype='object')
In [30]: a.index[1:]
Out[30]: Index(['eight', 'three'], dtype='object')
In [31]: a.index[1:2] # 始点と終点を同時に設定することも可能
Out[31]: Index(['eight'], dtype='object')
インデックスとカラムの両方のラベルにIndexオブジェクトが使われており、Pandasの内部では同列に扱われているということが理解できていると、以下の操作をあまり不思議に思わずに受け入れることができるはずです。
以下ではstack関数とunstack関数を使っています。
stack関数はカラムラベルに使われているIndexオブジェクトをインデックスラベルに移してしまう関数です。カラムラベルに1つのIndexオブジェクトしかない場合、stack関数の返り値はSeriesオブジェクトになります。
逆にunstackはインデックスのラベルをカラムのラベルに移す作業を実行します。このときもインデックスラベルにあるIndexオブジェクトが1つしかない場合、返り値はSeriesオブジェクトになってしまいます。
In [32]: a
Out[32]:
a b c
one 1 1 1
eight 2 1 2
three 3 2 3
In [33]: a.stack()
Out[33]:
one a 1
b 1
c 1
eight a 2
b 1
c 2
three a 3
b 2
c 3
dtype: int64
In [34]: a.unstack()
Out[34]:
a one 1
eight 2
three 3
b one 1
eight 1
three 2
c one 1
eight 2
three 3
dtype: int64
このように1つの軸方向(列か行)に2つ以上のIndexオブジェクトが存在することをMultiIndex(マルチインデックス)と呼びます。
Indexオブジェクトに関する基本操作
ここから先はIndexオブジェクトに関する基本操作を見ていきます。
Indexの指定
基本的には、DataFrameオブジェクトやSeriesオブジェクトを作成する際に引数indexとcolumnsを利用して指定します。
要素形成のためNumPyのarange関数とreshape関数を使っています。
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: pd.DataFrame(np.arange(20).reshape(4,5),index=[0, 2, 4, 5], columns=["a","c","d","f","g"])
Out[3]:
a c d f g
0 0 1 2 3 4
2 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
あらかじめ、Indexオブジェクトを生成してから指定することも可能です。
In [5]: index = pd.Index([0,2,4,5])
In [6]: columns= pd.Index(["a","c","d","f","g"])
In [7]: pd.DataFrame(np.arange(20).reshape(4,5), index=index, columns=columns)
Out[7]:
a c d f g
0 0 1 2 3 4
2 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
In [8]: index
Out[8]: Int64Index([0, 2, 4, 5], dtype='int64')
In [9]: columns
Out[9]: Index(['a', 'c', 'd', 'f', 'g'], dtype='object')
指定された値によってIndexオブジェクトの種類が変化していますがこれは後ほど解説します。シンプルにrange関数を使って生成することも可能です。
In [11]: pd.DataFrame(np.arange(20).reshape(4,5),index=range(4),columns=columns)
Out[11]:
a c d f g
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
この場合はわざわざ指定しなくても同じインデックスラベルが自動的に生成されますが。
Indexの変更
ラベルを振り直す
インデックスラベルとカラムラベルを振り直すことも可能です。この操作をするときには、reindex関数が便利です。
この場合、あくまでも振り直すだけなので順番を変えたいときとか新しいインデックスラベルを作りたいときに使うものであり、ラベルそのものの名前を変えることができないことに注意してください。ラベルの値そのものを変更したいときはrename関数を使いましょう。
ラベルと値との対応関係が維持された状態でインデックスやカラムラベルが振り直されます。
In [12]: a = pd.DataFrame(np.arange(20).reshape(4,5),index=[0, 2, 4, 5], columns
...: =["a","c","d","f","g"])
In [13]: a
Out[13]:
a c d f g
0 0 1 2 3 4
2 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
In [14]: a.reindex(range(6))
Out[14]:
a c d f g
0 0.0 1.0 2.0 3.0 4.0
1 NaN NaN NaN NaN NaN
2 5.0 6.0 7.0 8.0 9.0
3 NaN NaN NaN NaN NaN
4 10.0 11.0 12.0 13.0 14.0
5 15.0 16.0 17.0 18.0 19.0
In [15]: a.reindex([0,3,2,1,4,0]) # 同じものを2度繰り返してもよい
Out[15]:
a c d f g
0 0.0 1.0 2.0 3.0 4.0
3 NaN NaN NaN NaN NaN
2 5.0 6.0 7.0 8.0 9.0
1 NaN NaN NaN NaN NaN
4 10.0 11.0 12.0 13.0 14.0
0 0.0 1.0 2.0 3.0 4.0
これを見てわかると思いますが、存在しないラベルが発生した時はNaNで値が埋められます。そして、同じラベルには同じ値が対応しているので同じラベルが繰り返されると対応する値も繰り返されます。
カラムラベルを変更したい場合は引数columnsに直接指定します。インデックスラベルを明示的に変更したい場合は引数indexに直接指定します。
In [20]: a.reindex(columns=["a","b","c","d","e","f","g"])
Out[20]:
a b c d e f g
0 0 NaN 1 2 NaN 3 4
2 5 NaN 6 7 NaN 8 9
4 10 NaN 11 12 NaN 13 14
5 15 NaN 16 17 NaN 18 19
In [21]: a.reindex(index=range(6))
Out[21]:
a c d f g
0 0.0 1.0 2.0 3.0 4.0
1 NaN NaN NaN NaN NaN
2 5.0 6.0 7.0 8.0 9.0
3 NaN NaN NaN NaN NaN
4 10.0 11.0 12.0 13.0 14.0
5 15.0 16.0 17.0 18.0 19.0
NaNのところを埋める方法を指定します。method引数でffillとすれば直前の値を埋めていき、bfillとすれば直後の値を埋めていきます。
In [23]: a.reindex(index=range(6),method='ffill')
Out[23]:
a c d f g
0 0 1 2 3 4
1 0 1 2 3 4
2 5 6 7 8 9
3 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
In [24]: a.reindex(index=range(6),method='bfill')
Out[24]:
a c d f g
0 0 1 2 3 4
1 5 6 7 8 9
2 5 6 7 8 9
3 10 11 12 13 14
4 10 11 12 13 14
5 15 16 17 18 19
ラベルの値を更新する
次に、rename関数を使ってラベルの値を更新します。引数indexとcolumnsそれぞれに辞書形式で{(変更する前のラベル名):(変更後のラベル名)}を指定することで値の更新が可能です。
In [27]: a
Out[27]:
a c d f g
0 0 1 2 3 4
2 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
In [28]: a.rename(columns={'a':'AA'})
Out[28]:
AA c d f g
0 0 1 2 3 4
2 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
In [29]: a.rename(index={0:22})
Out[29]:
a c d f g
22 0 1 2 3 4
2 5 6 7 8 9
4 10 11 12 13 14
5 15 16 17 18 19
Indexオブジェクトとデータ部分との互換
以下のデータを使ってやってみます。
関数set_indexを使ってデータの値をインデックスラベルに変更してみます。
In [52]: df = pd.read_csv('sample_index.csv')
In [53]: df
Out[53]:
age gender name state
0 17 M Tarou Tokyo
1 18 F Hanako Osaka
2 18 M Kakeru Osaka
3 17 F Manaka Nagoya
4 19 M Tomoki Chiba
5 17 F Rin Hakata
In [54]: df.set_index(['state'])
Out[54]:
age gender name
state
Tokyo 17 M Tarou
Osaka 18 F Hanako
Osaka 18 M Kakeru
Nagoya 17 F Manaka
Chiba 19 M Tomoki
Hakata 17 F Rin
In [60]: df_2 = df.set_index(['state'])
In [61]: df_2.set_index(['age'], append=True) # append=TrueにするとMultiIndexになる。Falseだと以前のIndexの値が消失する
Out[61]:
gender name
state age
Tokyo 17 M Tarou
Osaka 18 F Hanako
18 M Kakeru
Nagoya 17 F Manaka
Chiba 19 M Tomoki
Hakata 17 F Rin
reset_index関数を使うとIndexオブジェクトに使用されていた値が列データとして追加されます。
In [63]: df_2.reset_index()
Out[63]:
state age gender name
0 Tokyo 17 M Tarou
1 Osaka 18 F Hanako
2 Osaka 18 M Kakeru
3 Nagoya 17 F Manaka
4 Chiba 19 M Tomoki
5 Hakata 17 F Rin
カラムとインデックスを入れ替える
transpose関数を使うことによって行と列を入れ替えることができます。.Tでも同じことができます。
In [85]: df_2
Out[85]:
age gender name
state
Tokyo 17 M Tarou
Osaka 18 F Hanako
Osaka 18 M Kakeru
Nagoya 17 F Manaka
Chiba 19 M Tomoki
Hakata 17 F Rin
In [86]: df_2.transpose()
Out[86]:
state Tokyo Osaka Osaka Nagoya Chiba Hakata
age 17 18 18 17 19 17
gender M F M F M F
name Tarou Hanako Kakeru Manaka Tomoki Rin
In [87]: df_2.T
Out[87]:
state Tokyo Osaka Osaka Nagoya Chiba Hakata
age 17 18 18 17 19 17
gender M F M F M F
name Tarou Hanako Kakeru Manaka Tomoki Rin
様々なIndexオブジェクト
最後にIndexオブジェクトの様々なタイプを紹介します。
通常はIndexオブジェクトを使うだけでよいのですが、ある特別な場合が生じるとPandas側が自動的にこれらのオブジェクトを割り当てます。これによって、Pandas内での処理速度を向上させる可能性があるようです(公式ドキュメントでも名言はしていません)。
これらを特に把握する必要はあまりないのですが参考程度にそれぞれのAPIドキュメントを掲載しておきます。
まずは普通のIndexオブジェクトから。これが最も基本的です。
class pandas.Index(data, dtype=object, copy=False, name=None, tupleize_cols=True)
params:
| 引数名 | 型 | 概要 |
|---|---|---|
data |
1次元配列に相当するオブジェクト | 使いたいラベルを指定します。 |
dtype |
NumPyのdtype | ラベルに使いたいデータ型を指定します。 |
copy |
bool値 |
dataで指定された配列のコピーを作成するかどうか指定します。 |
name |
object | このIndexオブジェクトの名前を指定します。 |
tupleize_cols |
bool値 | Trueのとき、可能ならばMultiIndexを作成します。 |
次はRangeIndexオブジェクトです。これはインデックスやカラムのラベルに何も指定されなかった場合に自動的に生成されるオブジェクトです。
class pandas.RangeIndex(start=0,stop=0,step=1,name=None,copy=False)
params:
| 引数名 | 型 | 概要 |
|---|---|---|
start |
int | 生成される数列の初項を指定します。 |
stop |
int | 初期値 0 数列の最終地点を指定します。この値自体は含まれません。 |
step |
int | 初期値 1 隣り合う要素同士の間隔を指定します。 |
name |
object | (省略可能)初期値 None オブジェクトに名前をつけます。 |
copy |
bool値 | 初期値 False 使用されない引数です。他のIndexオブジェクトとの統一性のために導入されています。 |
In [67]: rangeindex = pd.RangeIndex(2,10,2)
In [68]: pd.Series([0,3,1,2],index=rangeindex)
Out[68]:
2 0
4 3
6 1
8 2
dtype: int64
次はCategoricalIndexです。Pandasで使われるcategoryとしてIndexを処理します。
class pandas.CategoricalIndex(data, categories=None, ordered=False, copy=False, name=None)
params:
| 引数名 | 型 | 概要 |
|---|---|---|
data |
1次元配列に相当するオブジェクト | 使いたいラベルを指定します。 |
categories |
配列に相当するオブジェクト | category一覧。特に指定のない場合はdataから取得します。 |
ordered |
bool値 | categoriesが順序付けられているかを表します。 |
copy |
bool値 | 入力されたIndexの値のコピーを作成するかどうか指定します。 |
name |
object | (省略可能)初期値 None オブジェクトに名前をつけます。 |
次はDatetimeIndexです。日付データをIndexにする際に使われるオブジェクトになります。
class pandas.DatetimeIndex
| 引数名 | 型 | 概要 |
|---|---|---|
data |
1次元配列に相当するオブジェクト | (省略可能) datetimeに変換したいデータを入力します。 |
copy |
bool値 | 入力されたデータのコピーを作るかどうか指定します。 |
freq |
文字列(string) またはpandasのoffsetオブジェクト |
Indexの間隔。 |
start |
datetimeに変換できるもの | ラベルを付け始める日時を指定します。 |
periods |
int (0より大きい整数) |
いくつのラベルを作成するか指定します。 |
end |
datetimeに変換できるもの | 終点を指定します。 |
closed |
‘left’,’right’ もしくはNone |
初期値 None 時間間隔のどちら側を範囲として含むかを指定します。Noneのときはどちらも含みます。 |
tz |
pytz.timezoneまたは dateutil.tz.tzfile |
使用するタイムゾーンを指定します。 |
ambiguous |
‘infer’,bool値の配列,’NaT’,’raise’ | 初期値 raise サマータイムによる時刻列の飛びをどう処理するかを指定します。’infer’のときは時刻列のデータからサマータイム開始時期を推定します。bool値の配列のときはTrueのときがサマータイムでFalseのときが通常です。 NaTは曖昧なところに対して全てNaTを返します。raiseは曖昧なところについてはErrorを返します。 |
name |
object | (省略可能)初期値 None オブジェクトに名前をつけます。 |
dayfirst |
bool値 | 初期値 False Trueのときは時刻データを処理するときに日にちが先にくる順序で処理します。 |
yearfirst |
bool値 | 初期値 False Trueのときは時刻データを処理するときに年が先にくる順序で処理します。 |
まだまだ他にもIndexオブジェクトは存在しますが特殊なIndexを作成したいときは是非調べて使ってみてください。
まとめ
今回はIndexオブジェクトについての基本とその簡単な使い方について紹介しました。これでIndexの操作について戸惑うことはぐっと減ったはずです。
ここでは簡単な使い方の紹介に留まっていますので、詳細な使い方についてはまた別途に他の記事で解説する予定です。
参考
- pandas.index -pandas-0.23.1-documentation
- pandas.DataFrame.stack – pandas 0.23.1 documentation
- Python for Data Analysis 2nd edition –Wes McKinney(書籍)
- pandas.DataFrame.rename – pandas 0.23.1 documentation
- pandas.DataFrame.reindex – pandas 0.23.1 documentation