
Pandasにはデータ同士を結合するための関数も豊富に揃っています。そのため、少しわかりにくくなっている部分があるのも事実です。結合操作を自在に使いこなすことができるようになれば、分析作業も楽になるはずです。
そこで本記事では
- 結合の仕方の違い(left, right, outer, inner)
- 2つのDataFrameを横方向に結合するmerge関数の使い方
について解説していきます。
結合の仕方の違い
それぞれの使い方の解説に入る前に、主にmerge関数で使われる引数howのオプションについて解説します。
SQLを扱ったことのある人にはINNER JOINやLEFT JOINなど結合時に使用する場面が多いので馴染みのあるワードですが、Pandasでも2つのデータを結合するとき、結合の基準となるキーをどの範囲まで使うかを指定することができます。
例えば、innerを使用すると両方のデータに存在するキーのみで構成されます。outerではどちらか片方に存在するキーも使われます。
結合されるDataFrameは左側にあると考えられているので、leftを使用すると結合される側のDataFrameのキーが全て使われます。rightを使用すると結合する側のDataFrameのキーが全て使われます。
これを図に表すと以下のようになります。
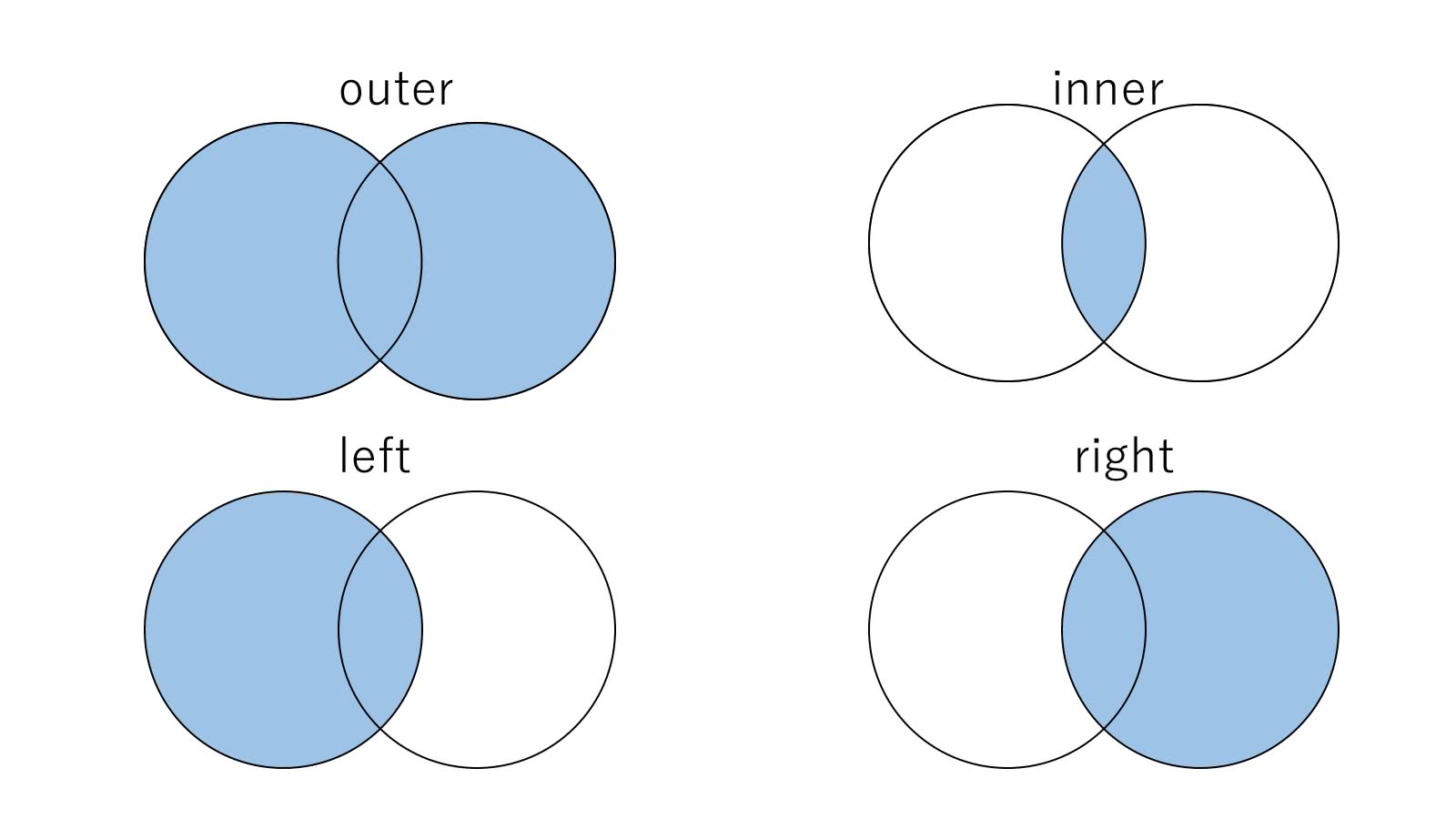
このタイプの違いを念頭に置きつつ1つ1つの関数の使い方を見ていきます。
2つのDataFrameを横方向に結合するmerge関数
merge関数は元のDataFrameから1つのDataFrameを新たに指定して横方向に結合する関数です。結合のイメージとしては左側にあるものを右側から連結するというものです。
APIドキュメント
まずはAPIドキュメントからみてみましょう。サンプルコードで引数全てを扱うわけではないですが、使わないものも掲載しておきます。
pandas.merge(left, right, how=’inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
params:
| パラメータ名 | 型 | 概要 |
|---|---|---|
| left | DataFrame | 左側から結合するDataFrameを指定します。 |
| right | DataFrame | 右側から結合するDataFrameを指定します。 |
| how | ‘left’,’right’, ‘outer’,’inner’ のいずれか |
(省略可能)初期値’inner’ 結合の際、どの範囲のデータを使うかを指定します。 |
| on | ラベル名もしくはそのリスト | (省略可能)初期値None 結合する際に使用するキーとなるデータを指定します。 |
| left_on | ラベル名もしくはそのリスト | (省略可能)初期値None 左側から結合するDataFrameで使用するキーを指定します。 |
| right_on | ラベル名もしくはそのリスト | (省略可能)初期値None 右側から結合するDataFrameで使用するキーを指定します。 |
| left_index | bool値 | (省略可能)初期値False 結合する際に使用するキーとして左側データのインデックスラベルを使用するかどうかを指定します。 |
| right_index | bool値 | (省略可能)初期値False 結合する際に使用するキーとして右側データのインデックスラベルを使用するかどうかを指定します。 |
| sort | bool値 | (省略可能)初期値False 結合する際に使用したキーの列データをソートするかどうかを指定します。 |
| suffixes | 長さ2のタプルもしくはリスト (シーケンス) |
(省略可能)初期値None カラムラベルで被りが生じたとき、各々のラベル名の後ろに付け加える文字列を指定します。 |
| copy | bool値 | (省略可能)初期値True Falseのとき、不必要にコピーを作成しません。 |
| indicator | bool値,もしくはstr | (省略可能)初期値False Trueの時、’_merge’という名のついた新たな列データが加えられ、両方のデータが使われたときは’both’、左データのみの時は’left’、右データのみの時は’right’と表示されます。ラベルの名称を指定することも可能です。 |
| validate | ‘one_to_one’,’one_to_many’ ‘many_to_one’,’many_to_many’ のいずれか |
(省略可能)初期値None それぞれ指定したタイプをキーとなる列データが満たしているかどうか確認します。 ‘one_to_one’ : キーとなる列データがどちらにおいても被りのない値であるかどうかをチェックします。 ‘one_to_many’ : 左データのキーとなる列データに被りがないかどうかをチェックします。 ‘many_to_one’ : 右データのキーとなる列データに被りがないかどうかをチェックします。 ‘many_to_many’ : 指定しても特に意味はありません。 |
returns:
結合されたDataFrameが返されます。
基本的な使い方
以下のデータを用意します。
In [1]: import pandas as pd
In [2]: df1 = pd.DataFrame({
...: "data1" : range(6),
...: "key" : ['A', 'B', 'B', 'A', 'C', 'A' ]
...: })
...:
In [3]: df2 = pd.DataFrame({
...: "data2" : range(2),
...: "key" : ['A', 'B']
...: })
...:
これらを結合します。
In [4]: pd.merge(df1, df2)
Out[4]:
data1 key data2
0 0 A 0
1 3 A 0
2 5 A 0
3 1 B 1
4 2 B 1
In [5]: df1.merge(df2) # DataFrame.mege()の形式でも適用できる
Out[5]:
data1 key data2
0 0 A 0
1 3 A 0
2 5 A 0
3 1 B 1
4 2 B 1
デフォルトでmerge関数は共通のラベルを持つ列データを元に データを結合する関数となっています。上の例ではkey列を元に2つのDataFrameを結合しています。また、結合の仕方(how引数)がinnerなので2つのDataFrameに存在する'A', 'B'の2つの値だけしか反映されていません。
結合の仕方を変更する
今度はhow引数の値を変更して、結合を基準とするキーのどれを使うかを指定します。inner(デフォルト)、outer、left、rightがあり、これらの違いは先ほど解説しました。
では、実際に使っていきます。
In [6]: df3 = pd.DataFrame({
...: "data1" : range(6),
...: "key" : ['A', 'B', 'C', 'A', 'B', 'C']
...: })
In [7]: df4 = pd.DataFrame({
...: "data2" : range(3),
...: "key" : ['A', 'C', 'D']
...: })
In [8]: df3
Out[8]:
data1 key
0 0 A
1 1 B
2 2 C
3 3 A
4 4 B
5 5 C
In [9]: df4
Out[9]:
data2 key
0 0 A
1 1 C
2 2 D
デフォルトではinnerになっているのでdf3, df4に共通のA,Cのみが使われます。
In [10]: pd.merge(df3, df4, how='inner') # デフォルト A, Cのみ
Out[10]:
data1 key data2
0 0 A 0
1 3 A 0
2 2 C 1
3 5 C 1
outerにするとdf3,df4のどちらか一方でも使われていればキーとして使われるのでA,B,C,D全てが使われます。
In [11]: pd.merge(df3, df4, how='outer') # A, B, C, D全部
Out[11]:
data1 key data2
0 0.0 A 0.0
1 3.0 A 0.0
2 1.0 B NaN
3 4.0 B NaN
4 2.0 C 1.0
5 5.0 C 1.0
6 NaN D 2.0
次にleftにすると最初に指定したdf3で使われているキーに合わせられます。
In [12]: pd.merge(df3, df4, how='left') # df3で使われてるA,B,C
Out[12]:
data1 key data2
0 0 A 0.0
1 1 B NaN
2 2 C 1.0
3 3 A 0.0
4 4 B NaN
5 5 C 1.0
rightにすると2番目に指定されたdf4で使われるキーを使います。
In [13]: pd.merge(df3, df4, how='right') # df4で使われているA, C, D
Out[13]:
data1 key data2
0 0.0 A 0
1 3.0 A 0
2 2.0 C 1
3 5.0 C 1
4 NaN D 2
結合を基準にするデータを指定する
onもしくはleft_onとright_onで結合に使用するキーとなるデータを指定することが可能です。
onを使うときはどちらも共通したラベルのデータが存在する場合で、left_onとright_onを使うのは共通したラベルを持っていない場合に使います。
まずはonから使っていきます。
In [14]: df5 = pd.DataFrame({
...: "data1": range(6),
...: "key1" : ['A', 'B', 'A', 'B', 'A', 'B'],
...: "key2" : [0 , 0, 0, 1, 1, 1] }
...: )
In [15]: df6 = pd.DataFrame({
...: "data2": range(3),
...: "key1" : ['A', 'A', 'B'],
...: "key2" : [ 1, 1, 0]})
...:
In [16]: pd.merge(df5, df6, on="key1") # key1列を使う
Out[16]:
data1 key1 key2_x data2 key2_y
0 0 A 0 0 1
1 0 A 0 1 1
2 2 A 0 0 1
3 2 A 0 1 1
4 4 A 1 0 1
5 4 A 1 1 1
6 1 B 0 2 0
7 3 B 1 2 0
8 5 B 1 2 0
In [17]: pd.merge(df5, df6, on="key2") # key2列を使う
Out[17]:
data1 key1_x key2 data2 key1_y
0 0 A 0 2 B
1 1 B 0 2 B
2 2 A 0 2 B
3 3 B 1 0 A
4 3 B 1 1 A
5 4 A 1 0 A
6 4 A 1 1 A
7 5 B 1 0 A
8 5 B 1 1 A
このようにonで指定しない列で名前に被りがあるものについてはデフォルトでx, yが後ろにつけられています。
suffixes引数で変更ができるのであとで扱います。
onでインデックスラベルを指定することも可能です。
インデックスに名称をつける必要があります。
インデックスに列データを指定してもう一度結合して見ます。
In [19]: df5_2 = df5.set_index(['key1']) # key1列をインデックスラベルに
In [20]: df6_2 = df6.set_index(['key1']) # key1列をインデックスラベルに
In [21]: df5_2
Out[21]:
data1 key2
key1
A 0 0
B 1 0
A 2 0
B 3 1
A 4 1
B 5 1
In [22]: df6_2
Out[22]:
data2 key2
key1
A 0 1
A 1 1
B 2 0
In [23]: pd.merge(df5_2, df6_2, on="key1")
Out[23]:
data1 key2_x data2 key2_y
key1
A 0 0 0 1
A 0 0 1 1
A 2 0 0 1
A 2 0 1 1
A 4 1 0 1
A 4 1 1 1
B 1 0 2 0
B 3 1 2 0
B 5 1 2 0
left_index=True、right_index=Trueにしてもインデックス同士の結合は可能です。
この場合、上から3つずつのデータ同士が結合されます。
In [33]: pd.merge(df5, df6, left_index=True, right_index=True)
Out[33]:
data1 lkey1 lkey2 data2 rkey1 rkey2
0 0 A 0 0 A 1
1 1 B 0 1 A 1
2 2 A 0 2 B 0
キーに複数指定することも可能です。
In [24]: pd.merge(df5, df6, on=['key1', 'key2'])
Out[24]:
data1 key1 key2 data2
0 1 B 0 2
1 4 A 1 0
2 4 A 1 1
次はキーとなる列データのラベルが異なる場合です。
left_onとright_onで変更できます。
left_onに左側のDataFrameのラベルを、right_onに右側のDataFrameのラベルを指定します。
In [25]: df5.columns = ['data1', 'lkey1', 'lkey2'] # 列データのラベルを変更
In [26]: df6.columns = ['data2', 'rkey1', 'rkey2']
In [27]: df5
Out[27]:
data1 lkey1 lkey2
0 0 A 0
1 1 B 0
2 2 A 0
3 3 B 1
4 4 A 1
5 5 B 1
In [28]: df6
Out[28]:
data2 rkey1 rkey2
0 0 A 1
1 1 A 1
2 2 B 0
In [29]: pd.merge(df5, df6, left_on="lkey1", right_on="rkey1")
Out[29]:
data1 lkey1 lkey2 data2 rkey1 rkey2
0 0 A 0 0 A 1
1 0 A 0 1 A 1
2 2 A 0 0 A 1
3 2 A 0 1 A 1
4 4 A 1 0 A 1
5 4 A 1 1 A 1
6 1 B 0 2 B 0
7 3 B 1 2 B 0
8 5 B 1 2 B 0
In [31]: pd.merge(df5, df6, left_on=["lkey1", 'lkey2'], right_on=["rkey1", "rkey2"])
Out[31]:
data1 lkey1 lkey2 data2 rkey1 rkey2
0 1 B 0 2 B 0
1 4 A 1 0 A 1
2 4 A 1 1 A 1
被りのあるラベルに添え字をつける
次は被りのあるラベルに添え字をつける方法です。
suffixes引数で指定できます。
この場合、2つとも指定する必要があることに注意してください。
suffixes = [ 左データのラベルに付け足す文字列, 右データのラベルに付け足す文字列]のように指定します。
In [38]: df7 = pd.DataFrame({
...: "data1" : range(6),
...: "key1" : ['A', 'B', 'A', 'B', 'A', 'B'],
...: "key2" : [0, 0, 0, 1, 1, 1] })
...:
In [39]: df8 = pd.DataFrame({
...: "data1" : range(3),
...: "key1" : ['A', 'A', 'B'],
...: "key2" : [1, 1, 0] })
...:
In [41]: pd.merge(df7, df8, suffixes = ["_left", "_right"], on="key1")
Out[41]:
data1_left key1 key2_left data1_right key2_right
0 0 A 0 0 1
1 0 A 0 1 1
2 2 A 0 0 1
3 2 A 0 1 1
4 4 A 1 0 1
5 4 A 1 1 1
6 1 B 0 2 0
7 3 B 1 2 0
8 5 B 1 2 0
まとめ
今回はDataFrameを結合する関数の中でもよく使われる関数であるmerge関数の使い方について解説しました。
他にも結合に関する関数は存在しますが、横方向の結合においてはmerge関数が最も使われている関数となっていますのでぜひ使い方をマスターしましょう。
参考
- Python for Data Analysis 2nd edition –Wes McKinney(書籍)
- pandas.merge - pandas 0.23.4 documentation