データ分析を行う上で押さえておくべき「Jupyter Notebook」について解説します。
本記事では以下の事項について取り上げます。
-
Jupyter Notebookとは
-
Jupyter Notebookの強みと機能
-
Jupyter Notebook上で実際にタスクを実行する
Jupyter Notebookとは
Notebookとは
Notebookはブラウザで動作するプログラムの対話型実行環境です。 ノートブックと呼ばれるドキュメントを作成し、プログラムの記述と実行、メモの作成、保存と共有などをブラウザ上で行うことができます。
これはプログラミングを伴う作業の中でも特に結果の保存や共有に重きを置くタスクに有用です。
Jupyter Notebookの誕生
Jupyter Notebookの前身は、IPython NotebookというPython専用のNotebookです。
このIPython Notebookの利便性に注目した他言語のユーザがそれぞれの言語への移植を行いました。 そして多言語に対応したNotebook形式のWebアプリケーションとなりました。 対応している主要な言語(Julia + Python + R)からJupyterと名付けられました。
現在(2016年12月時点)ではPython、Julia、R、Ruby、Haskell、Scala、node.js、Go、Luaなどの言語に対応しています。
Jupyter Notebookの導入
導入にはPythonの環境が必要です。 3系であれば3.3以上、2系であれば2.7の環境で動作します。
Jupyter Notebookの環境を構築するにはAnacondaの導入が推奨されています。 Anacondaはデータ分析に適したパッケージや便利な機能を有したデータサイエンスプラットフォームです。
Macでhomebrewを利用している場合、以下のように導入できます。
$ brew install pyenv
...
$ pyenv install anaconda3-4.0.0
...
Jupyter NotebookはAnacondaに標準のパッケージとして組み込まれています。 作業用フォルダに移動し以下のように実行するとJupyter Notebookが起動します。
$ pyenv local anaconda3-4.0.0
$ jupyter notebook
localhost環境(デフォルトのポートは8888)にて以下のような画面が表示されれば成功です。 右上のNewから新しくNotebookを作成することができます。
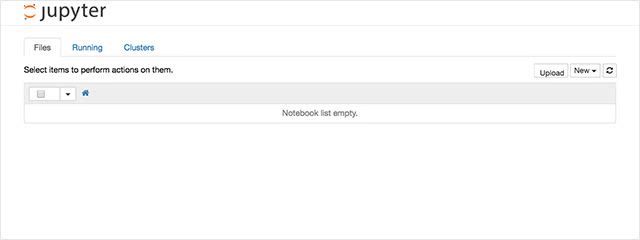
以上で導入は完了です (Python以外の言語を利用したい場合は、ここから言語ごとのカーネルを別途追加する必要があります)。
Jupyter Notebookの強みと機能
プログラムの保存・共有・再現
Jupyter Notebookはプログラムの保存・共有・再現を最も得意としています。
プログラムの保存は「プログラムと関連するメモや出力をひとまとめに保存する」ことを指します。 プログラムの共有は「プログラムとコメント、整形された出力を対応付けた形で共有する」ことを指します。 プログラムの再現は「作成・共有したプログラムと関連する情報から、同じプロセスを再現する」ことを指します。
この保存・共有・再現を実現するために、以下のような特徴的な機能があります。
-
セルコーディング
-
インタラクティブなデータの可視化
-
セルの改変と再実行
-
Notebookの共有
以下、サンプルコードはPython3系を用いて示します。
セルコーディング
Notebookではプログラムやメモはすべてセルと呼ばれる単位で記述します。 このセルコーディングはNotebookの最大の特徴です。
プログラムならば「Code」、マークダウンメモならば「Markdown」といった具合にセルのタイプを選択することができます。
これらのセルは+ボタン(もしくは)で追加し、▶︎|ボタン(もしくはShift+Enter)で実行します。
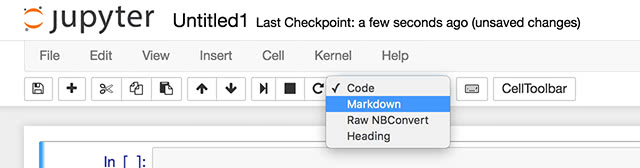
Codeセルの記述
Codeセルではプログラムを記述し、実行することができます。 セルを選択し記述されたプログラムを実行します。
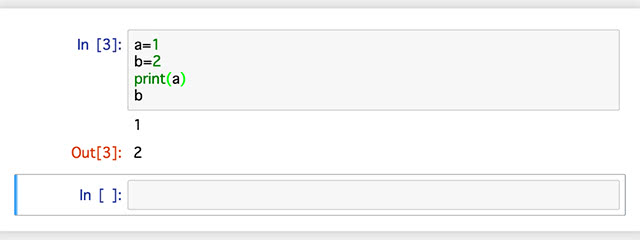
最後に実行された行が値ならばOut[n]として出力されます。 また、print文などの出力関数もnotebook上に表示されます。
Markdownセルの記述
Markdownセルではマークダウン形式でメモを記載することができます。 セルを実行すると記述したメモが整形されます。
入力例
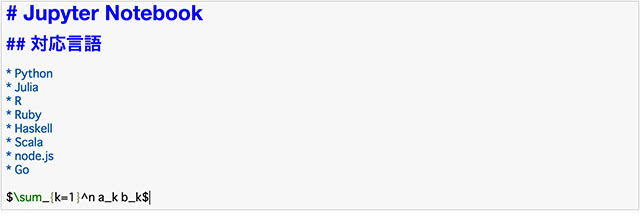
出力例

通常のプログラミングにおけるメモはソースコードの前後にテキストを記述するのが一般的です。 マークダウンメモであればリストやテーブルはもちろん、図やリンクなども追加することができます。 MathJaxもサポートされており数式の記述を行うことができます。
このように、プログラムの説明に豊かな表現力を持たせることができます。
インタラクティブなデータの可視化
Notebookでは各言語のライブラリを利用して、プログラムの出力結果を様々な形で表現することができます。 結果をリアルタイムでNotebook上に出力することができます。
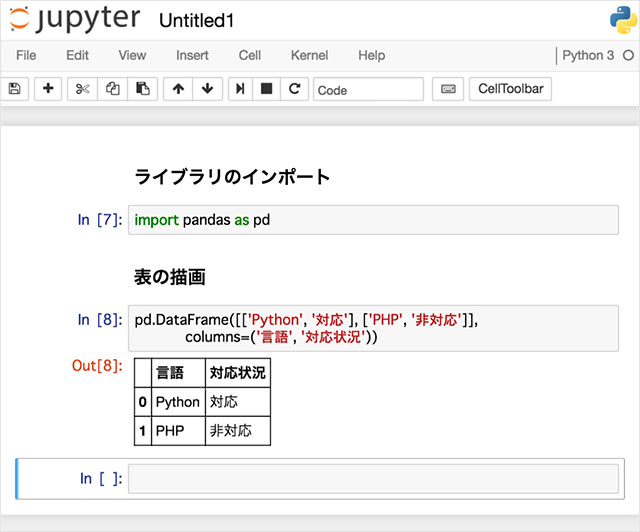
表の描画
表形式を扱うライブラリ等を用いることで、Notebook上に表を出力することができます。 表形式のデータ配列を扱うための「pandas」ライブラリを利用すると、以下のような出力が得られます。
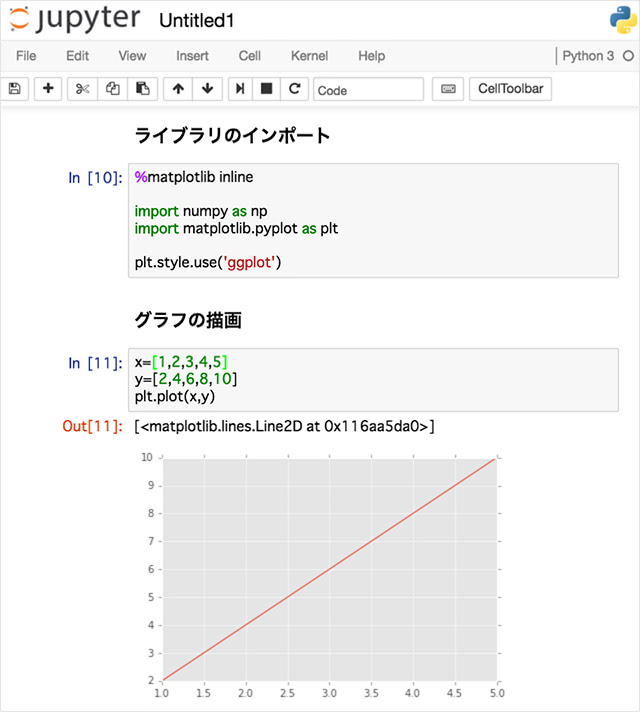
グラフの描画
グラフ描画のためのライブラリ等を用いることで、Notebook上にグラフを出力することができます。 「matplotlib」ライブラリを利用すると、以下のような出力が得られます。
matplotlibのグラフをNotebook上に記述する際には%matplotlib inlineと追加する必要がある点に注意です。
このような%で始まる記法はmagic commandsというJupyterやIPythonの独自記法です。
セルの改変と再実行
セル単位でプログラムやメモを記述し、ライブラリと連携することで可視化できることを説明してきました。 これらすべてのセルは途中から自由に追加・編集・再実行することができます。
例えば一度実行したプログラムに関して、出力データを別のグラフで表示したい場合を考えます。 Notebookならば目的のグラフ描画を行うセルを作成し、 そこにプログラムを記述・実行するだけで簡単に確認することができます。
また、異なるデータを表にしてみたい場合は、別のデータを取得するセルを作成し実行します。 そのデータを用いて同様のグラフ描画を行うセルの参照データを変更すれば、簡単に確認することができます。
このようにセルは再利用できるため、別なセルに差し替えたり、また差し替えたセルを元に戻すことも非常に容易です。
Notebookの共有
作成したNotebookはFile > Download asから様々なファイル形式で保存できます。
その中にはNotebook独自の.ipynbという形式が存在します。
.ipynb
.ipynbで保存したNotebookを共有すれば、Jupyter Notebookの環境がある者であれば誰でも自分の環境下で同様のプログラムを再現することができます。
また、この形式はGithub上でも閲覧することができます。 環境がないユーザであっても、プログラムと対応付けられたコメントや出力をブラウザ上で閲覧することができます。
スライドによる共有
対面で大人数に情報を共有する手段としてはプレゼンテーションスライドが一般的です。 Jupyter Notebookでは、プレゼン形式でNotebookを表示することができます。
View > Cell Toolber > Slideshowからスライドの構成を設定することができます。
また、RIZEという拡張機能をインストールすることによって、編集中であってもスライドのプレビューができるようになります。 RIZEを導入すると、下図のようにスライドのプレビューボタンが追加されます。
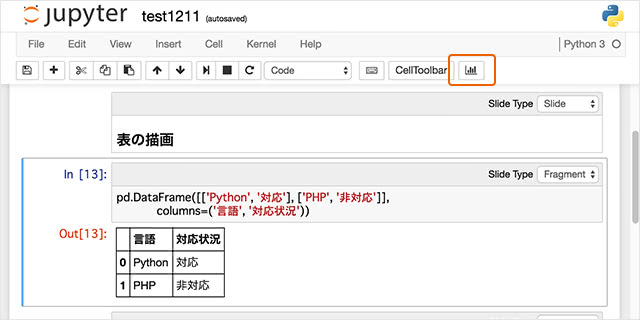
表示は以下のようになります。
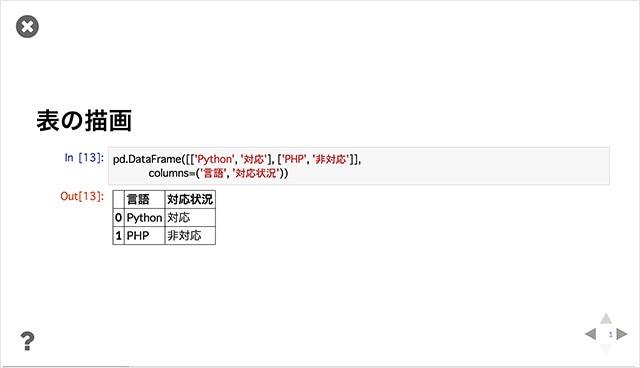
残念ながらPowerPointのようなリッチなスライドは作成できませんが、結果の共有には十分だと考えられます。
その他拡張機能
前述のRIZEのような、Jupyterの拡張機能はextentionと呼ばれ、他にも多く存在します。
Jupyter notebook extensions
Jupyter notebook extensionsはJupyter NotebookのWebアプリケーション上からextensionのON/OFFが設定できる拡張機能です。
導入すると、以下のようにトップにNbextensionsというタブが追加されます。
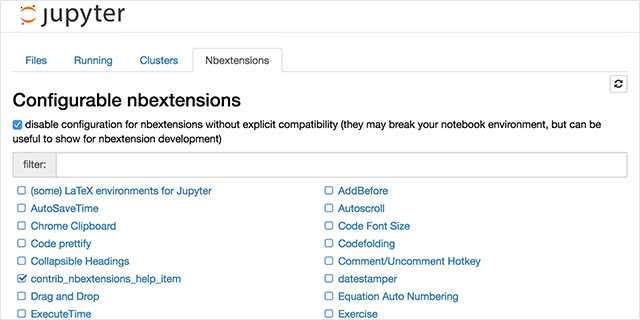
ここからextenstionを設定することができます。
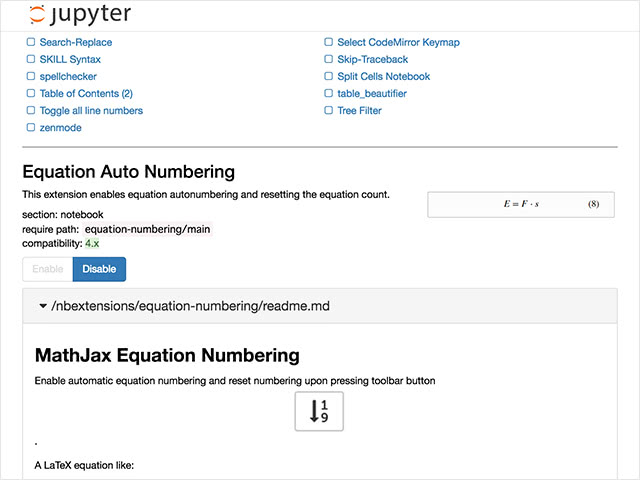
extensionを選択すると、下にGithubリポジトリのreadme.mdが表示されます。 それぞれの機能をいちいち調べずとも、ここでそれぞれのextensionの仕様を確認できます。
データ分析とJupyter Notebook
前述のJupyter Notebookが得意とする結果の保存や共有に重きを置くタスクの代表としてデータ分析が挙げられます。
データ分析ではその結果に至るまでの思考プロセスがしばしば重要視されます。 これらはプログラムから全て読み取ることは不可能ですが、プログラムと密接な関連があります。 Jupyter Notebookのようにプログラムと意図を記述するためのメモが対応した形で閲覧できるのは非常に便利です。
また、プログラムの意図を理解した上で他者が再現できることも非常に重要です。 手順書のような形でセル単位で記述されたNotebookは逐次的に追いやすく、作成者でなくとも変更や修正を加えることが容易であると言えます。
以上よりJupyter Notebookはデータ分析のニーズを十分に満たすことができるアプリケーションであると期待できます。 このJupyter Notebookを用いて分類タスクを実践していきます。
Jupyter NotebookでChainerを利用する
ChainerはPreferred Networksが開発しているディープラーニング用のライブラリです。 こちらを用いて、MNISTと呼ばれる分類タスクをJupyter Notebookを用いて実践していきます。
ChainerのMNIST利用例を参考に進めていきます。
実行環境
-
MacOSX10.11.6
-
Python3.5.1
-
chainer1.1.8
Chainerの導入
Chainer含む必要なライブラリ群をimportします。 新しくセルを作成し以下を記述します。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import json
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import training
from chainer import optimizers
from chainer.training import extensions
import sys
plt.style.use('ggplot')データセットの読み込み
ChainerではMNISTようのデータセットを簡単にダウンロードすることができます。 新しいセルに以下を記述し実行します。
train, test = chainer.datasets.get_mnist()このMNISTは0~9の手書き文字の画像をを分類するタスクです。 画像は784次元のベクトルデータで表されています。
これを28*28のメッシュ状にプロットしていくつか画像を確認してみます。
def draw_digit(data,n):
size = 28
plt.subplot(10,10,n)
X, Y = np.meshgrid(range(size),range(size))
Z = np.reshape(data,(size,size))
Z = Z[::-1,:]
plt.xlim(0,size-1)
plt.ylim(0,size-1)
plt.pcolor(X, Y, Z)
plt.gray()
plt.tick_params(labelbottom="off")
plt.tick_params(labelleft="off")
plt.figure(figsize=(16,16))
cnt = 1
for i in np.random.permutation(len(train))[:50]:
draw_digit(train[i][0],cnt)
cnt+=1
plt.show()これを実行すると、以下のような出力が得られます。

確かに手書き文字のような画像が確認できました。
パラメータとモデルの設定
タスクの実行に当たって、パラメータの設定とニューラルネットのモデルクラスを実装します。 今回は中間層を100として一般的な3層パーセプトロンを用いてタスクを行います。
batchsize = 100
epoch = 20
units = 1000
gpu = -1 # GPUを使わない
choises = 10class MnistModel(chainer.Chain):
def __init__(self, n_units, n_out):
super(MnistModel, self).__init__(
l1=L.Linear(None, n_units),
l2=L.Linear(None, n_units),
l3=L.Linear(None, n_out),
)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)モデルのインスタンスを生成し、Optimizerをセットアップします。 これで準備は完了です。
model = L.Classifier(MnistModel(units,choises))
optimizer = optimizers.Adam()
optimizer.setup(model)学習
実際に学習を進めていきます。 学習データとテストデータのイテレータを作成します。 また、トレーニングのためのTrainerインスタンスを生成し、実行します。
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize,repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=gpu)
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
trainer.extend(extensions.Evaluator(test_iter, model, device=gpu))
trainer.extend(extensions.snapshot(), trigger=(epoch, 'epoch'))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'validation/main/loss','main/accuracy', 'validation/main/accuracy']))
trainer.run()以下のように出力で実行中のタスクを確認することができます。
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy
1 0.191573 0.095149 0.942017 0.97
2 0.0745474 0.114737 0.9766 0.9632
3 0.0487195 0.0722675 0.98475 0.979
4 0.0348205 0.0812639 0.9884 0.9779
5 0.0278007 0.0844082 0.991017 0.978
6 0.0262619 0.0873578 0.991233 0.9777
7 0.0215357 0.0728297 0.993117 0.9798
8 0.0175074 0.077078 0.9944 0.9815
9 0.0183737 0.0767149 0.9942 0.9808
10 0.0121802 0.0820749 0.9963 0.9814
11 0.0155267 0.0863105 0.995233 0.9812
12 0.010957 0.105772 0.9965 0.9776
13 0.0163032 0.0764009 0.99505 0.983
14 0.00811828 0.0801101 0.997433 0.9837
15 0.00884081 0.129957 0.9977 0.9749
16 0.0133256 0.0955115 0.995933 0.9827
17 0.00900266 0.0903585 0.997467 0.9838
18 0.00902313 0.110663 0.997267 0.9795
19 0.00920691 0.122643 0.996933 0.976
20 0.00787913 0.096199 0.997833 0.9816
結果の可視化
タスクが完了したので、ログデータを可視化してみます。
trainer.extend(extensions.LogReport())によって/result/logにログデータがJSON形式で保存されているので、
そちらを利用していきます。
with open('result/log') as data_file:
data = json.load(data_file)
plt.figure(figsize=(16,16))
plt.subplot(2,2,1)
plt.plot(range(len(data)), [d['main/accuracy'] for d in data])
plt.title("Accuracy of train data.")
plt.subplot(2,2,2)
plt.plot(range(len(data)), [d['validation/main/accuracy'] for d in data])
plt.title("Accuracy of test data.")
plt.subplot(2,2,3)
plt.plot(range(len(data)), [d['main/loss'] for d in data])
plt.title("Loss of train data.")
plt.subplot(2,2,4)
plt.plot(range(len(data)), [d['validation/main/loss'] for d in data])
plt.title("Loss of test data.")
plt.show()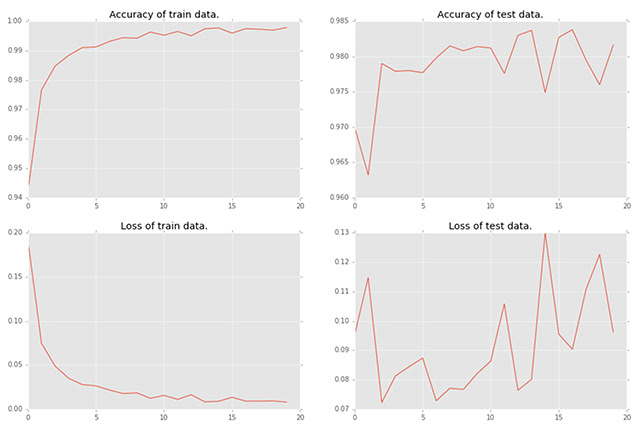
学習の過程を表示することができました。 このようにJuputer Notebookでは簡単に記録・共有・再現を行うことができます。
おわりに
Jupyter Notebookのこれから
Jupyter Notebookは現在Project Jupyterとして規模を拡大しています。 その中で注目すべきはJupyter Notebookの後継と思われるJupyter Labです。
Jupyter Notebookとの決定的な差はIDEであるという点です。 こちらもデータ分析において非常に有用であると思われます。
まとめ
-
Jupyter Notebookはブラウザで利用可能な対話型の実行環境である。
-
セルコーディング・可視化・再実行・共有機能によってプログラムの「保存・共有・再現」を容易にしている。
-
「保存・共有・再現」の利便性からデータ分析と非常に相性が良い。
データ分析に関わる方、関心のある方は是非Jupyter Notebookを利用してみてはいかがでしょうか。