シンプルでありながら、Deep Learningにおいて必須ツールとなったBatch Normalizationはとても強力な手法だ。Batch Normalizationは他の開発者や研究者からも評判が高く
には
一番効いてきているのがBatch NormalizationとAdamでした.これ入れないとそもそもノイズしか出てきません.個人的な印象だと,DCGANの一番の貢献はBNを入れたことだと思います.それ位違いがある. だとすれば,例えばDAEやVAE等の別のモデルでも,上手く行かなかったのは単なるBNの不在である可能性がある.だとすれば,BN入れれば今まで全然できなかった問題に対しても上手くいく可能性があるかと
と書いてあり、Batch Normalizationを適用することでノイズしか出てこなかったものがうまくいくようになったと書かれてある。
この記事では、Batch Normalizationを紹介し、どれほどの効果があるのかを検証する。
Batch Normalizationとは何か
Batch Normalizationは2015年にSergey IoffeとChristian Szegedyが提案した手法で原論文はこちらである。
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
基本的には、勾配消失・爆発を防ぐための手法であり、これまでは
- 活性化関数を変更する(ReLUなど)
- ネットワークの重みの初期値を事前学習する
- 学習係数を下げる
- ネットワークの自由度を制約する(Dropoutなど)
などで対処してきた。Batch Normalizationはこれまでとは違い、ネットワークの学習プロセスを全体的に安定化させて学習速度を高めることに成功している。
内部の共変量シフト
共変量シフトとは、入力の分布が異なる現象を意味するが、機械学習やパターン認識の分野では訓練データのサンプリングと予測データの入力の分布に偏りがあり、アルゴリズムが対応できなくなることを指すことが多い。
単なる訓練データセットの中で、共変量シフトは普通の機械学習アルゴリズムではあまり議論されない。Deep Networkでは、深くなった隠れ層において各層とActivationごとに入力分布が変わってしまうことが問題となる。この現象を内部の共変量シフト(Internal Covariate Shift)と呼んでいる。
白色化(whitening)と呼ばれる入力の平均を0にして、標準偏差を1に、そして特徴成分を非相関にする手法をとると、ニューラルネットワークの収束速度が速くなることが知られている。
これまでも、データの前処理においてNormalizationやStandardizationといった方法をとってきたが、データセットだけ白色化されていても、ネットワーク内部で分散が偏る。 よく知られることとして、データの分散が偏っている場合、一次情報のみの勾配法だと収束速度が遅くなるので、白色化をすることによってInternal Covariate Shiftを抑制する働きがあるのだろう。
アルゴリズム
まず入力として 個のデータからなるmini-batch
と学習されたパラメータ
があるとする。 mini-batch内での平均と分散を計算する。ただし分散は各要素の二乗を計算する。
これらの値を使い、mini-batchの各要素 を次のように変換する。
この手続きで得られた がBatch Normalizationの出力となる。
Batch Normalizationのメリット
では、Batch Normalizationを利用するメリットは何だろうか?以下のような議論がなされている。
大きな学習係数が使える
これまでのDeep Networkでは、学習係数を上げるとパラメータのscaleの問題によって、勾配消失・爆発することが分かっていた。Batch Normalizationでは、伝播中パラメータのscaleに影響を受けなくなる。結果的に学習係数を上げることができ、学習の収束速度が向上する。
正則化効果がある
原論文にも、
- L2正則化の必要性が下がる
- Dropoutの必要性が下がる
など、これまでの正則化テクニックを不要にできるという議論がなされている。Dropoutは、過学習を抑える働きがあるが学習速度が遅くなり、Dropoutを使わないことで学習速度を向上させることができる。
初期値にそれほど依存しない
ニューラルネットワークの重みの初期値がそれほど性能に影響を与えなくなる。
Batch Normalizationを実装してみよう
それでは、Batch Normalizationを実装してみよう。今回も検証にはTFLearnを使う。
TFLearnのインストール
TensorFlowは事前にインストールしておこう。 Deep LearningフレームワークTFLearnをインストールする。
$ pip install tflearn
CIFAR-10の画像分類で検証
今回はCIFAR-10の画像分類で検証する。このデータセットは8000万枚の画像80 Million Tiny Imagesから60,000枚の画像データセットで画像ごとに10種類にラベル付けされている。

まずはCNNでネットワークを構築
必要なライブラリをインストールする。
from __future__ import division, print_function, absolute_import
import tflearn
from tflearn.data_utils import shuffle, to_categorical
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation次にCIFAR-10のデータセットをダウンロードする。
from tflearn.datasets import cifar10
(X, Y), (X_test, Y_test) = cifar10.load_data()
X, Y = shuffle(X, Y)
Y = to_categorical(Y, 10)
Y_test = to_categorical(Y_test, 10)事前にデータを標準化しておき、Data Augmentationでデータを増やす。
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
img_aug = ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_rotation(max_angle=25.)CNNのネットワークを構築する。CNNとはConvolutional Neural Networkのことで、以下に詳細の解説をしているのでよければ参考にして欲しい。
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='tanh')
network = conv_2d(network, 64, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='tanh')
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='sgd',
loss='categorical_crossentropy',
learning_rate=0.001)
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=50, shuffle=True, validation_set=(X_test, Y_test),
show_metric=True, batch_size=96, run_id='Normal')そして、実行してみよう。
$ python normal.py
TensorBoardを開いて、誤差と正答率を可視化してみる。
$ tensorboard --log_dir=/tmp/tflearn_logs
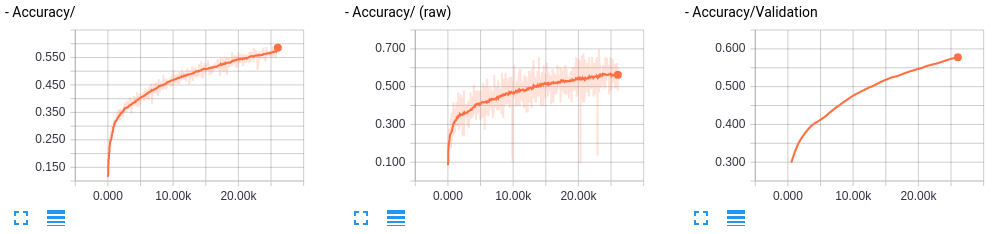
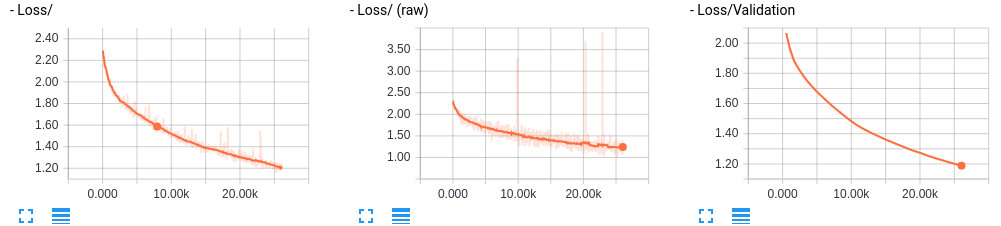
まだ学習できそうだ。本来ならここでepochの数を増やしたりするところだが、Batch Normalizationを適用してみよう。
Batch Normalizationを適用
TFLearnでBatch Normalizationを使うときは、tflearn.layers.normalizationのbatch_normalization関数から利用できる。
ライブラリのimport部分に、
from tflearn.layers.normalization import batch_normalizationを追加し、conv_2dの後と全結合層の後に入れてみる。learning_rateを大きくすることができるので論文と同じように30倍にしてみる。model.fitのrun_idをBatch Normalizationであることが分かる名前にしておこう。
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='tanh')
network = conv_2d(network, 64, 3, activation='tanh')
network = batch_normalization(network)
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='tanh')
network = batch_normalization(network)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='sgd',
loss='categorical_crossentropy',
learning_rate=0.03)$ python batch_norm.py
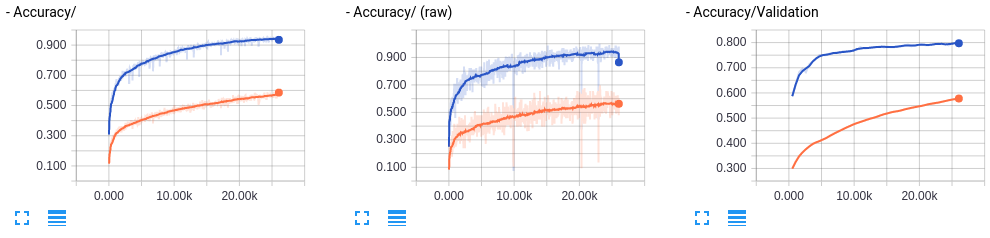
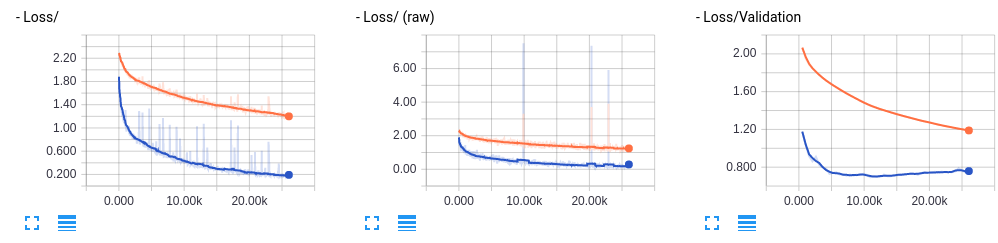
オレンジ色がBN無し、青がBN付きとなっている。
凄い。確かに学習速度が速くなっている。ただ少し訓練データセットのAccuracyの方がValidationよりも大きく、Validation Lossが下がった後にまた上がっていて過学習気味なのでDropoutを追加してみよう。
Dropoutを追加する
今回もmodel.fitのrun_idをDropout付きだと分かるようにしておき、最後のbatch_normalizationをdropoutに変更する。
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='tanh')
network = conv_2d(network, 64, 3, activation='tanh')
network = batch_normalization(network)
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='tanh')
network = dropout(network, 0.8)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='sgd',
loss='categorical_crossentropy',
learning_rate=0.03)実行する。
$ python batch_norm_dropout.py
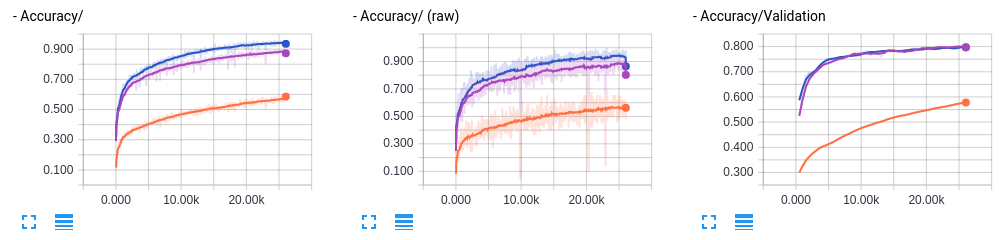
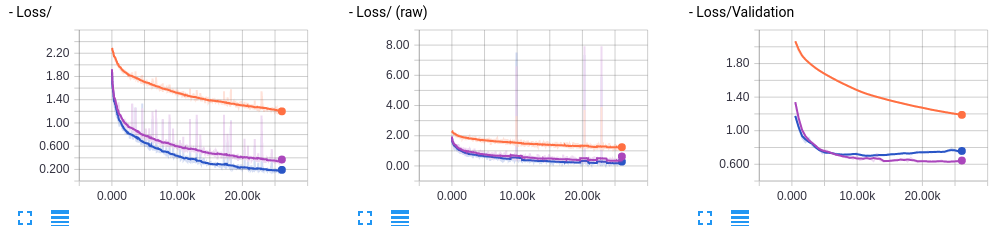
Dropoutを追加したものは紫色で可視化されている。 すると、ある程度過学習が抑えられているようだ。まったく効果がないということでは無さそう。
まとめ
本記事では、勾配消失・爆発を防ぐBatch Normalizationについて紹介した。Batch Normalizationを使うと大きな学習係数が使えて、イテレーションの回数を劇的に減らせる。
また、正則化効果があり、これまでの正則化テクニックをそれほど使わなくても問題無くなっているようだ。
もちろん、しっかりと実験して検証することが大切なので、比較しながら試してみてほしい。