- Convolutional Neural Networkとは何か
- Convolutional Neural Networkの特徴
- Convolutional Neural Networkの構成要素
- TensorFlowによる実装
- 参考
近年、コンピュータビジョンにおける最もイノベーションと言えるのはConvolutional Neural Networkといっても過言ではない。
コンピュータビジョンの業界におけるオリンピックとも言えるコンペティションがImageNetである。 そのコンペティションにおいて、Alex Krizhevskyのチームが2012年に圧勝したニューラルネットワークもこの手法である。 それまで26%だったエラー率を11%も下げることに成功したのだ。
本記事ではそんなConvolutional Neural Networkを基本から紹介し、最後にTensorFlowを使った実装例を紹介する。
この記事を読み終わった頃には、Convolutional Neural Networkが何なのか理解できるはずだ。
Convolutional Neural Networkとは何か
Convolutional Neural Networkは略してCNNと呼ばれる。CNNは一般的な順伝播型のニューラルネットワークとは違い、全結合層だけでなく畳み込み層(Convolution Layer)とプーリング層(Pooling Layer)から構成されるニューラルネットワークのことだ。
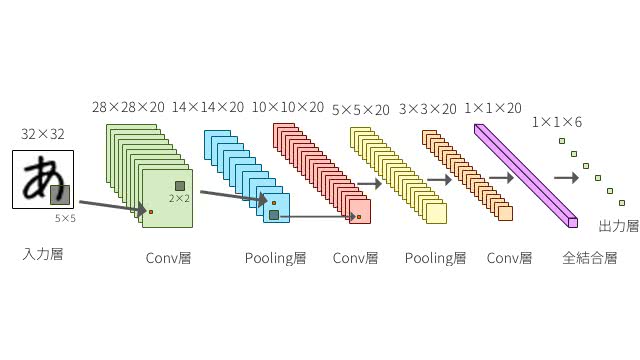
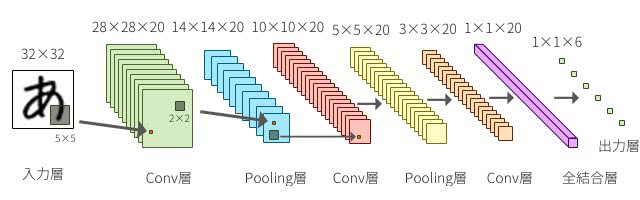
畳み込み層とプーリング層では下図のように入力のニューロンの一部の領域を絞って、局所的に次の層へと対応付けをしていく。各層はフィルタと呼ばれる検出器をいくつも持っているイメージだ。
画像認識の例でいうと、最初の層でエッジを検出して、次の層でテクスチャを検出し、さらに次のそうではより抽象的な猫の耳などの特徴を検出したりする。CNNはこういった特徴を抽出するための検出器であるフィルタのパラメータを自動で学習していくのだ。
CNNで解決できる問題
CNNで解決できる問題は幅広い。実用化されているものだけでもFacebookはタグ付けの顔検出に使い、Googleは写真検索や音声認識に使っている。そして、SpotifyやLINEは自社のレコメンドに利用している。
CNNは元々郵便番号の手書き文字認識のために研究が進んだという経緯もあり、画像認識に使われる事が多い。自然言語処理では、感情分析やテキスト分類、翻訳などにも応用されるようになってきている。
Convolutional Neural Networkの特徴
CNNには注目に値すべき点が3つある。畳み込み(Convolution)と位置不変性 (Translation Invariance) と 合成性 (Compositionality)である。
畳み込みとは
日本語名でConvolutional Neural Networkは畳み込みニューラルネットワークと呼ばれる。畳み込みは行列に対するオペレータとして考えておくと分かりやすい。
例として、グレースケール画像で考えてみよう。画像も以下のように数字で表すと高さ×幅の行列で考えることができる。

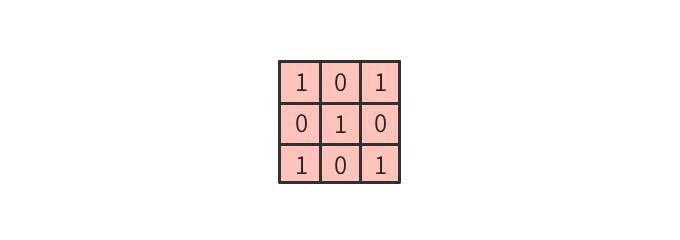
この画像を簡略化して5x5の2値に圧縮する。
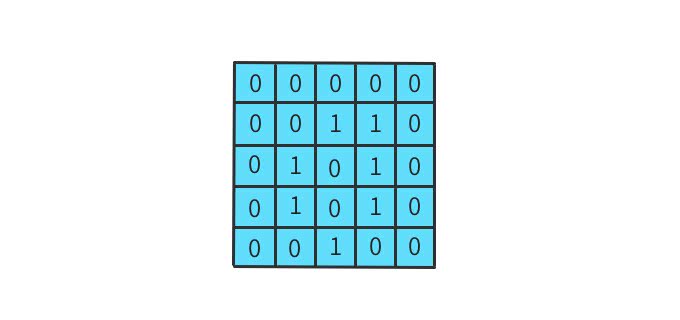
このような行列に以下の3×3のフィルタを適用し畳み込み演算することを考えてみよう。
元の入力画像に対し、左上から右下まで要素ごとに掛け合わせていく。このようにしてフィルタをスライドさせていくことからsliding windowと呼ばれることもある。
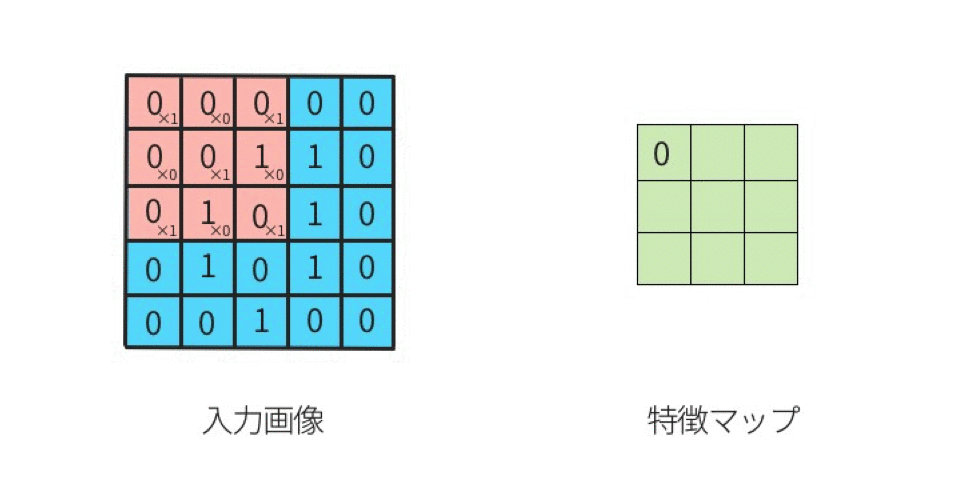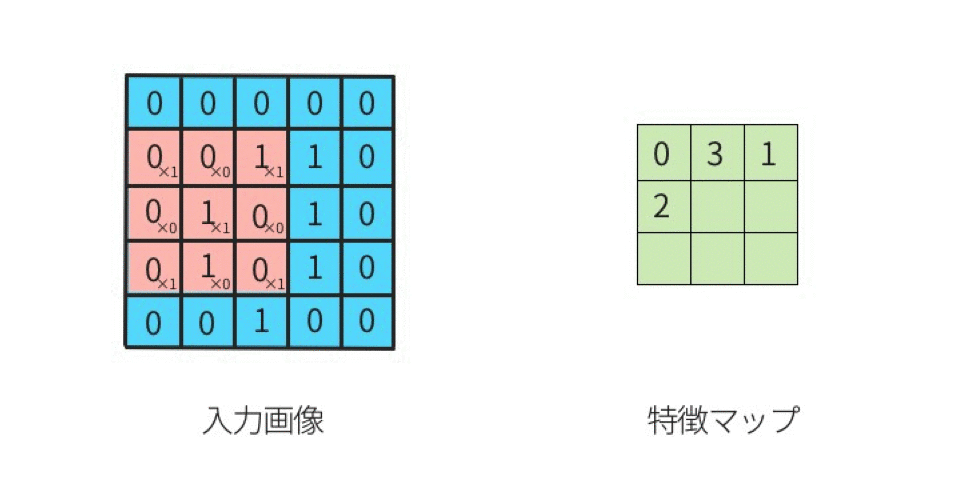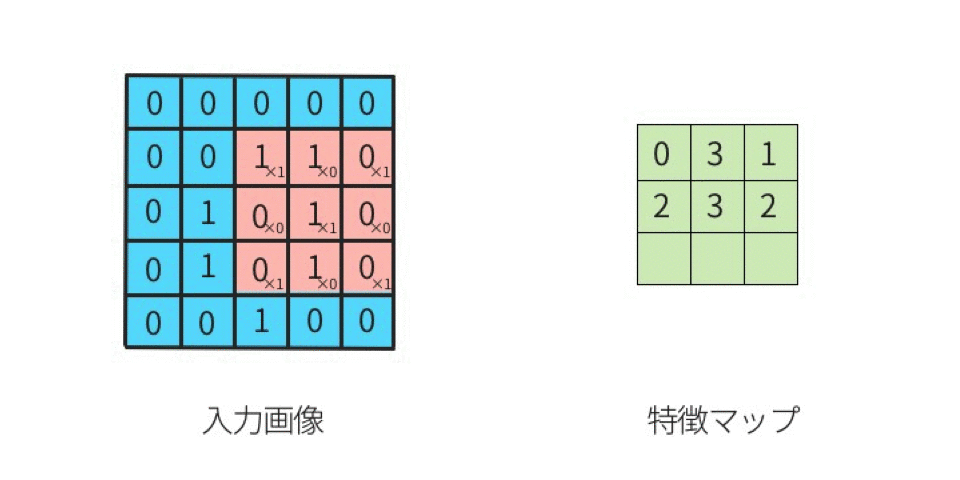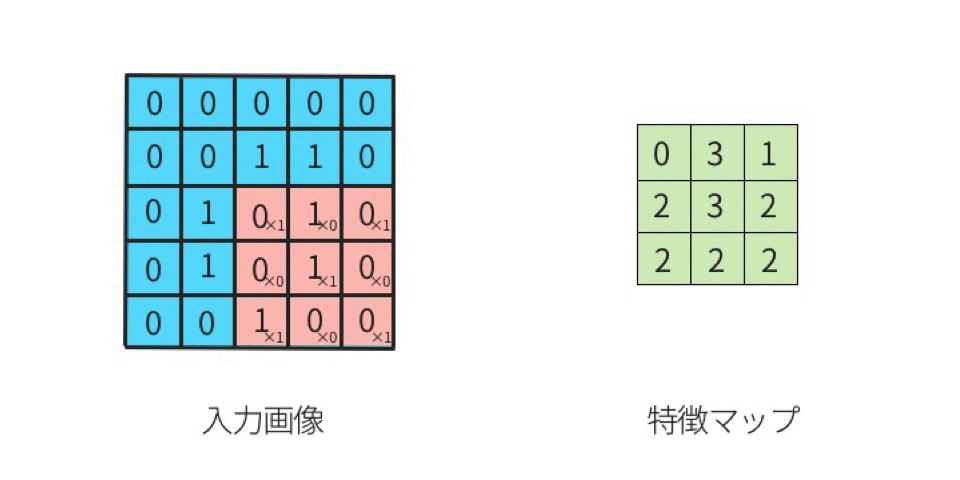
こうして計算されたデータは特徴マップと呼ばれる。
合成性
CNNはそれぞれの構成要素を理解すると、パズルのように組み合わせてつくることができるようになる。
各層は次の層へと意味のあるデータを順に受渡していく。層が進むにつれて、ネットワークはより高レベルな特徴を学習していける。
音声認識を例にとると、最初の層では局所的な音量や周波数の変化を検出し、次の層でそれらを組み合わせて騒音やノイズを検出し、より深くなるにつれて人間の声や性別を検出できるようになっているかもしれない。
移動不変性
前述の畳み込みの例で見たとおり、局所領域からフィルタを通して検出していくので物体の位置のズレに頑健になる。
つまり、特徴を検知する対象が入力データのどこにあっても検知することができる。これを移動不変性という。
回転や拡大・縮小に対する不変性はどうなのだろう?ある程度は不変性を維持できるものの、それほど頑健ではないので、データ拡張でそういったデータを増やして学習するなど工夫が必要だ。
Convolutional Neural Networkの構成要素
Convolutional Neural Networkは層と活性化関数といくつかのパラメータの組み合わせで出来上がっている。CNNはこの構成要素の知識さえあれば理解できるようになる。それぞれを見ていこう。
ゼロパディング(zero padding)
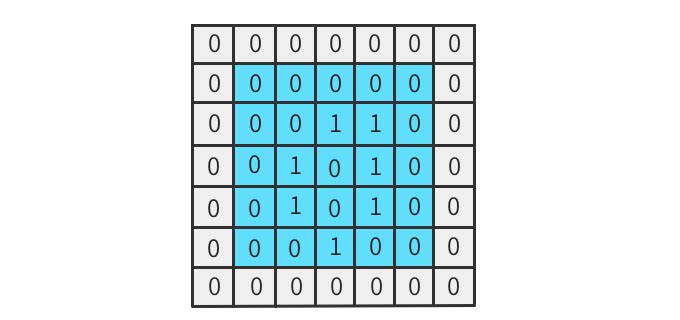
ゼロパディングは上図のように、入力の特徴マップの周辺を0で埋める。こうすることで以下のようなメリットがある。
- 端のデータに対する畳み込み回数が増えるので端の特徴も考慮されるようになる
- 畳み込み演算の回数が増えるのでパラメーターの更新が多く実行される
- カーネルのサイズや、層の数を調整できる
Convolution層とPooling層で出力サイズは次第に小さくなるので、ゼロパディングでサイズを増やしたりすると層の数を増やすことができる。
ストライド
ストライドは畳み込みの適用間隔のことで、図で表すとわかりやすい。入力データ4×4に対してストライドを1とすると以下のようになる。
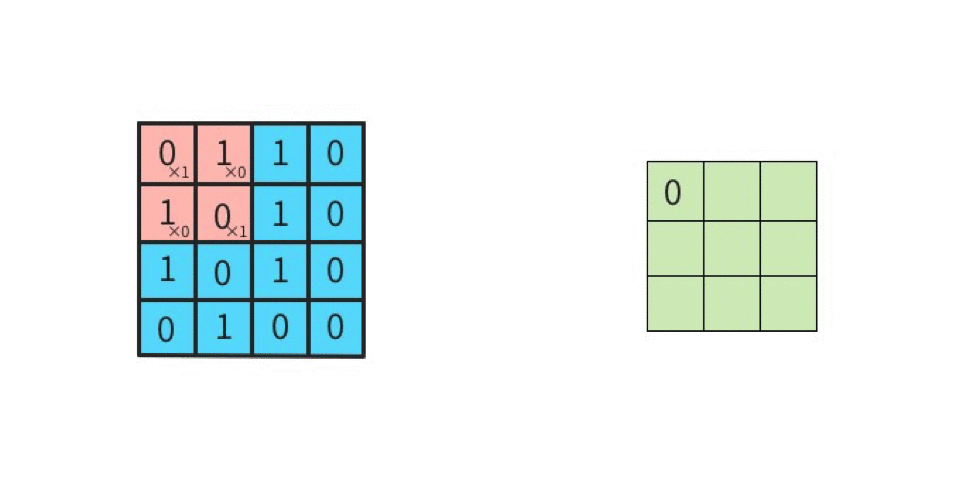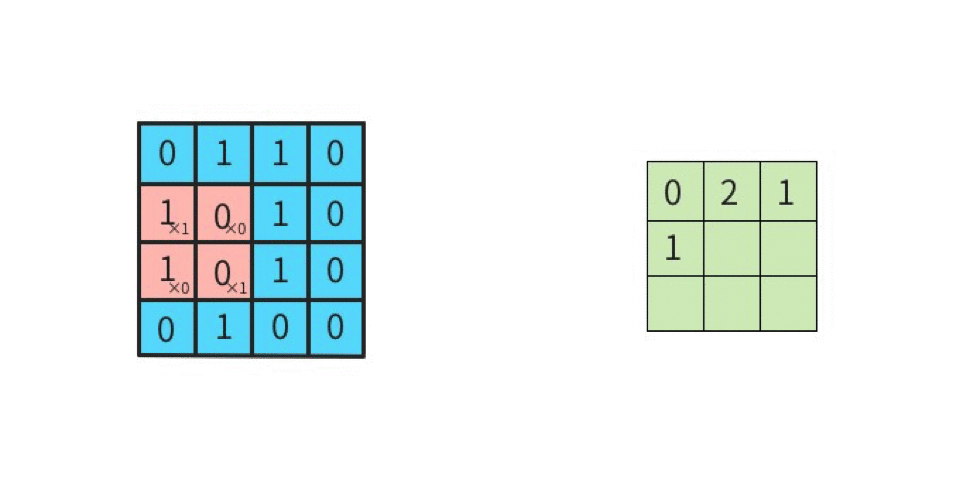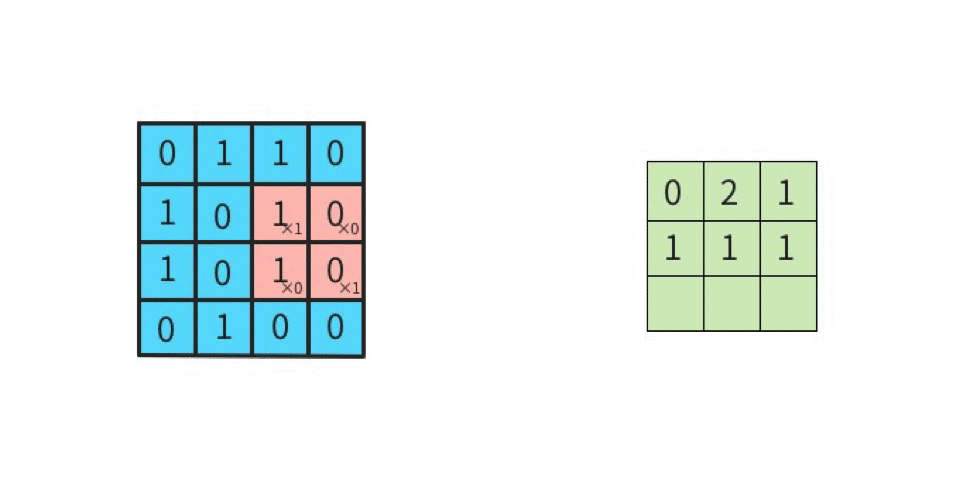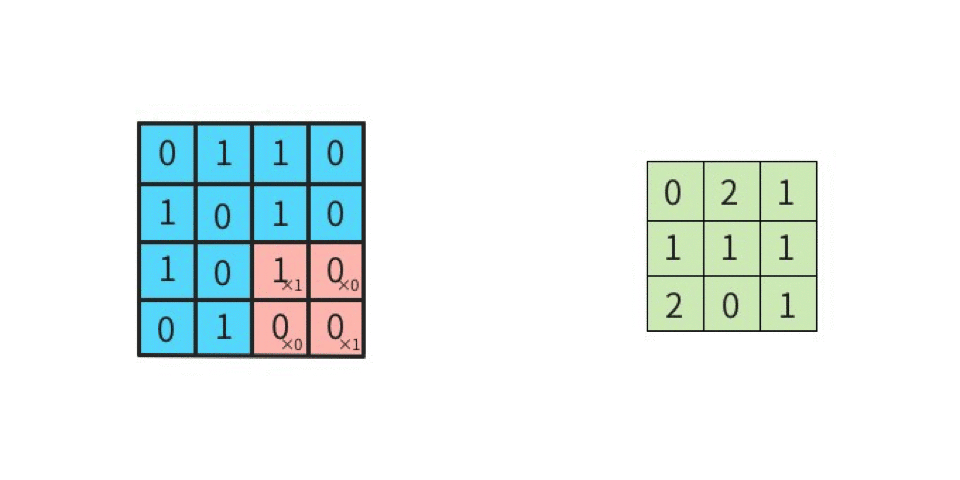
これがストライド2になると2つ間隔でフィルタが進むようになる。
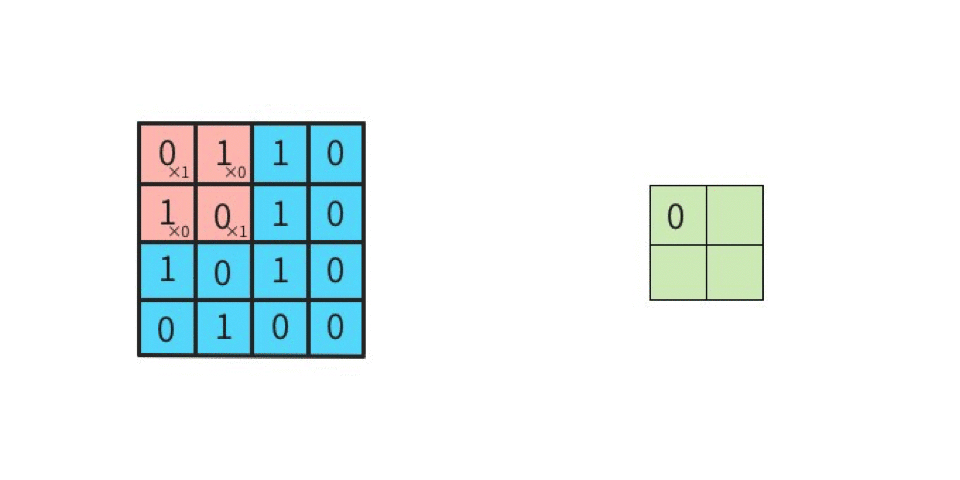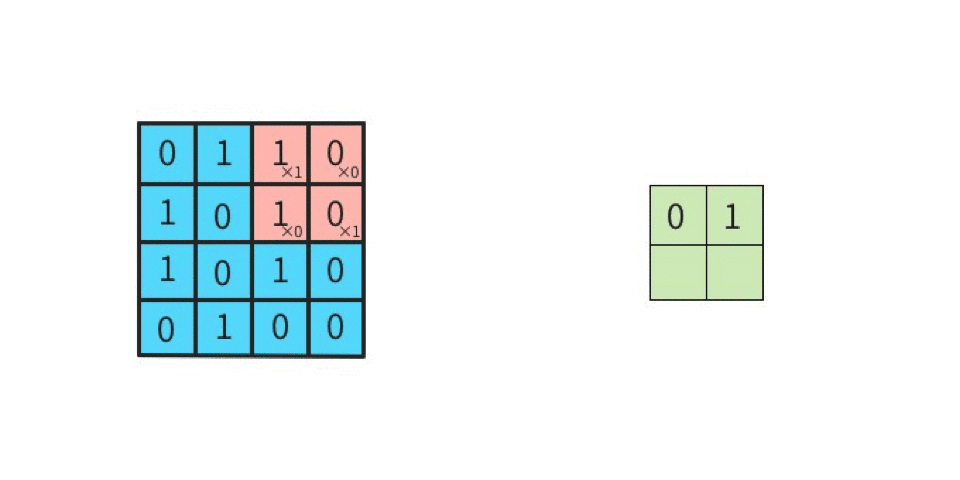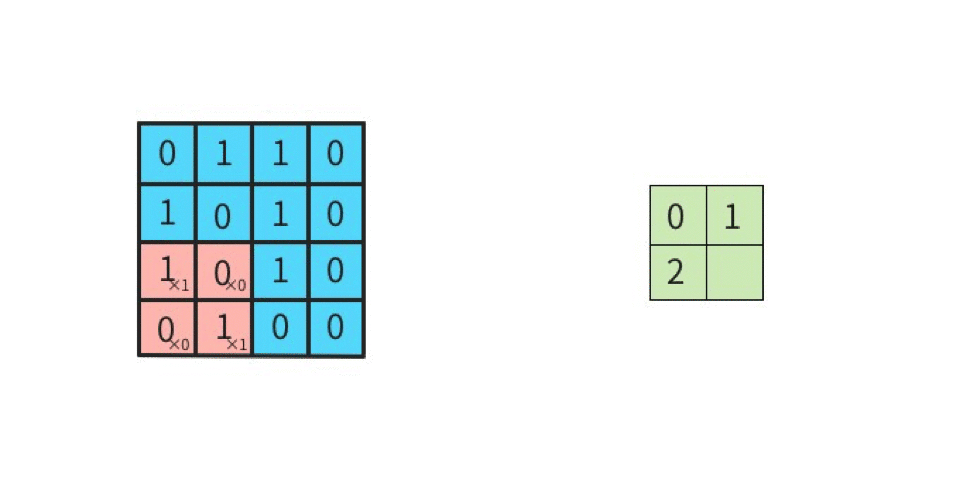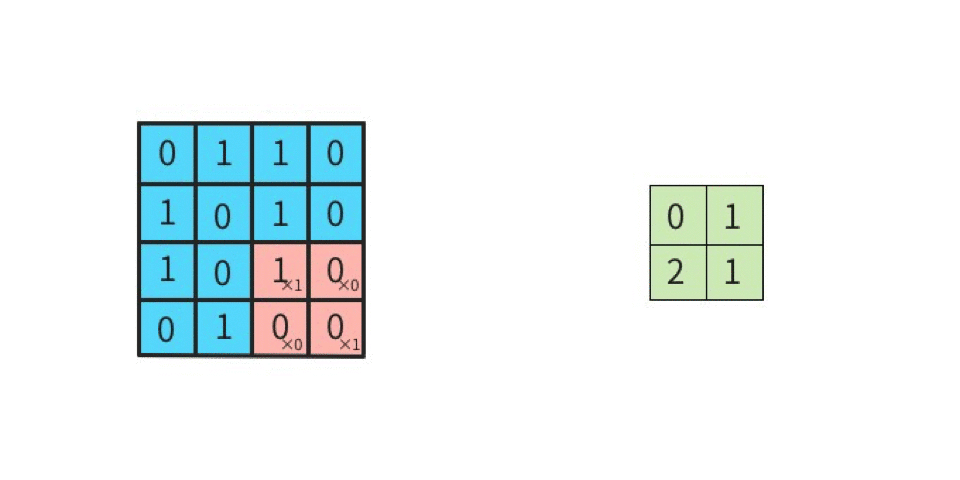
図を見て頂ければ分かる通り、出力の特徴マップのサイズが変わる。出力サイズの高さ、幅を
として、フィルタサイズの高さと幅を
そして、パディングを、ストライドを とすると、
である。この計算式を使って入力サイズ4×4、フィルタサイズ2×2、パディング0、ストライド1の場合を計算してみると、
となる。入力サイズ4×4、フィルタサイズ2×2、パディング0、ストライド2の場合、
となり、先程のアニメーションと同様の結果となる。
Fully Connected層
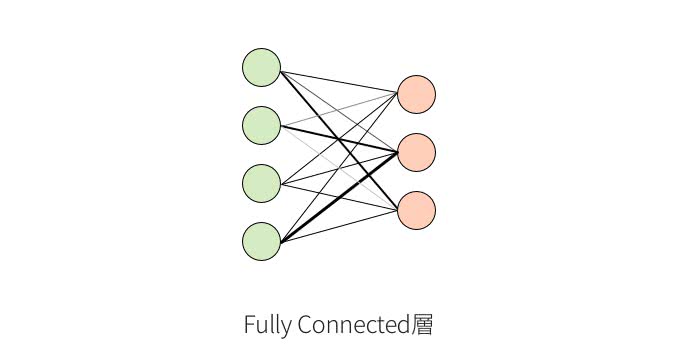
層の一つ目は、一般的なニューラルネットワークでも見られるFully Connected層(全結合層)である。各層のユニットは次の層のユニットと全て繋がっている。
それぞれのユニットとの接続は重みを持っていて、図では濃さで表している。入力は1次元のベクトルで、出力も1次元のベクトルとなる。
CNNでは出力層の手前で使われることが多く、この部分が検出された特徴の組み合わせから、予測結果に分類するための識別部となる。
また、最終的な出力層のユニットの数は分類される数と一致している必要がある。出力層での出力値がそのカテゴリと予測される確率となる。
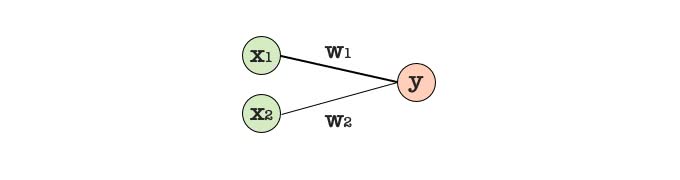
出力ユニットの値の計算は、それぞれの入力ユニットの値と接続の重みを内積してバイアスを足す。上図の例では、を出力ユニットの値として、入力ユニットの値を、接続の重みを、バイアスをとすると、
となる。ここで、 は活性化関数と呼ばれる。
Fully Connected層の問題点
Fully Connected層は1次元のベクトルを入力値として、1次元のベクトルを出力する。つまり、空間的な位置情報を無視されてしまう。音声であれば、シーク位置。画像であればRGBチャンネルを含めると3次元となる。そういった空間的な情報を扱うことができない。音量の増大や、エッジの検出など位置情報のない単一のピクセルからでは分かりにくくなってしまう。
Convolution層
それではConvolution層はどのようになっているのだろうか。
Convolution層は空間的な情報を維持することができる。widthとheightとdepthの3次元を入力値として3次元を出力する例を考えてみよう。
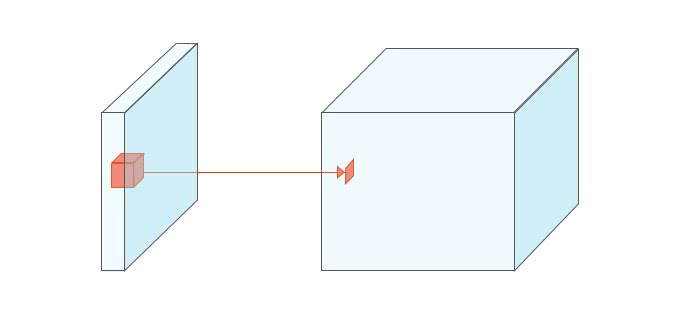
Convolution層では、各フィルターごとに畳み込み演算された結果が出力される。RGBチャンネルの入力画像の場合、フィルタも3次元となり3×3×3のフィルタであれば、合計で27個の重みフィルタとなる。上図のように、フィルタごとに畳み込み演算した出力が次の層の1つのユニットとなる。そして出力はフィルターの数の深さを持つことになる。
Fully Connected層と同様に、フィルタごとに内積を計算しバイアスを足して活性化関数を適用する。重みフィルタのパラメータがで対象の局所領域がだった場合、出力のユニットは
となる。 はReLU(Rectified Linear Unit)のことで、max(0, x)のような実装をする。Convolution層ではこの活性化関数を使うことが多い。
Pooling層
Pooling層はたいてい、Convolutoin層の後に適用される。入力データをより扱いやすい形に変形するために、情報を圧縮し、down samplingする。
max poolingと呼ばれる手法では、操作は以下のように小領域に対して、最大のものを選択する操作となる。
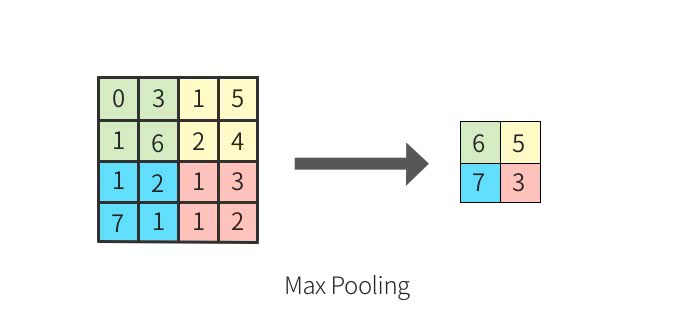
このように情報を圧縮することで
- 微小な位置変化に対して頑健となる
- ある程度過学習を抑制する
- 計算コストを下げる
といった効果があり、Convolution層とPooling層で特徴を検出する働きをする。
TensorFlowによる実装
TensorFlowでCNNの実装をしてみよう。CNNは以下の図のようなネットワーク構成をしている。入力画像が28×28となり、Convolution層→Pooling層→Convolution層→Pooling層→Fully Connected層として出力層となる標準的な実装をしよう。
TensorFlowのインストール
TensorFlowは公式サイトを参考にしてインストールする。
CNNでMNIST文字認識する
まずは必要なライブラリをimportする。
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets import mnist
from tensorflow.contrib.learn.python.learn.metric_spec import MetricSpec
learn = tf.contrib.learn
slim = tf.contrib.slim次にCNNのモデル定義をする。
def cnn(x, y):
x = tf.reshape(x, [-1, 28, 28, 1])
y = slim.one_hot_encoding(y, 10)
net = slim.conv2d(x, 48, [5,5], scope='conv1')
net = slim.max_pool2d(net, [2,2], scope='pool1')
net = slim.conv2d(net, 96, [5,5], scope='conv2')
net = slim.max_pool2d(net, [2,2], scope='pool2')
net = slim.flatten(net, scope='flatten')
net = slim.fully_connected(net, 512, scope='fully_connected1')
logits = slim.fully_connected(net, 10,
activation_fn=None, scope='fully_connected2')
prob = slim.softmax(logits)
loss = slim.losses.softmax_cross_entropy(logits, y)
train_op = slim.optimize_loss(loss, slim.get_global_step(),
learning_rate=0.001,
optimizer='Adam')
return {'class': tf.argmax(prob, 1), 'prob': prob},\
loss, train_opMNISTデータセットを読み込む。
data_sets = mnist.read_data_sets('/tmp/mnist', one_hot=False)
train_X = data_sets.train.images
train_Y = data_sets.train.labels
test_X = data_sets.validation.images
test_Y = data_sets.validation.labelsValidationMonitorを設定しておくと訓練中に学習の進捗を確認することができるようになる。TensorBoardで可視化してみると面白い。
tf.logging.set_verbosity(tf.logging.INFO)
validation_metrics = {
"accuracy" : MetricSpec(
metric_fn=tf.contrib.metrics.streaming_accuracy,
prediction_key="class")
}
validation_monitor = learn.monitors.ValidationMonitor(
test_X,
test_Y,
metrics=validation_metrics,
every_n_steps=100)Estimatorのmodel_fnにcnnを指定する。
classifier = learn.Estimator(model_fn=cnn, model_dir='/tmp/cnn_log',
config=learn.RunConfig(save_checkpoints_secs=10))
classifier.fit(x=train_X, y=train_Y, steps=3200, batch_size=64,
monitors=[validation_monitor])学習させてみよう。
$ python cnn.py
おそらくAccuracyは0.99を超えたはずだ。
Convolutional Neural Networkは今やディープラーニングの分野では中心的な存在感を発揮している。この記事や論文を通して、しっかりと理解を深めて欲しい。