Deep Learningの分野におけるテクノロジーの進歩は著しく、研究においては勿論のこと、産業や芸術作品にまで応用が広がっている。
コンピュータービジョンや、自然言語処理・音声認識などの基礎研究が進歩していくにつれて、様々な業界で今後も活用が進むことだろう。そして、我々はそういったメリットを享受し、より良い生活が送れるようになる。
本記事では、そういった技術進歩に必要なDeep Learningライブラリの中で最も人気のあるTensorFlowについて紹介する。本記事を読めば、
- Deep Learningライブラリの種類
- TensorFlowのメリット
- どんな利用用途に向いているのか
が分かることだろうと思う。もし、あなたがこれからどのライブラリを利用しようとしているのか考えているのであれば、参考にして欲しい。
TensorFlowとは
TensorFlowとは、2015年の11月にGoogleが公開したオープンソースのディープラーニングライブラリである。
Google Brain Teamでは元々、ニューラルネットワークの研究開発とGoogle製品への適用を目的として開発されたDistBeliefという社内ツールを使っていた。
TensorFlowは、YouTube、Google翻訳、検索エンジンなどの開発を進めていたDistBeliefの知見を活かして、さらに使いやすく様々な領域に適用できるよう開発を進め、公開されたものだ。
Googleがライブラリに求める条件は厳しく、
- 巨大なデータセットを訓練できるようにすること
- 計算リソースを最大限活用できること
- 誰でも使いやすいインターフェースで柔軟性と拡張性があること
が条件だったが、全てを満たすものが当時無かったのだ。
TensorFlowの実績
TensorFlowのトップページには、以下のように様々なTensorFlowを利用する名だたる企業のロゴがずらっと並んでいる。

こういった実績も、TensorFlowが人気となった一つの要因だろう。
特にGoogle社内ではすでに、60以上ものプロジェクトでTensorFlowが採用されている。 [1]
公開後1年で
- GitHub上で最もスターを集めた機械学習ライブラリ
- 480人以上もの開発者が参加
- TFLearnやTensorLayer、PrettyTensorなどのラッパーライブラリも登場
と好スタートを切っている。TensorFlowを他のライブラリと比較するためにディープラーニングライブラリの種類について解説しよう。
Deep Learningライブラリの種類
まずは以下の表を見て欲しい。有名ライブラリを特徴別に分類して表にまとめたものだ。
| ライブラリ名 | デバイス対応 | スタイル | 分散対応 | 主要言語 |
|---|---|---|---|---|
| TensorFlow | GPU, Mobile | 宣言的 | ✓ | Python |
| Torch7 | GPU, FPGA | 命令的 | Lua | |
| Theano | GPU | 宣言的 | Python | |
| Caffe | GPU | 命令的 | Protobuf, Python | |
| Chainer | GPU | 命令的 | Python | |
| MXNet | GPU, Mobile | 宣言的+命令的 | ✓ | Julia, R, Python |
| CNTK | GPU | 宣言的 | ✓ | BS, Python |
主に、ディープラーニングライブラリの重大な違いは
- プログラミングスタイル
- 分散対応・マルチGPUの可否
- プログラミング言語
あたりだろう。
プログラミングスタイルには命令的な実装方法と宣言的な実装方法がある。
Wikipediaの宣言型プログラミングのページには以下のような記述がある。
SQLのクエリは「どのようなデータが欲しいか」を記述するものであり、例えば具体的なB木の操作などといった「いかにしてデータベースにアクセスするか」といったことには関与しない。
この手法は、FORTRAN、C言語、Javaなどといった命令型プログラミング言語とは全く異なる。命令型では、目的を実現するアルゴリズムを、その順序に沿う形で記述しなければならない。
つまり、命令型プログラムでは目的を達成するための方法を「手続き」として示すのに対し、宣言型プログラムでは達成すべき目的(出力)を示して、それを実現する手続きはシステムに任せるわけである。
つまり、命令的なスタイルは、どのように(How)計算が行われるかを指定する一方で、宣言的なスタイルは、どうあるべきか(What)を記述する。
分散対応は、計算するマシンを複数台にスケールアウトすることが出来るかどうかだ。1台のマシンの中に収まっているGPUやCPUリソースをフルに活用するだけでなく、他のマシンの計算リソースを使うことができる。
データフローグラフアーキテクチャとプログラミングモデル
TensorFlowのソースコードが公開されているGitHub上にはTensorFlowを以下のように紹介している。
Computation using data flow graphs for scalable machine learning
データフローグラフというのは、データと計算における有効グラフのことだ。特にTensorFlowにおいては、データの読み込み、前処理、計算、状態、出力まで一貫してこのデータフローグラフを構築して処理することを念頭に設計されている。
基本コンセプト
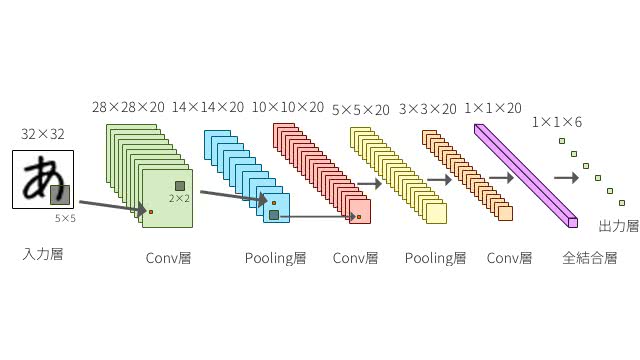
以下の図を見て欲しい。TensorFlowの核となる基本コンセプトは、データのパイプラインを構築することだ。
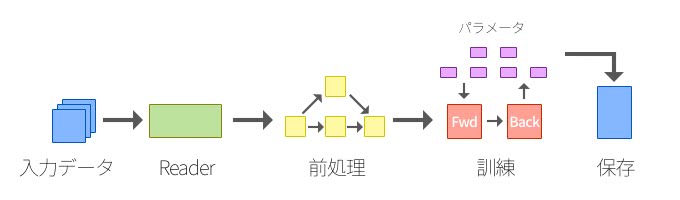
一般的な計算グラフというのは、何らかの数値計算のグラフを構築して実行することになるが、データフローグラフにおいては、入力データから各数値演算、状態変数、保存まで一貫して有向グラフのパイプラインを構築して実行する。
データフローグラフ
データフローグラフは、ノードとエッジからなる有向グラフで出来ている。ノードは一般的には数値演算処理か変数を表すが、データの読み込みや計算結果の書き込みをすることもできる。
エッジは、任意のサイズの多次元配列かテンソルを表す。ノードは実際に計算するデバイスが割り当てられ、非同期に並列・並行実行される。
以下のような重みとバイアスを初期化して、活性化関数を適用するようなコードを例に考えてみよう。
import tensorflow as tf
b = tf.Variable(tf.zeros([100])) # 100次元のベクトルを0で初期化
W = tf.Variable(tf.random_uniform([784,100],-1,1)) # 784x100の行列を-1から1のランダムで初期化
x = tf.placeholder(name="x")
relu = tf.nn.relu(tf.matmul(W, x) + b)この計算グラフは行列計算と加算と活性化関数の適用の3つのノードとデータの入出力となるエッジとなる。
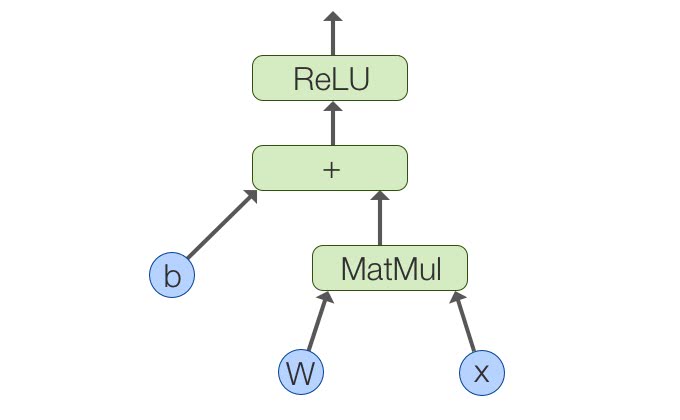
分散学習
TensorFlowはあらゆる環境で動作することを目的として開発され、iOSやAndroidといったモバイル環境においても実行することができるだけでなく、計算を複数のマシンを跨いで並列処理することもできる。
また、Googleのように大量の学習データを持つ企業が開発していることもあり、そういったビッグデータを大量の計算リソースを使って学習することができるようになっている。
データが莫大になり、パラメータが増大し学習モデルが複雑になるにつれて、1つのマシンでは迅速に学習が収束しない問題が起きる。
例えば、Google DeepMindが囲碁でイ・セドル氏に勝利したAlphaGoはCPUサーバを1202個、GPUサーバを176個使って戦ったものだ。[2]
分散実行モデル
TensorFlowでは、データフローグラフを構築した後に、計算タスクをclientとmaster、複数のworkerに分け、最後にdeviceにタスクが割り振られて分散実行する。
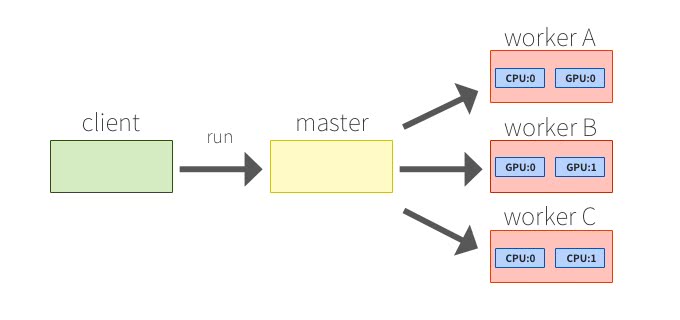
clientがデータフローグラフをSessionのrunルーチンでmasterプロセスに評価させ、masterプロセスは個々の計算タスクをworkerに割り振っていく。各workerはdeviceに実際の計算や制御をさせる責任を持つ。
Parameter Server
複数台のマシンで分散学習するためには、パラメータの状態やクラスタの情報などのマシン間で通信するパラメータを共有する必要がある。こうした共有ステートを保存するデータベースがParameter Serverだ。
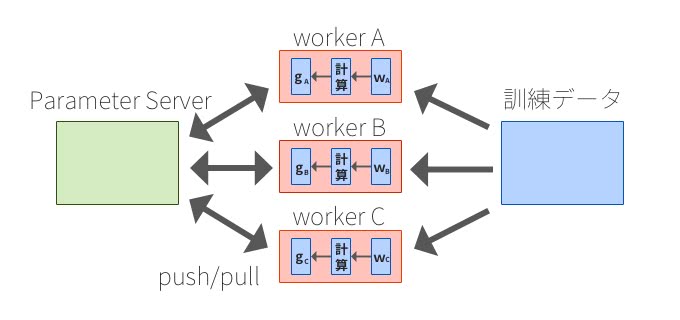
確率的勾配降下法の計算の例が分かりやすい。Workerノードはデータを処理してミニバッチ間で局所勾配を計算し、キーを割り当てた値をメッセージとしてParameter Serverに更新リクエストを送信(Push)する。また、Workerは、計算に必要な値を取得(Pull)することができる。
TensorFlowに備わっているParameter Serverは、ConsistencyやFault Tolerance、柔軟なスケーラビリティを兼ね備えた優れたアーキテクチャになっている。
Fault Tolerance
複数台のマシンで学習を分散化したとしても、学習モデルを訓練するためには、一般的に数時間から数日、長い場合は数ヶ月といった時間を掛けて計算する必要がある。
学習を分散実行すると、通信の失敗や機器の故障といった障害が発生しうる。TensorFlowにはこういった障害を検知すると、全体の計算グラフの実行を停止して、最初から構築し直すメカニズムになっている。学習中に、パラメータの状態のチェックポイントを書き出しておくことで、再構築し直した際に、前回保存したチェックポイントから状態を復元することができる。
可視化ツールTensorBoard
複雑なディープラーニングのモデルになってくると、計算グラフのノードやパラメータは増えていき、デバッグが難しくなる。LSTMを使ったRNNモデルをTensorFlowで構築すると、15,000以上ものノードが計算グラフに含まれ、Inceptionモデルでは36,000個以上のノードが必要になるのだ。[4]
こういったネットワークが正しく構築されているかどうかを確認し、パラメータの爆発や消失が発生していないかを確認するために、TensorFlowにはTensorBoardという強力な可視化ツールが備わっている。
TensorBoardでは以下の可視化機能が備わっている。
- 計算グラフ
- スカラー値の折れ線グラフ・ヒストグラム
- 画像
- 音声
- 埋め込み表現
具体的に説明しよう。
グラフの可視化
ディープラーニングのネットワーク構成は複雑になりがちで、正しく実装出来ているかどうかをコードだけで確証を持つことは非常に困難となる。
計算グラフを可視化することで、コードだけでなくグラフを見て間違いに気づくことができる。
以下のコードを見て欲しい。これは、Convolutional Neural Networkのモデル定義例となっている。
def cnn(x, y):
x = tf.reshape(x, [-1, 28, 28, 1])
y = slim.one_hot_encoding(y, 10)
net = slim.conv2d(x, 24, [5,5], scope='conv1')
net = slim.max_pool2d(net, [2,2], scope='pool1')
net = slim.conv2d(net, 56, [5,5], scope='conv2')
net = slim.max_pool2d(net, [2,2], scope='pool2')
net = slim.flatten(net, scope='flatten3')
net = slim.fully_connected(net, 512, scope='FC4')
net = slim.fully_connected(net, 10,
activation_fn=None, scope='FC5')
prob = slim.softmax(logits)
loss = slim.losses.softmax_cross_entropy(logits, y)
train_op = slim.optimize_loss(loss, slim.get_global_step(),
learning_rate=0.001,
optimizer='Adam')
return {'class': tf.argmax(prob, 1), 'prob': prob},\
loss, train_opこちらのモデルを実行してTensorBoardで可視化してみると、このようになる。
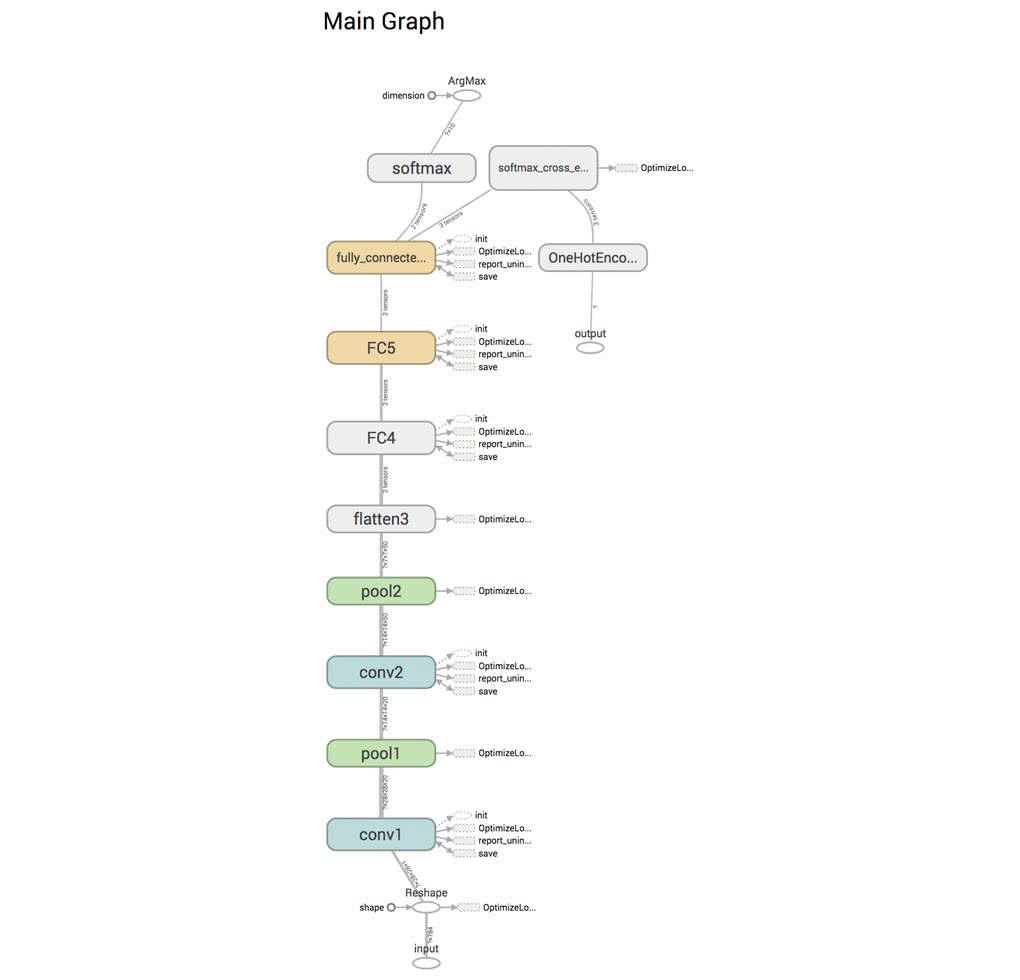
下部にInputという名前が付いた入力があり、softmaxという部分まで一直線に繋がっている事がわかる。もしこのコードを間違えていたとしたらどうなるだろうか。先程のコードを以下のように修正して実行してみよう。
def cnn(x, y):
x = tf.reshape(x, [-1, 28, 28, 1])
y = slim.one_hot_encoding(y, 10)
net = slim.conv2d(x, 24, [5,5], scope='conv1')
net = slim.max_pool2d(net, [2,2], scope='pool1')
net = slim.conv2d(net, 56, [5,5], scope='conv2')
net = slim.max_pool2d(net, [2,2], scope='pool2')
net = slim.flatten(net, scope='flatten3')
net = slim.fully_connected(net, 512, scope='FC4')
net = slim.fully_connected(x, 10,
activation_fn=None, scope='FC5')
prob = slim.softmax(logits)
loss = slim.losses.softmax_cross_entropy(logits, y)
train_op = slim.optimize_loss(loss, slim.get_global_step(),
learning_rate=0.001,
optimizer='Adam')
return {'class': tf.argmax(prob, 1), 'prob': prob},\
loss, train_opこちらは、出力層のslim.flatten関数の第一引数をnetとしなければならないところを、xとしてしまった例だ。こういったコードのミスは、普通に実行して学習が進んでしまうと、間違いに気づくことが難しくなる。このコードを実行してTensorBoardで可視化してみよう。
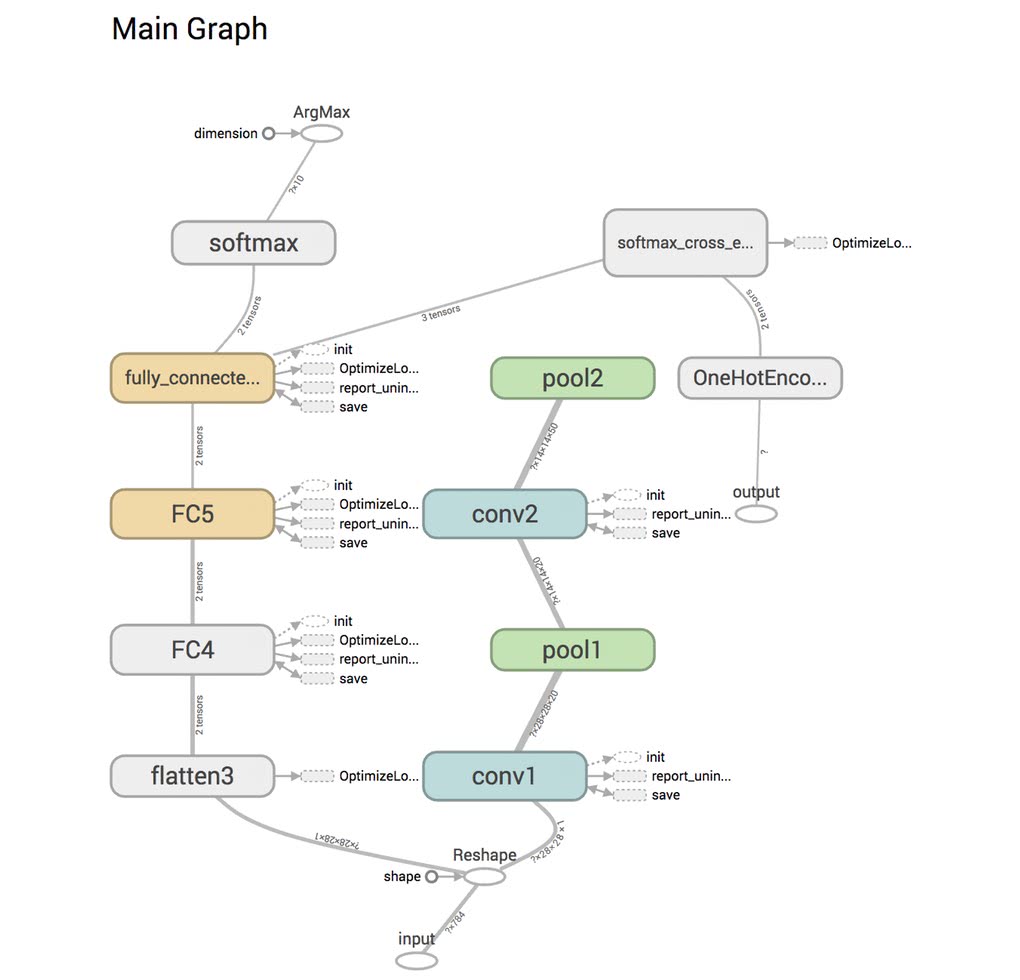
可視化してみると、Convolutoin層とPooling層が全結合層と繋がっておらず、このように自分のコードの間違いにすぐ気づくことが出来る。
また、任意のスカラー値もログに残すことで可視化することができる。TensorBoardは
- 値の折れ線グラフ
- 値のヒストグラム
の可視化をサポートしており、折れ線グラフでは一定のイテレーション毎にテンソルの値や計算結果を可視化し、ヒストグラムでは値の分布を確認することができる。
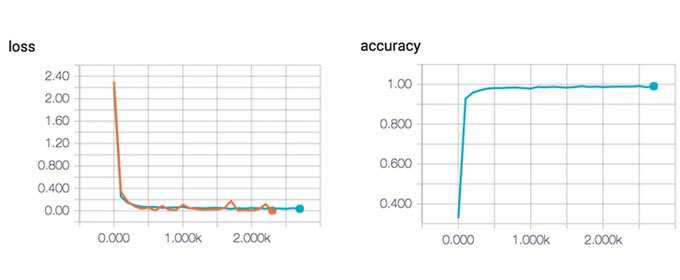
以下のグラフは、学習中の誤差が下がる様子と正答率が上がっていく様子をグラフ化したものだ。 グラフに残すことで、グラフの傾向や値を詳細に見ることが出来るので、チューニングや学習結果の確認に使うことができる。
画像・音声までもログにする
TensorBoardは音声や画像もログに残すことが出来る。データ拡張や、データを加工したときに、正しく加工できているかどうかを確認することができる。以下は先程のCNNの入力画像を可視化した例だ。

Embeddingの可視化
ニューラルネットワークだけでなく、埋め込み表現は、推薦システム・自然言語処理で利用されるテクニックだが、TensorBoardでは埋め込み表現の可視化することが出来る。埋め込み表現について詳しくは以下を見て欲しい。
t-SNEとPCAの方式で次元削減することが出来る。
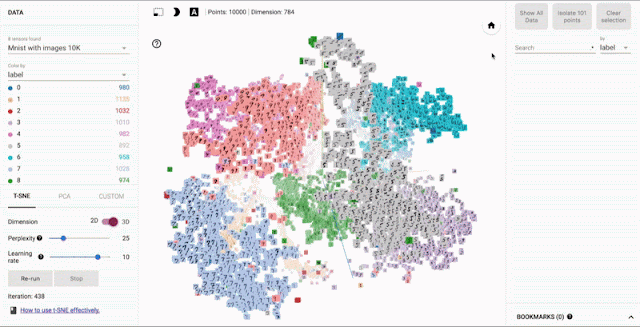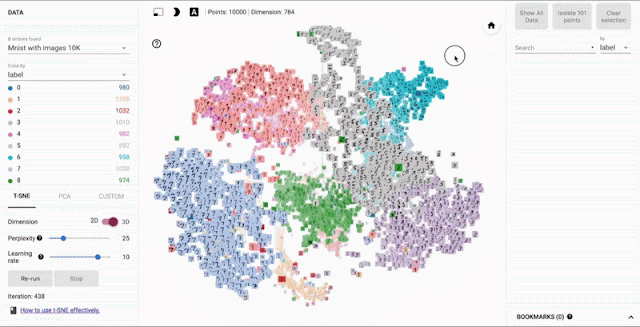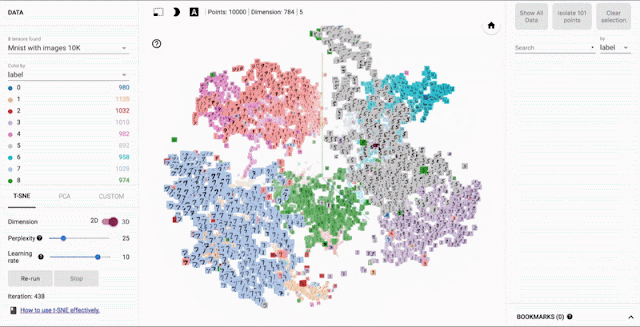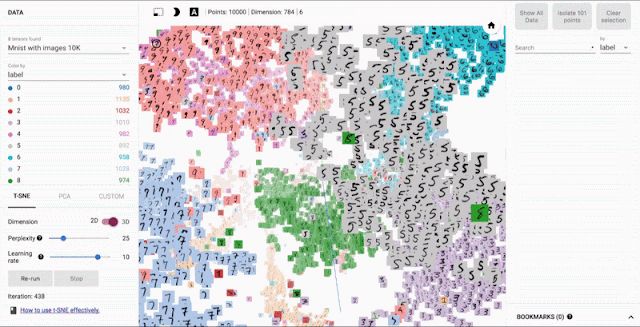
出典:TensorBoard: Embedding Visualization
インターフェースのシンプル化
TensorFlowは、全てを計算グラフで扱うように矯正することや便利関数が少ないことから、インターフェースが馴染みがなく、特に初学者にとっては扱いにくいと感じる部分もあるだろう。そういったニーズからTensorFlowをバックエンドとしたTFLearn・TensorLayer、skflowといったラッパーライブラリが開発され、研究者やプロトタイプ開発に応用されてきた。
現在では、skflowはTensorFlowに取り込まれ、さらに分散学習もサポートできるようシンプルで扱いやすいインターフェースを通して利用できるようにする開発ロードマップが予定されている。[5]
TF.Learn
TF.Learnは、機械学習ライブラリscikit-learn風のインターフェースでTensorFlowを使えるようにしたskflowというライブラリが本家に取り込まれたものだ。
3層DNNであれば、以下のように数行で記述出来る。
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/learn_model")
# Fit model.
classifier.fit(x=train_X,
y=train_Y,
steps=2000)TF-Slim
TF-Slimは、TensorFlowでよく利用する高レベルAPIだ。以下のモジュール群が揃っている。
-
arg_scope: スコープ内のデフォルト引数を定義する。 -
data: データの読み込み、プロバイダ、パラレルリーダー、デコーダなど。 -
evaluation: モデルの評価ルーチン。 -
layers: モデル定義に便利な高レベルの層の定義。 -
learning: 訓練ルーチン。 -
losses: 誤差関数のユーティリティ。 -
metrics: 評価メトリクスのユーティリティ。 -
nets: ネットワーク構成の定義。 -
queues: QueueRunnerを簡単に使えるコンテキストマネージャー。 -
regularizers: 重みの正則化ユーティリティ。 -
variables: 変数の作成と定義。
まとめ
TensorFlowはディープラーニングライブラリの中では、一番人気ということもあり、大きなエコシステムが出来上がりつつある。
教育コンテンツや、学習リソース・開発フィードバックを受けられることも含めて、エコシステムのメリットは大きいだろう。
KerasやTFLearnなど、気軽に使えるライブラリもあるので、自分の利用用途に合わせて選定して欲しい。
参考
[1] TensorFlow: A system for large-scale machine learning
[2] Mastering the game of Go with deep neural networks and tree search
[3] TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
[4] A Tour of TensorFlow
[5] Roadmap