- Word2Vecとは
- Word2Vecで演算処理する
- Word2Vecとニューラルネットワーク
- Word2Vecの仕組み
- Word2Vecを応用することができる分野
- Word2Vecの弱点
- Word2Vecの派生系や類似ツール
- まとめ
- 参考
世界中のWebサイトの数は2014年に10億件を超えたようだ。そして、Facebookのユーザー数だけでも16億人を超えている。
そして、そのいずれもコンテンツの中身の大部分はテキストから成り立っていることだろう。
ということは、莫大に増大し続けるネット上のデータのほとんどはどこかの国の言葉だってことだ。世界中の人が毎日テキストデータを生成し続けたことはこれまでの歴史上無かったんじゃないだろうか。
もしそんな世界中の人の言葉をすべて理解するシステムを構築できたとしたら、あなたは何をしてみたいと思うだろうか?
この記事ではその根幹部分を成す基礎技術を紹介しよう。それがWord2Vecだ。
Word2Vecとは
Word2Vecという単語を聞いたことがあるだろうか?
これは、単語の意味や文法を捉えるために単語をベクトル表現化して次元を圧縮したものだ。 単語をベクトル表現にしようと思うと、
「プログラマー」
という単語は、何らかの数値を持たないので単にラベル付することが多い。100万単語あるとしたら、100万次元のベクトルとして各要素をそれぞれの単語に割り当てるといった具合だ。これをone-hotベクトルと呼ぶ。
「イチロー、プログラマー、パリ、道頓堀、打つ」という5単語をワードセットとして、プログラマーを表すベクトルは以下のようになる。
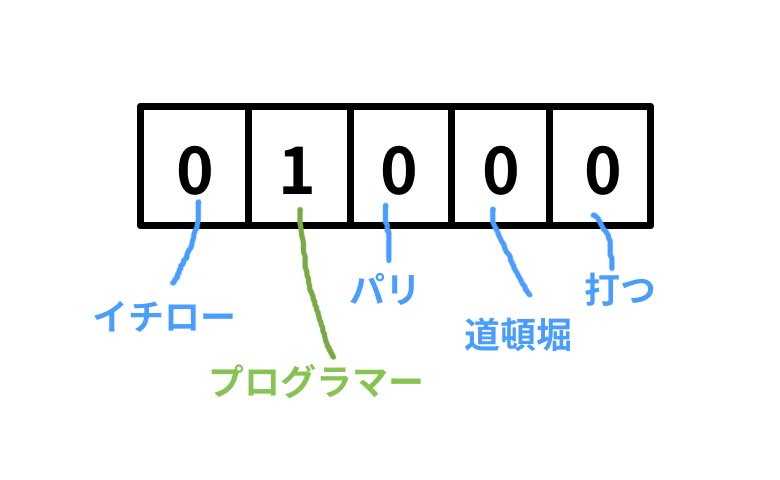
でも、これだと同一単語かどうかの比較以外に演算処理しても全く意味が無い。さらに、未知語や新しい単語を追加しようとするとベクトルの次元が増えてしまう。そこで、もっと表現豊かなベクトルにして、演算処理までできるように単語の分散表現(Word Embeddings)というものを提案した。
分散表現では通常200〜1000次元くらいのベクトルであり、先ほどのような各要素ごとにマッピングするのではなく、単語の定義によってベクトル化していく。
自分で定義する必要はないが、想像しやすくするために定義すると
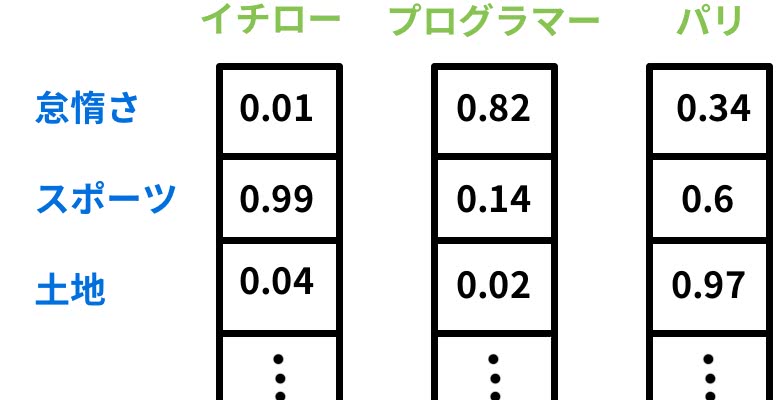
上図のように抽象的な意味を表現するようなベクトルとなっている。
Word2Vecで演算処理する
こうすると何が嬉しいのかというと
- 「王様」- 「男」+ 「女」= 「女王」
- 「パリ」- 「フランス」+ 「日本」= 「東京」
のような演算をすることが出来るようになり、単語間の意味に基いて関係性を理解することができるようになる。
簡易的に二次元で表現すると、以下のようになるはずだ。
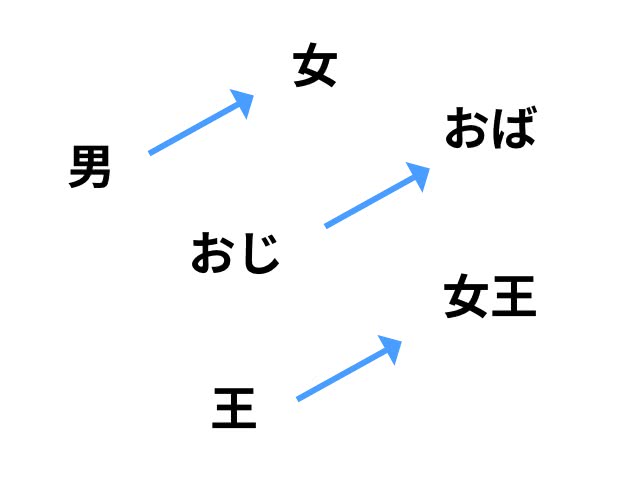
男女間の関係が近い値のベクトルで表される
つまり、「ソフトバンク」と「孫正義」の関係は「ユニクロ」にとっての何だろう?という問いに答えることができるようになるってことだ。
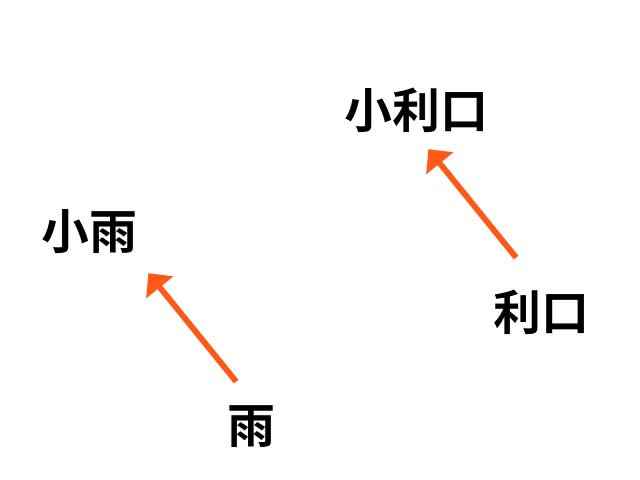
これは、上のような意味的な関係性においても効果を発揮し、シンタックス上の違いにおいても効果がある。
例えば、「雨」と「小雨」の違いと「利口」と「小利口」の違いが同様の違いをもつこともベクトルで表現できる。
Word2Vecとニューラルネットワーク
低次元にベクトルを圧縮し、演算することが出来て嬉しいことは何だろうか?
それは、ニューラルネットワークの入力の素性に利用できることだ。
分類、認識、予測といった機械学習の精度は近年ハードウェアの進歩とディープラーニングによって大幅に向上している。
ニューラルネットワークが進歩し続けているのに、自然言語処理に対して使うことが出来ないのはもったいないだろう。
Word2Vecの仕組み
私たちは「犬」と「猫」が近い意味を表す単語だということを知っている。同じ動物でよくペットとして飼われている。
ではどうやったらコンピューターは自分でこれを学ぶことができるのだろうか?
Word2Vecではこれが文中で交換可能かどうかに注目している。
例えば、「このペットショップに◯のエサはありますか?」という文の◯に「犬」を入れても「猫」を入れてもおかしくない。
CBoW
CBoWは、Continuous Bag-of-Wordsの略である。CBoWにおいて、文法と意味を学習していくことは、
文脈中の単語から対象単語が現れる条件付き確率を最大化することである。
つまり、前後の単語から対象単語を推測していくことになる。
ひとたびフルスピードで回り始めたなら、それを動かし続けるのに努力は必要ない。
という文を考えてみよう。 「続ける」を対象単語とすると入力層は、周辺5単語の
[ なら,、,それ ,を, 動かし, の, に, 努力, は, 必要]
の単語リストそれぞれのone-hotベクトルを入力として、真ん中の「続ける」が来る確率を最大にするように学習させたい。
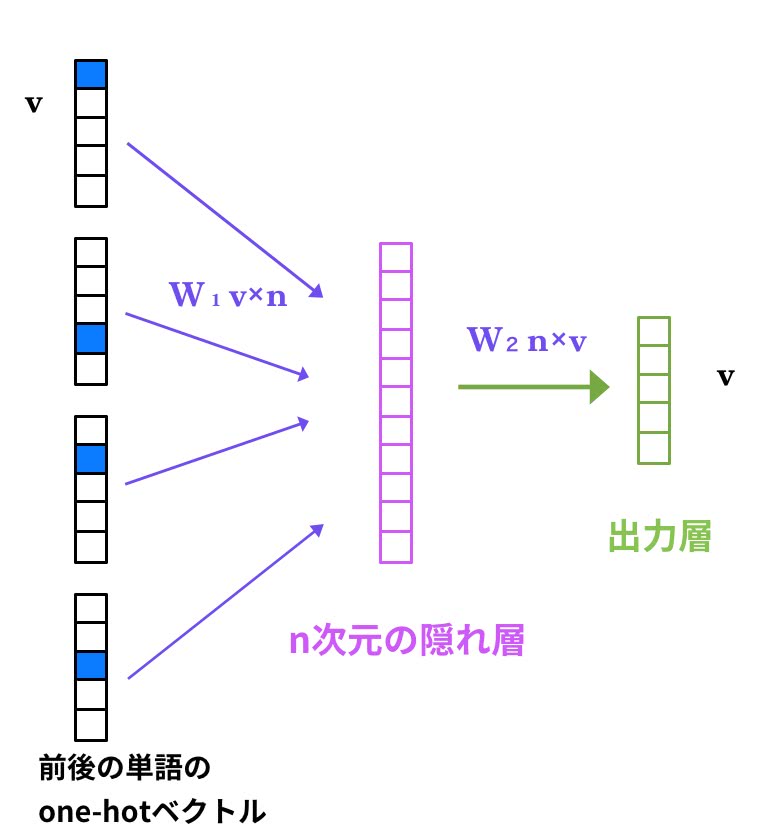
そこで、このような1つの隠れ層を持つニューラルネットワークを構築すると の重み行列がスコアを計算するためのモデルとなる。
Skip-gram
Skip-gramはCBoWの逆だ。単語からその周辺単語を予測する。Skip-gramにとって意味・文法の獲得は、
出力層における周辺単語予測のエラー率の合計を最小化することである。
先ほどの例だと、「続ける」から[ なら,、,それ ,を, 動かし, の, に, 努力, は, 必要]を予測することだ。
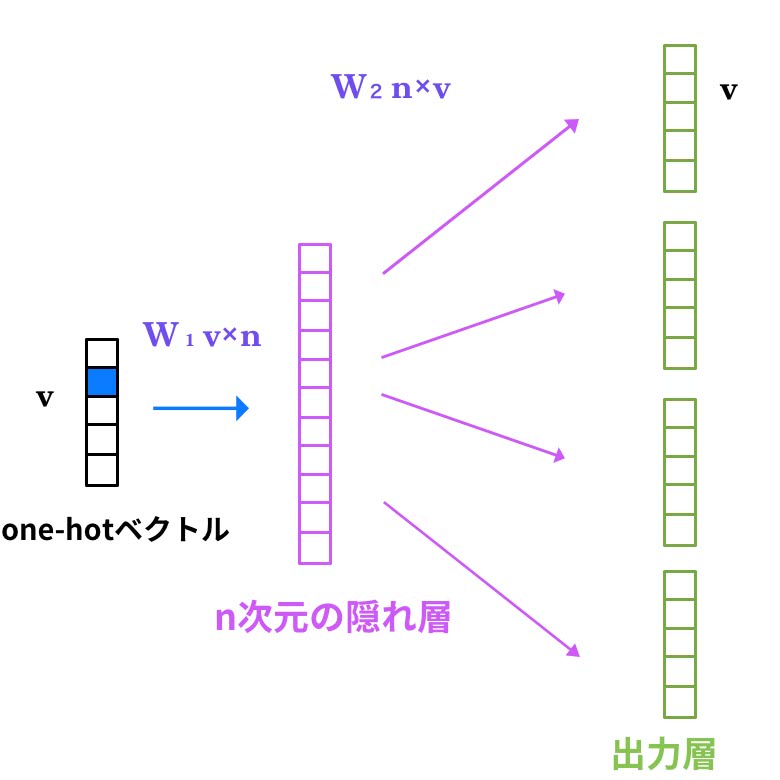
Skip-gramは学習データが少なくてもある程度の精度がでるとされている。 そして、CBoWよりもSkip-gramの方が実験では意味的な精度が高くなり、構文の精度ではあまり大差はないようだ。
Word2Vecを応用することができる分野
ではWord2Vecはどんな分野に応用できるだろう?Word2Vecを発明したMikolov 氏は
意味的な関係を表現することができる単語ベクトルを使うことで、自然言語処理の多くのシステムを改善することができるかもしれない。
と言っている。事例と共に紹介しよう。
レコメンド
リクルートテクノロジーズの自然言語処理の適応事例というスライドを参考にすると
単語のベクトル表現を学習し、類似度を計算することで、アイテムレコメンドの精度が向上しCVRが31%改善したサービスと156%改善した事例があるのだそう。
更にその後、ユーザーの行動履歴を学習し、合成ベクトルを計算することでユーザーの嗜好をかなりの精度で理解するようになりCVRが27%改善したそうだ。
機械翻訳
Word2Vecの発明者Mikolov氏はさらに機械翻訳に応用した論文を発表している。
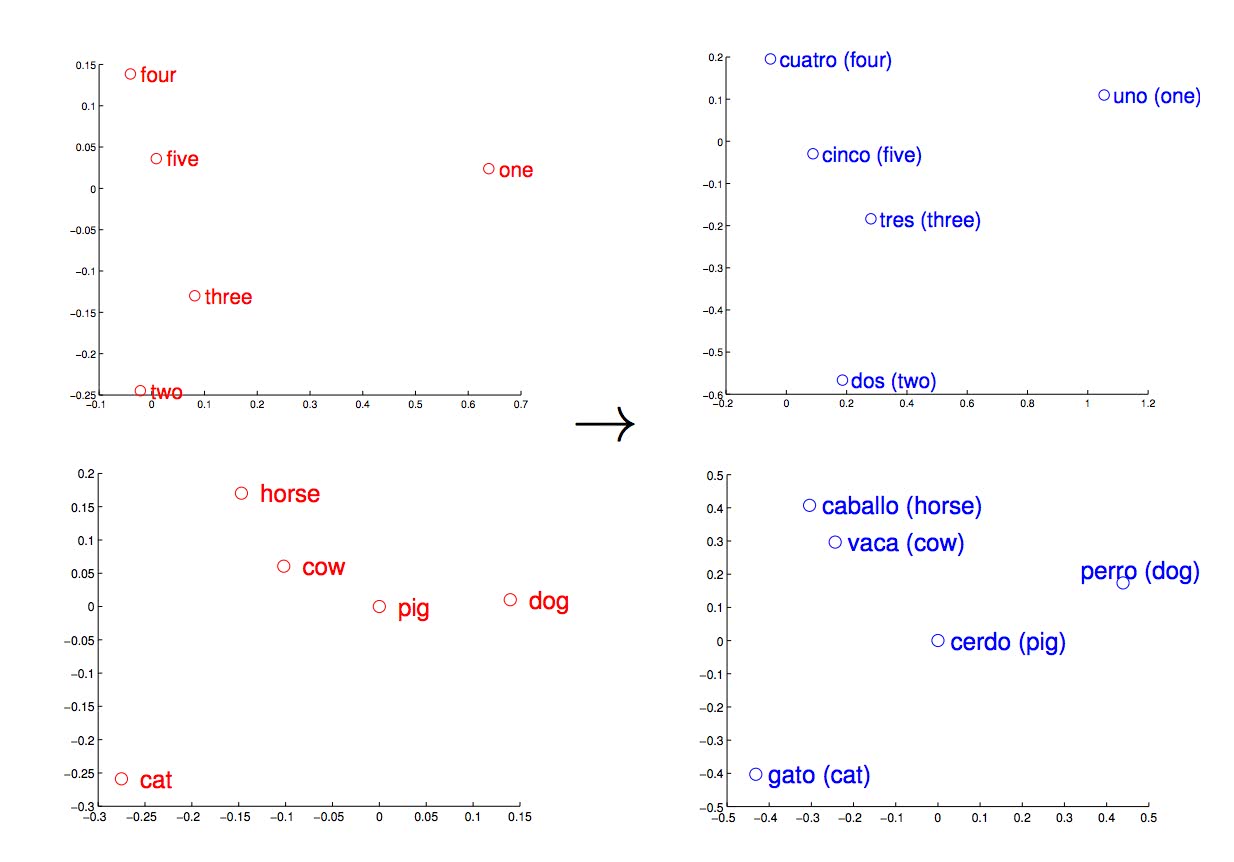
単語の分散表現を機械翻訳に応用し、従来では手動と確率的な方法で構築していくしかなかった言語間の変換表を英語とスペイン語との単語データセットにおいて90%の精度で変換できる変換表を自動で生成することに成功したようだ。
Q&A・チャットボット
質疑応答システムやLINEやFacebookで今後盛んに開発が進むと予想されるチャットボットにもWord2Vecは利用可能だ。
テキスト上に出現する「人名」や「地名」、「日付」「時間」といった固有名詞・数値表現を抽出する技術のことを固有表現抽出と呼ばれる。
これにもWord2Vecを利用しようという試みがなされている。
チャットボットや公式アカウントに「今日の夜8時頃牛丼持ってきてくれる?」と聞くだけで、入力フォームがなくても質問に答えることができるのだ。
これは文を、
| クラス | 意味 |
|---|---|
| LOC | 地名 |
| ORG | 組織 |
| PER | 人名 |
| DAT | 日付 |
| TIM | 時間 |
といったカテゴリに分類することで実現しているが、この分類手法にニューラルネットワークを利用している。入力層にWord2Vecを使って単語ベクトルを学習させ、高精度の結果を得る。
感情分析

Instagramでは、絵文字付きの投稿が60%以上にも及ぶ地域もあるようだ。Instagramのユーザーがどのように絵文字を利用し、どんな感情を持っているかを理解することは同社にとって重要だと思われる。
ユーザーの投稿を分散表現を学習することで、面白い結果が出てきたようだ。
絵文字の「色」が違うだけで意味が変わるらしい。
紫色のハート(💜)に赤いハート(❤️)を引くと、✨の絵文字が近い意味になるということは紫色のハート(💜)の方が価値が高いのだろうか?
- 💙 - ❤️ ~= #goblue, #letsgoduke, #bleedblue, #ibleedblue, #worldautismawarenessday, #goduke, #beatduke, #autismspeaks, #autismawarenessday, #gobroncos, duke
- 💚 - ❤️ ~= #gogreen, loyals, #herballife, #happysaintpatricksday, 🍏, #stpats, 🍀, #jointhemovement, green, #hairskinnails, #happystpatricksday
- 💛 - ❤️ ~= 🌱 ,🍊 ,#springhassprung ,🔆 ,#springiscoming ,#springishere, #aprilshowers, #thinkspring, #hellospring, 🌻, #wildflower, #happyearthday
- 💜- ❤️~= ✨, 🌀, 🔮, 🌟, 💄, 🎀, faldc, 💎, brassy, topaz, peachy ,purple, #thinkpink,☁, sparkle, 🌿, shimmer, sparkles, kaleidoscope, periwinkle, 🍄, greenish
- 💖 -❤️ ~= gorl, 💮, cwd, s4s, aynmalik, spvm, ulee, 💧, 🈹, yulema, sfs, bvby, ɑnd, indirect, priv
- 💗 -❤️ ~= ulitzer, 🎀, peachy, february’s, tulle, mackz, kendall’s, curvy, faldc, #dancewear, strapless, 👗, ◽, floral
- 💌 - ❤️ ~= 📫, ℹ, 📬, 📮, ✉, 📩, 💳, 💻, 📦, paypal, 📧, item, ⏬, 📱, inquire, orders, payment, 📄, 📋, 📲, deposit
Word2Vecの弱点
そんなWord2Vecにも弱点がある。Word2Vecは対義語に弱いのだ。
理由は簡単で、「私はあなたのことが好きです」と「私はあなたのことが嫌いです」のようにが対義語は同じ文脈で登場するからだ。
なので、もし対義語が重要な意味をもつ機能をWord2Vecで開発しようと思うのであれば少し検討し直したほうが良いだろう。
Word2Vecの派生系や類似ツール
GloVe
Global Vectors for Word Representationな略らしい。Word2Vecよりも性能が高い。 学習が速く、大きなコーパスでも対応出来、小さなコーパス・小さなベクトルでもパフォーマンスが出る。
WordNet
WordNetは同義語・意味上の類似関係を分類した辞書(シソーラス)を構築することで、類義語を得ることが出来る。 Word2Vecのように自動で分類したり、演算出来るわけではない。
Doc2Vec
Word2Vecをベースにして、「単語」ではなく「文章」に意味を持たせてベクトル演算できるようにしたもの。単語ベクトルとパラグラフベクトルをつくり、平均化と結合、推定を経て構築される。
こうすることで、ニュース記事・口コミ・文学作品などの類似度を判定できるようになる。
Doc2Vecについて詳しくはこちら
Doc2Vecの仕組みとgensimを使った文書類似度算出チュートリアル
fastText
Facebookの人工知能研究所が公開した自然言語処理を高速化するライブラリだ。Word2Vecと同じく単語の分散表現を構築することができる。fastTextの開発者はWord2Vecを作った Mikolov氏 なのでGoogleからFacebookに転職して新しく公開したことになる。
表記ゆれや接頭語などにも強いアルゴリズムとなっている。詳しくはこちら
Facebookが公開した10億語を数分で学習するfastTextで一体何ができるのか
まとめ
いかがだっただろうか。Word2VecはWeb上のテキストを解析し、機械学習する上で最適だと考えている。
さらに、これまでコンテンツベースのレコメンドにおいてもさらなる飛躍を遂げる可能性を秘めている。 使い方次第では新しい自然言語処理における不可能だったタスクも出来るようになるかもしれない。
ぜひ、新しい使い方を考えてみてほしい。