Facebookでは一日500テラバイト以上のデータが新たに生み出される。その多くは画像・動画・テキストといった非構造データのはずだ。
日夜、ユーザー数を拡大させるためにこういったデータを解析し、知見を得ている。 そして、ユーザーをよりFacebookに滞在させるためにもユーザービリティの向上をしていかなければならないのだろう。
Facebookには「Facebook AI Research」という人工知能研究所がある。
先日、その研究所から「fastText」という自然言語処理ライブラリがオープンソースプロジェクトとして公開された。
このツールはいったい何をするものなのだろう?そして、どんなことが出来るのだろうかと思いまとめることにした。
この記事を読み終えた時には、
- fastTextとは何なのか
- fastTextを使って何ができるのか
- fastTextの使い方
が分かることだろう。さらに、今後Facebookの方向性も分かるかもしれない。
fastTextとは何なのか
公式の発表記事には、
Faster, better text classification!
と紹介されている。テキスト分類において大発明というよりは「より良く、より高速化」したものなのだろう。
では何をそんなに高速化したというのだろうか。
自然言語処理の学習を高速化するツール
fastTextは大きく分けて2つの高速化を達成しているようだ。
- 単語のベクトル表現をつくること
- テキストを分類すること
である。
単語のベクトル表現をつくるというのは、のちに紹介する「Word2Vec」のことだ。 ディープラーニングの素性に単語のベクトル表現を使えるため、自然言語処理に応用するときには抜群に相性が良いと考えられている。
そして、テキスト分類の速度も向上している。
これまで5日かかっていたタスクがたったの10秒で終了
こちらの実験結果を見て欲しい。

なんと、従来手法で数時間から数日かかっていたタスクがfastTextを使うとたったの10秒足らずで終わっている。
文字通り桁違いだ。そして精度も遜色ないレベルになっているのが分かる。
開発者や研究者はより素早く実験することができ、新しい手法をたくさん試せるようになる。
そして、発表ページによると
標準的なマルチコアCPUで10億語をたったの10分以内で学習する。 50万もの文を30万カテゴリに分類するのに5分もかからない。
と書かれている。凄い。速すぎる。
fastTextで取り組める3つのこと
fastTextが従来手法に比べて精度を落とさず高速に処理出来ることは分かった。 では、fastTextの利用用途は何だろうか?
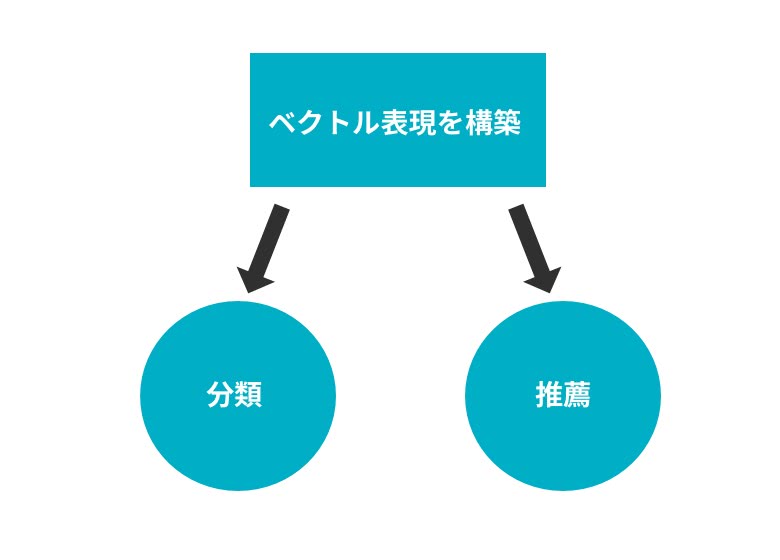
fastTextで出来る3つの全体像
元の技術を辿ると利用用途は大きく3つに分けることが出来る。
- ベクトル表現の構築
- 分類
- 推薦
である。
ベクトル表現を構築することは実用の一歩手前だ。開発者や研究者が素早く対象の単語や文章におけるベクトル表現をつくることによって、分類や推薦といったことに応用されていく。
以下では、同様の技術で開発された実用例を紹介していく。
Facebookはニュースフィードから釣り見出しを排除するためにfastTextをつくった?
Facebookでは8月3日に、クリックベイトと呼ばれるタイトルを誇張しクリックを誘発する「釣り記事」を撲滅するアルゴリズムを導入することを発表した。
具体的には、
「ベッドの下を覗くとなんとこれがいました。大ショック!」
「ニンニクを靴に入れてみた。その結果が信じられないことに!」
「犬が配達人に吠えた!その瞬間に・・・」
といった続きが気になるタイトルを付け、中身を見たら「ガッカリ」といったユーザー体験をニュースフィードから排除することが狙いだ。
ここに、fastTextが利用されている可能性が高い。公式のアナウンスにも、
文書分類は商業界でとても重要です。スパムやクリックベイドを排除することはひょっとしたら最も普及している応用例かもしれません。
と書いてあるので、fastTextが応用されていることは間違いないだろう。
Facebookの方針では、
- 続きが気になるタイトルをつける記事
- 誇張したタイトルでクリックさせ、期待したコンテンツではない記事
は排除対象となる。fastTextを使って人力でこういったコンテンツのデータセットを構築し、「釣り記事」判定をしていると思われる。
こちらは「分類」の例だ。
リクルートテクノロジーズでは、レコメンドに応用
こちらは「推薦」の例だ。
リクルートテクノロジーズの自然言語処理の適応事例というスライドを参考にすると
単語のベクトル表現を学習し、類似度を計算することで、アイテムレコメンドの精度が向上しCVRが31%改善したサービスと156%改善した事例があるのだそう。
更にその後、ユーザーの行動履歴を学習し、合成ベクトルを計算することでユーザーの嗜好をかなりの精度で理解するようになりCVRが27%改善したそうだ。
サイバーエージェントが実用化したAWAでのアーティストレコメンド

これも「推薦」の例だ。
サイバーエージェントとエイベックス・デジタルが提供しているAWAという音楽配信アプリでは、アーティストのレコメンドの機能に同様の技術を使っているようだ。
ユーザーの音楽視聴履歴から、類似アーティストを計算できるようにするartist2vecというベクトル表現を構築し、レコメンドに応用している。
音楽聴き放題サービスAWAにおけるレコメンド手法の検討という論文中には、
- 1.7%のレコメンド精度向上
- 4倍のレコメンドするアーティスト数
と、「新たな楽曲・アーティストに出会える」というサービスの思想に貢献したようだ。
Yahoo!はレシートメールの文章から製品をオススメする
これも「推薦」の例だ。

Yahoo!メールではメールのレシートに記載された内容を利用して、購買履歴を特定し広告ターゲティングするシステムを構築したようだ。
AmazonなどのECサイトのメールを判定し、単語や文章を利用している。
2900万人を対象に実験してみたところ、CTR(クリック率)が9%改善したそうだ。
◯2Vecを考えれば推薦に応用できる
「推薦」に関して言えば、同様のことは他の領域でも可能だろう。商品・アーティストといったものを、不動産・映画…としていけば同様のレコメンド方式を構築することは可能なはずだ。
従来手法よりも精度が高くなっているものも多いので、fastTextで高速化されればもっと施策を試しやすくなり応用先も広がると考えられる。
fastTextを安全に使うために必要な理論
そんなfastTextを使うためにはある程度知識があると役に立つだろう。まったく単語が分からなければ何をしていいか分からず、不安な気持ちになるはずだ。
そこで、特に不自由なく利用できるようになるために、最低限の知識を紹介する。
単語をベクトル表現化するWord2Vec
Word2Vecという単語を聞いたことがあるだろうか?
これは、単語の意味や文法を捉えるために単語をベクトル表現化したものだ。 単語をベクトル表現にしようと思うと、
「プログラマー」
という単語は、何らかの数値を持たないので単にラベル付することが多い。100万単語あるとしたら、100万次元のベクトルとして各要素をそれぞれの単語に割り当てるといった具合だ。
「イチロー、プログラマー、パリ、道頓堀、打つ」という5単語をワードセットとして、プログラマーを表すベクトルは以下のようになる。
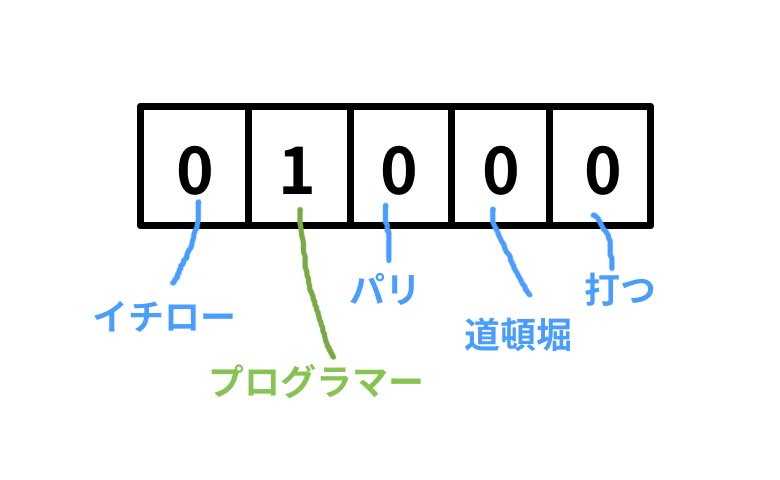
このように「プログラマー」の要素だけ1となっており、他の要素はすべて0とする。これを「one-hotベクトル」と呼ぶ。
でも、これだと同一単語かどうかの比較以外に演算処理しても全く意味が無い。そこで、もっと表現豊かなベクトルにして、演算処理までできるように単語の分散表現というものを提案した。
分散表現では通常200〜1000次元くらいのベクトルであり、先ほどのような各要素ごとにマッピングするのではなく、単語の定義によってベクトル化していく。
自分で定義する必要はないが、想像しやすくするために定義すると
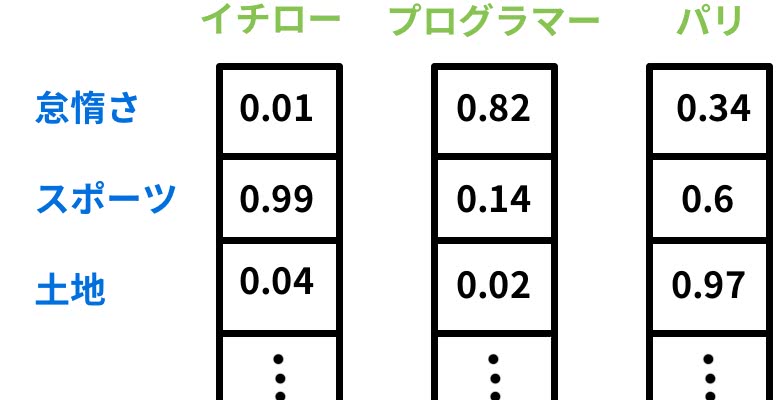
といった具合に抽象的な意味を表現するようなベクトルになっていると考えて欲しい。
こうすると何が嬉しいのかというと
- 「王様」- 「男」+ 「女」= 「女王」
- 「パリ」- 「フランス」+ 「日本」= 「東京」
のような演算をすることが出来るようになり、単語間の意味に基いて関係性を理解することができるようになる。 さらに、意味のあるベクトルをニューラルネットワークの入力層として利用することもできる。
詳しくは以下を参考にして欲しい。
Word2Vec:発明した本人も驚く単語ベクトルが持つ驚異的な力
ベクトル表現を構築するアーキテクチャ
では、そんな単語の意味ベクトルを構築するためにはどうすればいいのだろうか?
モデルを構築するためのアーキテクチャとしてfastTextにも備わっている2つのオプションがある。CBoWとSkip-gramだ。
CBoW
CBoWは、Continuous Bag-of-Wordsの略である。CBoWにおいて、文法と意味を学習していくことは、
文脈中の単語から対象単語が現れる条件付き確率を最大化することである。
つまり、前後の単語から対象単語を推測していくことになる。
ひとたびフルスピードで回り始めたなら、それを動かし続けるのに努力は必要ない。
という文を考えてみよう。 「続ける」を対象単語とすると入力層は、周辺5単語の
[ なら,、,それ ,を, 動かし, の, に, 努力, は, 必要]
の単語リストそれぞれのone-hotベクトルを入力として、真ん中の「続ける」が来る確率を最大にするように学習させたい。
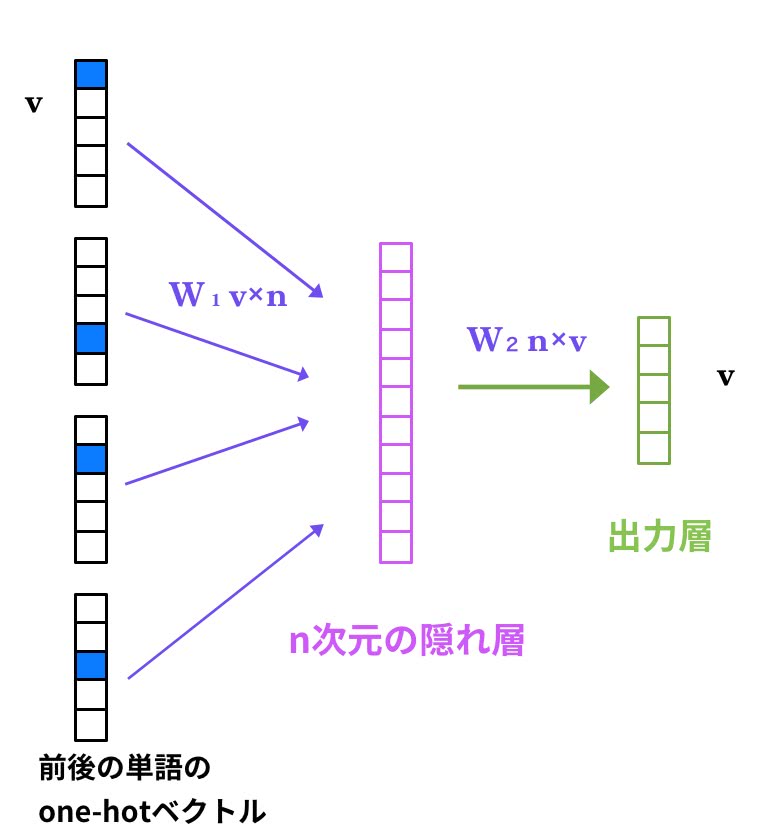
そこで、このような単層ニューラルネットワークを構築するとW2の重み行列がスコアを計算するためのモデルとなる。
Skip-gram
Skip-gramはCBoWの逆だ。単語からその周辺単語を予測する。Skip-gramにとって意味・文法の獲得は、
出力層における周辺単語予測のエラー率の合計を最小化することである。
先ほどの例だと、「続ける」から[ なら,、,それ ,を, 動かし, の, に, 努力, は, 必要]を予測することだ。
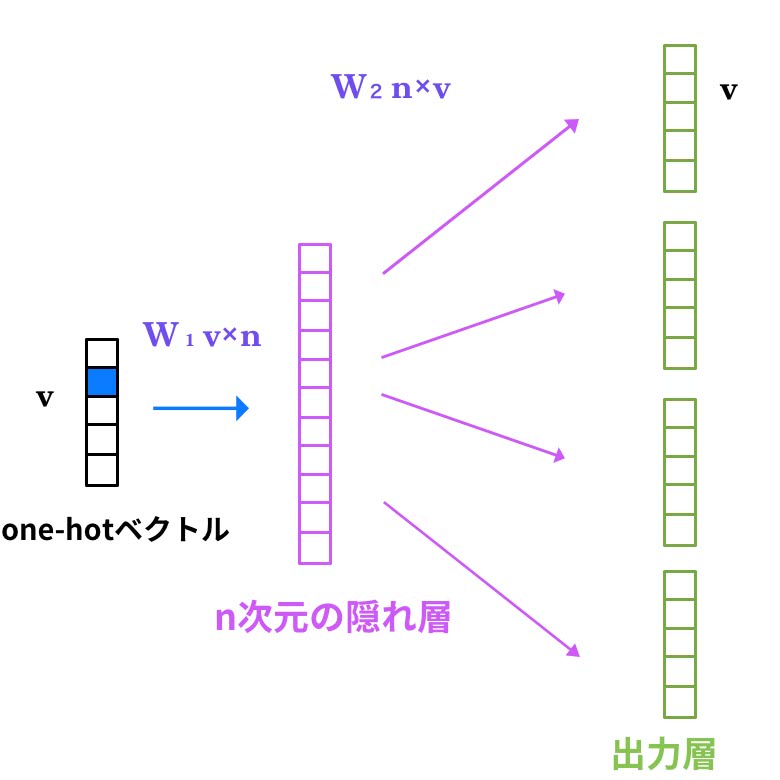
Skip-gramは学習データが少なくてもある程度の精度がでるとされている。 そして、CBoWよりもSkip-gramの方が実験では意味的な精度が高くなり、構文の精度ではあまり大差はないようだ。
fastTextを使ってみよう
それではfastTextを使ってみよう。fastTextはGitHubでオープンソースとして公開されているので無料で利用できる。
fastTextをインストールする
以下のコマンドでダウンロードすると実行できるようになる。
$ git clone git@github.com:facebookresearch/fastText.git
$ cd fastText
$ make
$ easy_install cython
$ pip install fasttext
単語のベクトル表現を構築しよう
Tweetデータの収集
学習するためのデータセットを準備するために、Twitterからツイートを取得してみる。SparkでTwitter Streamingからツイートを収集してみよう。 spark-twitter-stream-exampleというScalaプロジェクトがあったのでちょっと修正して使えるようにする。 Twitterのトークン等が必要になることに注意しよう。
build.sbtにkuromojiを追加して形態素解析できるようにする。
name := """spark-twitter-stream-example"""
version := "0.0.1"
scalaVersion := "2.11.6"
resolvers += "Atilika Open Source repository" at "http://www.atilika.org/nexus/content/repositories/atilika"
libraryDependencies ++= Seq(
"com.atilika.kuromoji" % "kuromoji-ipadic" % "0.9.0",
"org.apache.spark" % "spark-streaming_2.11" % "1.2.1",
"org.apache.spark" % "spark-streaming-twitter_2.11" % "1.2.1"
)TweetExampleは日本語を取得して形態素解析するように修正する。
package me.baghino.spark.intro
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.twitter.TwitterUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import twitter4j.Status
import java.util.regex.{Matcher, Pattern}
import com.atilika.kuromoji.ipadic.{Tokenizer, Token}
import scala.collection.JavaConversions._
object TwitterExample extends App with TwitterExampleBase {
// Initialization and processing functions are defined in the TwitterExampleBase class
// Let's extract the words of each tweet
val textSentences: DStream[TweetText] =
tweets.map(_.getText).map(x => {
x.replaceAll("http(s*)://([a-zA-Z0-9_¥-¥./]*)*", "").
replaceAll("¥¥uff57", "").
replaceAll("@[a-zA-Z0-9_]+[:]*", "").
replaceAll("#.+", "").
replaceAll("【.+】", "").
replaceAll("¥n", "").
replaceAll("RT ", "").
trim
})
val japaneseTextSentences: DStream[TweetText] =
textSentences.filter(x => {
val japanese_pattern : Pattern = Pattern.compile("(?:[ぁ-ヶ]|[亜-黑]|ー)+")
if (japanese_pattern.matcher(x).find())
true
else
false
})
val tokenizer = new Tokenizer()
val tokenizedWords =
japaneseTextSentences.
map(tokenizer.tokenize(_).toList.map(x => x.getSurface()).mkString(" "))
tokenizedWords.print
tokenizedWords.saveAsTextFiles("output/tweet")
// Now that the streaming is defined, start it
streamingContext.start()
// Let's await the stream to end - forever
streamingContext.awaitTermination()
}$ sbt run
として、数十分から数時間待つと十分なデータ量が手に入る。
そして、収集したデータを最後にPythonでfastTextが読み込める形にしよう。スペース区切りにすればいいようだ。
# -*- coding: utf-8 -*-
import os
from os import listdir, walk
from os.path import join, isfile
def read_file(directory, filename):
for line in open(join(directory, filename), 'r'):
yield line
def is_tweet_data(directory, name):
if name.startswith('part'):
return isfile(join(directory, name))
else:
return False
def read_directory(directory):
if os.path.exists("{}/_SUCCESS".format(directory)):
files = [f for f in listdir(directory) if is_tweet_data(directory, f)]
for f in files:
yield read_file(directory, f)
def read_inputs():
for (dirpath, _, _) in walk('output/'):
for rf in read_directory(dirpath):
for line in rf:
print(line.strip(), end=" ")
if __name__ == '__main__':
read_inputs()これで
$ python collect.py > tweet.txt
とするとfastTextが読める形になる。
単語のベクトル表現の構築
これでようやく辞書構築することができる。先ほど作ったデータをinputとして
$ ./fasttext skipgram -input data/tweet.txt -output result/tweet -lr 0.025 -dim 100 -ws 5 \
-epoch 1 -minCount 5 -neg 5 -loss ns -bucket 2000000 -minn 3 -maxn 6 \
-thread 4 -t 1e-4 -lrUpdateRate 100
lrUpdateRate 100
Read 0M words
Number of words: 12791
Number of labels: 0
Progress: 100.0% words/sec/thread: 113578 lr: 0.000001 loss: 3.042181 eta: 0h0m
Train time: 2.000000 sec
手元のMacBook Proで1万2791単語をたったの2秒で学習した。
IPythonで確認
IPythonでチェックしてみよう。
$ ipython
In [1]: import fasttext
In [2]: model = fasttext.load_model('result/tweet.bin')
In [3]: def similarity(v1, v2):
from scipy import linalg, mat, dot
return dot(v1, v2) / linalg.norm(v1) / linalg.norm(v2)
...:
In [4]: sorted(model.words, key=lambda x: similarity(model[x], model['フォロー']), reverse=True)[:5]
Out[4]: ['フォロー', 'フォロ', 'フォロリク', 'フォロワ', 'リフォロー']
In [5]: sorted(model.words, key=lambda x: similarity(model[x], model['ディズニー']), reverse=True)[:5]
Out[5]: ['ディズニー', 'ディズニーランド', '年越し', 'ハロ', 'ディオ']
In [6]: sorted(model.words, key=lambda x: similarity(model[x], model['こんにちは']), reverse=True)[:5]
Out[6]: ['こんにちは', 'こんにちわ', 'こんばんは', 'こんばんわ', 'なせ']
Twitterでの頻出単語だとより多くのデータを学習しているので、精度高く近い単語が得られそうだ。「フォロー」という単語のコサイン類似度を取ってみると、「フォロリク」や「リフォロー」などTwitterでよく利用される単語が出てきた。ディズニーもなんとなく(?)似通った単語になっている。 「こんにちは」も同じような文脈で使われそうな単語が取れた。
もっと大量のデータで学習するとより幅広い単語にも対応できそうだ。
文書分類に挑戦する
livedoorのニュースコーパスを使ってみよう。
リンク先からldcc-20140209.tar.gzという名前のファイルをダウンロードしてdata/textディレクトリに展開する。
今回もfastTextで読める形に直そう。fastTextのレポジトリにあったexampleを参考に
__label__ラベル名 , 単語をスペース区切りにした本文
を行とする。
livedoor.pyというファイル名で以下のコードを書いた。
# -*- coding: utf-8 -*-
import MeCab
import os
from os import listdir, walk
from os.path import join, isfile
mecab = MeCab.Tagger('mecabrc')
labels = [
'dokujo-tsushin',
'it-life-hack',
'kaden-channel',
'livedoor-homme',
'movie-enter',
'peachy',
'smax',
'sports-watch',
'topic-news'
]
def tokenize(text):
node = mecab.parseToNode(text.strip())
tokens = []
while node:
tokens.append(node.surface)
node = node.next
return ' '.join(tokens)
def is_post(directory, filename):
if isfile(join(directory, filename)):
if filename != 'LICENSE.txt':
return True
return False
def read_content(directory, filename):
body = [l.strip() for i, l in enumerate(open(join(directory, filename), 'r')) if i > 1]
text = ''.join(body)
return tokenize(text)
def read_posts(directory):
if os.path.exists(join(directory, 'LICENSE.txt')):
files = [f for f in listdir(directory) if is_post(directory, f)]
for f in files:
yield read_content(directory, f)
def read_corpus():
for (dirpath, _, _) in walk('data/text/'):
label_name = os.path.basename(dirpath)
for post in read_posts(dirpath):
print('__label__{} , {}'.format(labels.index(label_name), post))
if __name__ == '__main__':
read_corpus()$ python livedoor.py > data/livedoor.txt
として実行しよう。
そして、訓練用のデータセットと学習用のデータ・セットに分ける。 今回は 9 : 1 で分けた。
そして、rand_split.pyというファイル名で以下のコードを実行する。
import numpy as np
import os
from os.path import join
def append_newline(filename, line):
with open(filename, 'a') as file:
file.write(line)
def split_random(filename):
dirname = os.path.dirname(filename)
comps = os.path.basename(filename).split('.')
train_name = '{}_train.{}'.format(comps[0], comps[1])
test_name = '{}_test.{}'.format(comps[0], comps[1])
for l in open(filename, 'r'):
choice = np.random.choice([True, False], p=[0.9, 0.1])
if choice: # write train
append_newline(join(dirname, train_name), l)
else: # write test
append_newline(join(dirname, test_name), l)
if __name__ == '__main__':
split_random('data/livedoor.txt')$ python rand_split.py
これで学習の準備が整ったのでfastTextを使ってみよう。
今回は、合計でも7000記事程度しかないのでepochを上げて学習させてみる。
$ ./fasttext supervised -input data/livedoor_train.txt -output result/livedoor -dim 10 -lr 0.1 -wordNgrams 2 -minCount 1 -bucket 10000000 -epoch 100 -thread 4
Read 4M words
Number of words: 72636
Number of labels: 9
Progress: 100.0% words/sec/thread: 2135610 lr: 0.000001 loss: 0.220120 eta: 0h0m
Train time: 56.000000 sec
$ ./fasttext test result/livedoor.bin data/livedoor_test.txt
P@1: 0.947
R@1: 0.947
Number of examples: 771
それでも56秒で学習は終わった。さらに94.7%の精度で分類することができたようだ。
まとめ
ここまで、Facebookが公開したfastTextというライブラリを使って分散表現を作る方法と簡単な解説をした。 fastTextは自然言語処理におけるビッグデータを処理するタスクを実用レベルにまで高速化したものだ。
ビッグデータは幅広いニーズや特徴を掴みに行くことができる。さらに学習も速く、分類処理もリアルタイムで返せるとなると利用価値が高いのではないだろうか。
自然言語処理とベクトルを使うことで、ユーザーの趣味・趣向に合った推薦やスパムといった悪意のあるデータを取り除くこともできる。
サービス運営者としては、こういった技術を活用していくことでコスト削減やユーザーをより安心に快適な環境を整えてあげるという価値提供できる。 今後、データ活用こそ企業の競争力になるはずだ。
是非とも、自然言語データ・行動データを活用して今後の役に立てて頂きたい。
参考
- fastText
- Bag of Tricks for Efficient Text Classification
- Enriching Word Vectors with Subword Information
- Efficient Estimation of Word Representations in Vector Space
- The amating power of word vectors
- E-commerce in Your Inbox: Product Recommendations at Scale
- リクルート式 自然言語処理の適応事例
- 音楽聴き放題サービスAWAにおけるレコメンド手法の検討