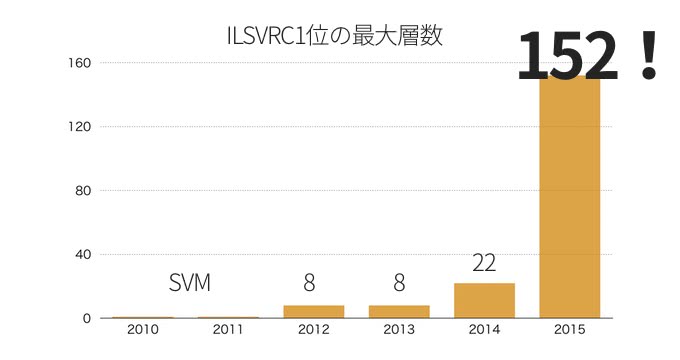
2012年のILSVRCという物体認識のコンペティションでディープラーニングのアルゴリズムが圧勝してから、各所で活用事例が出てくるようになってきた。
DeepMindのAlphaGoは囲碁の世界で圧勝するようになり、人間と限りなく近い声を出力するようになった。
では、レコメンド技術への応用はどうなっているのだろう?この記事では
- レコメンドへのディープラーニングの応用事例
- レコメンドへの応用アルゴリズム
を解説していく。
レコメンドにDeep Learningは使えるか
実は、情報推薦の分野でDeep Learningを活用することはそれほど研究すらもされてこなかったのだ。ユーザーがアイテムにつける評価や行動は全体のデータの一部でしかなく、ニューラルネットワークと相性が悪かったのだ。それだけではなく、ユーザーによっては全部に高評価をつける人がいることなどのデータの偏りが多いことも原因の一つだ。
そんなこともあり、それほどニューラルネットワークをレコメンドに応用しようという研究はされてこなかったが、ここ数年でディープラーニングが飛躍的な成果を収め始めたことによって研究が進み、精度向上に貢献し始めている。
サービスのレコメンドに応用されていくディープラーニング
すでに実サービスで運用事例が出ているので紹介しよう。
Spotify
Spotifyはスウェーデンで生まれた音楽ストリーミングサービスだ。
Spotifyではディープラーニングを利用するまで、協調フィルタリングを活用していた。協調フィルタリングというのは、「何曲も同じ曲を聴いている人同士は、似たような音楽の趣味をしている。」という仮説のもとでユーザーの再生履歴から曲のレコメンドをする。
つまり、この方式では曲そのものは見ていない。
そして、この方式にも欠点がある。ユーザーの再生履歴が多い「人気の曲」ばかりがレコメンドされるようになる。本質的に「新しい曲」や「人気はないけど好きな曲」には出会いにくいのだ。
そこで、曲の信号を解析して類似度を学習し、レコメンドするコンテンツベースの手法を取り入れたのだ。
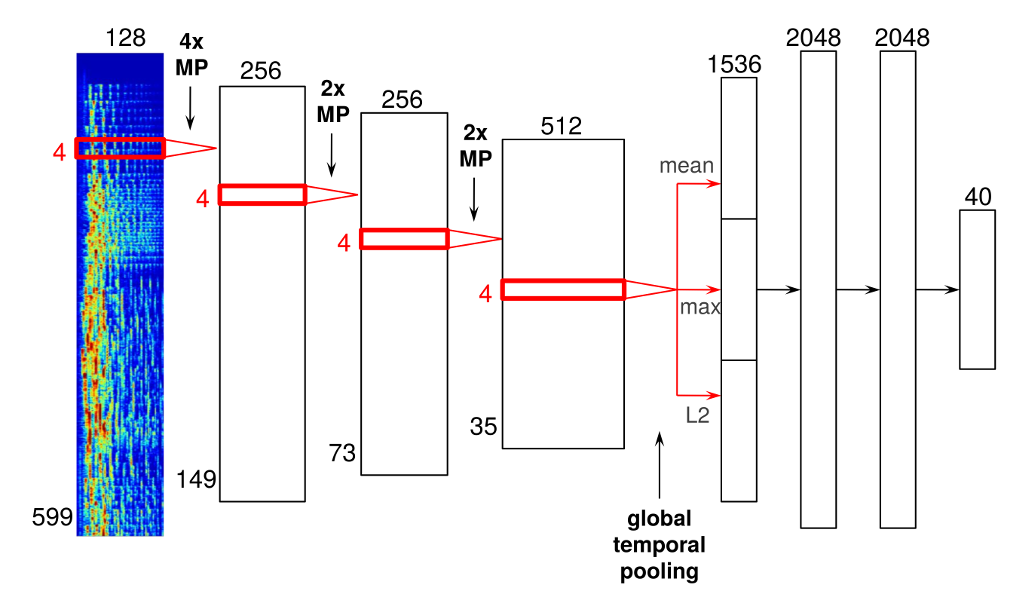
周波数を表現するメルスペクトログラムを入力値としている。この入力値をvector_expという協調フィルタリングの一種で算出した値を学習させて、類似した楽曲を推薦するようにする。
こうすると、データの無い「新しい曲」や「人気のない曲」のレコメンドも出来るようになる。

こちらが、ニューラルネットワークが学習した一層目を可視化したものだそうだ。ピッチが上がったり下がったりしていることを表していて、「人間の声」を検出していると判断できるそうだ。
LINE
LINEでは、スタンプのレコメンドにDeep Learningを使っている。
普段は、ベイズ推定を使ったレコメンド手法を使っていて
- 好ましいスタンプをよく使う
- 最近購入したスタンプをより好む
この2つの仮説に基いてレコメンドしているらしい。
このアルゴリズムを導入したことで、ランキングが1000位以降の販売数が大きく上昇し、CTRは約9倍になったそうだ。
Spotifyの例のように全くデータが存在しないスタンプに対してはディープラーニングを使って画像の類似度の特徴量を出力し、 好ましいスタンプと似たスタンプをレコメンドしているらしい。
YouTube
ボストンで開催された10th ACM Conference on Recommnder SystemでGoogleはYouTubeでのレコメンドにディープラーニングを応用した発表をした。
Googleでは、Deep Learningの活用を様々なプロダクトで推進しているが、YouTubeは一般的な問題解決のためにディープラーニングを活用するという、根本的なパラダイム変化を経験してしまったようだ。と論文に書かれている。そして、劇的なパフォーマンスの改善を達成することができたそうだ。
YouTubeのDeep Learningは2段階に渡っている。「候補抽出」と「再生時間の予測」だ。
候補抽出
まず、ユーザーが再生してくれそうな動画リストを数百程度に絞込をする。
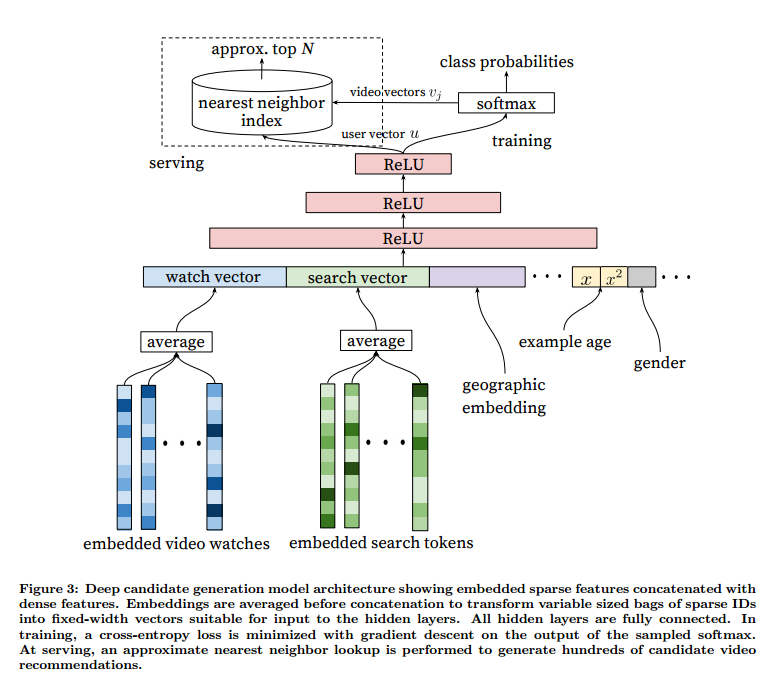
入力値には自然言語処理のCBoWを参考に動画の視聴履歴、検索クエリ、位置情報の分散表現を構築して平均化したものを入力値としている。
CBoWについてはこちらで解説しているので参考にしてほしい。
YouTubeでは、チャンネルや話題になっている動画がよく見られるのか「最近アップロードされた動画」のほうが好まれる傾向にあるらしい。機械学習システムでは一般的に、学習したものから予測するため、どうしても過去に見た動画のバイアスが強くかかってしまう。
そこで、時刻を考慮に入れて次に見るであろう動画の特徴ベクトルを予測し、インデックス済みの動画から近傍探索で数百まで絞り込む。
再生時間の予測
数百までに動画の候補リストが出来上がったら、次は「再生時間を予測」する。過去のデータから再生されたものは再生時間を、再生していないものは0を出力として学習する。
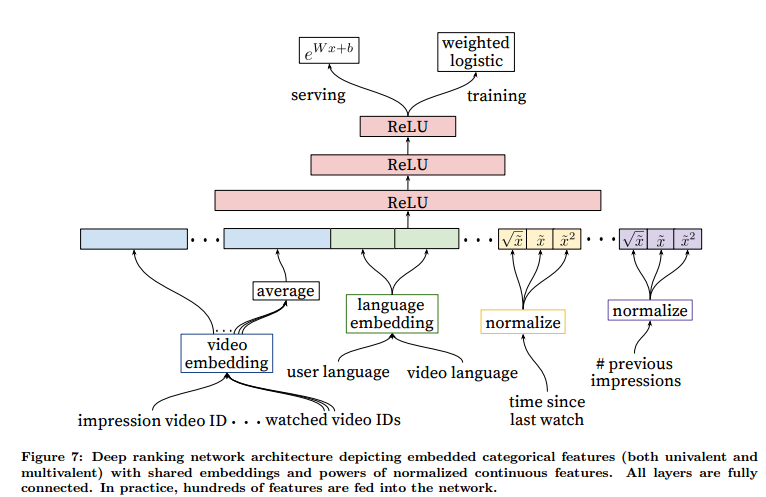
なぜ、再生時間なのかというとタイトルやサムネイルを誇張したりしている「釣り動画」を排除するためだ。タイトルと中身がそぐわないものはユーザーは再生してもすぐに離れるため、ユーザーの再生時間を予測することで有益な動画をレコメンドするようにしている。
こちらの記事でも紹介したが、Facebookは釣り記事を排除するために、自然言語処理の分類器を開発した。今後、タイトルやサムネイルで誇張した「釣り」は撲滅される運命にあるのかもしれない。
Google Play
もう、Appleは完敗かもしれない。Google PlayはアプリのレコメンドにDeep Learningを使い始めた。アプリのインストール率を高めることに成功したようだ。
Wide & Deep Learning for Recommender Systemsという論文で発表されている。
このモデルでは、人間がやっているような「記憶」と「一般化」を再現している。
人は「ハトは飛ぶ」や「スズメは飛ぶ」と記憶することや、教えられなくても「羽を持つ動物は飛ぶ」と一般化して考えることもできる。
記憶
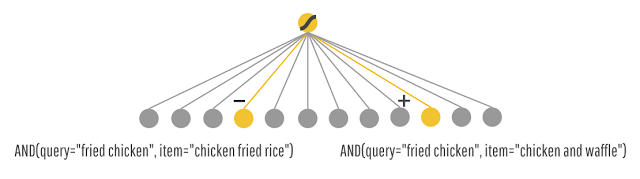
まず、検索クエリとアプリとの関連性を記憶していく。「ポケモン」と検索すると、「Pokemon GO」のアプリがよくダウンロードされているということを徐々に記憶していくのだ。
一般化
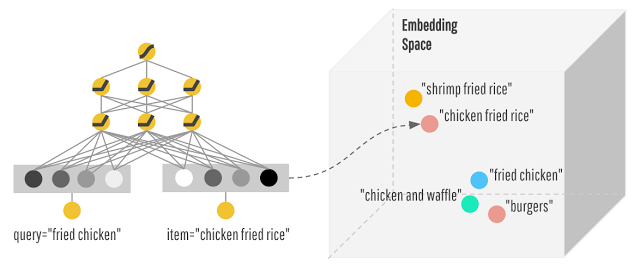
そして、深層学習を使って検索クエリとアイテムの分散表現を学習して、汎化を試みる。ポケモンとPocketは違うらしいとか学ぶようになる。
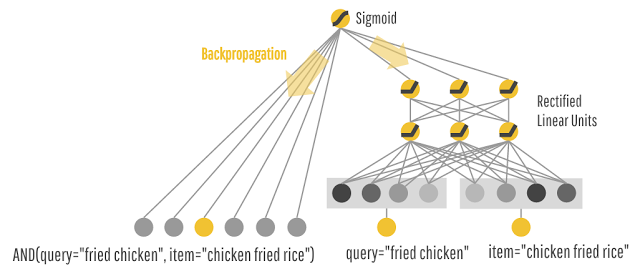
そして、最後に記憶モデルと汎化するモデルを一緒にする。汎化しすぎてもいい結果にならない。こうすることで、記憶と汎化の良いとこ取りをしているそうだ。
こちらはGitHubにTFLearn実装が公開されているので参考にしながら実装することもできる。
また、こちらにWide & Deep Learningのチュートリアルもあるので参考になるだろう。
まとめ
レコメンドにも広がっているDeep Learningの紹介をした。
気づかないうちにDeep Learningは徐々にプロダクションに投入されている。
他社プロダクトが急激に利用者を伸ばしていたり、滞在時間が伸びているのはAIを導入したことが要因なのかもしれない。