2015年のImageNetコンペティションとCOCOセグメンテーションの最良モデルとしてDeep Residual NetworksがMicrosoft Researchから提案され、最大1000層以上の深いニューラルネットワークを構築することが可能となった。
本記事では、
- Residual Networkとは何か
- Residual Networkのチューニング方法
- Residual Networkの派生モデル
をまとめた。
Residual Network(ResNet)とは
ResNetは、Microsoft Research(現Facebook AI Research)のKaiming He氏が2015年に考案したニューラルネットワークのモデルである。
CNNにおいて層を深くすることは重要な役割を果たす。層を重ねるごとに、より高度で複雑な特徴を抽出していると考えられているからだ。
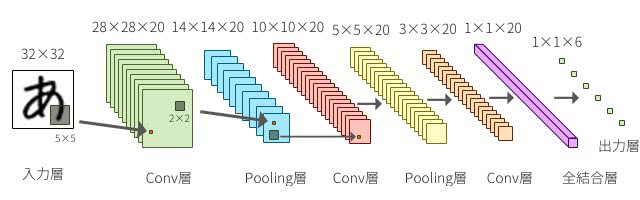
Convolution層はフィルタを持ち、Pooling層と組み合わせて何らかの特徴を検出する役割を持っている。低・中・高レベルの特徴を多層形式で自然に統合し、認識レベルを強化することができる。
2014年の画像認識の分野でトップを争うImageNetコンペティションにおいて、1位と2位を飾ったモデルはVGGNetと呼ばれている。
Very Deep Convolutional Networks for Large-Scale Image Recognition
こちらがその論文である。層の数を16層や19層まで深くしたのだ。それでVery Deepと名付けられていた。
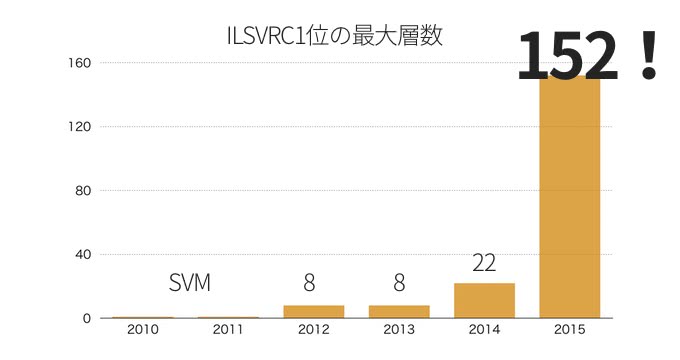
検出部門で勝利を飾ったGoogLeNetでも22層だった。
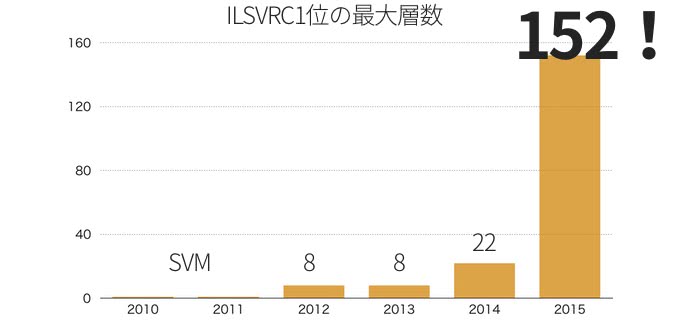
こちらが2010年から始まったImageNetコンペティション部門1位となったモデルの最大総数である。2015年においてはResNetで152層まで深くすることが出来た。Very Deepの16、19層やGoogLeNetの22層がものすごく浅く感じてしまう。
ResNetのアイデア
ResNet以前も層を更に深くする試みはあったものの、思い通りに学習が進まなかった。
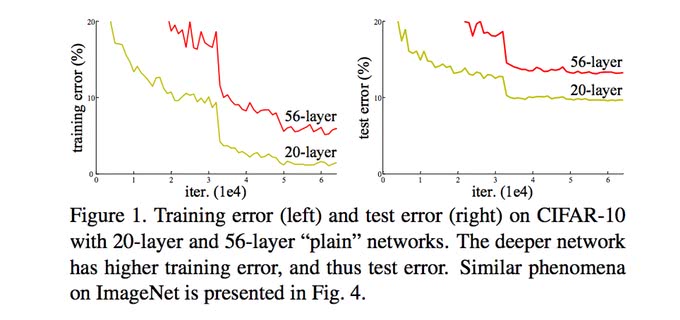
単純に層を深くすると、性能が悪化することが報告されていた。
では、ResNetはどのようにしてニューラルネットワークのモデルを深くすることを可能にしたのだろうか?
ResNetのアイデアはシンプルで、「ある層で求める最適な出力を学習するのではなく、層の入力を参照した残差関数を学習する」 ことで最適化しやすくしている。
つまり、 が学習して欲しい関数だとすると、入力との差分は となり、 を学習するように再定義する。
Shortcut Connectionの導入
では、どのように実現したらいいのだろう?
ResNetでは、残差ブロックとShortcut Connectionを導入することで実現している。一般的なネットワークが以下のような図だとしたら、
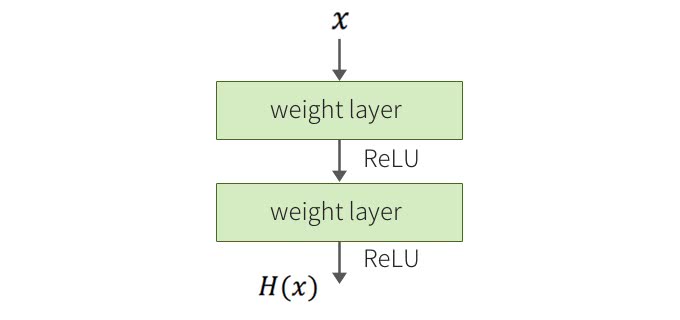
残差ブロックはこうなる。
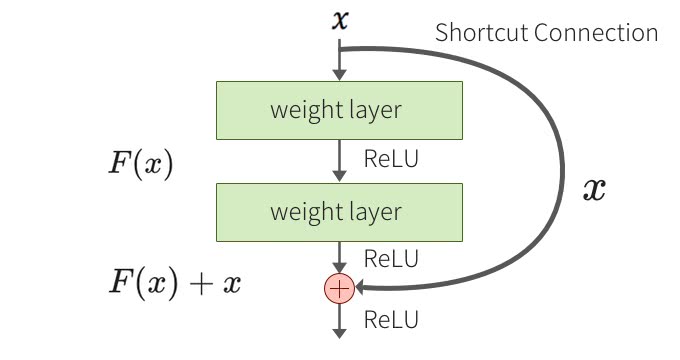
残差ブロックでは、畳込み層とSkip Connectionの組み合わせになっている。2つの枝から構成されていて、それぞれの要素を足し合わせる。残差ブロックの一つはConvolution層の組み合わせで、もう一つはIdentity関数となる。
こうすれば、仮に追加の層で変換が不要でもweightを0にすれば良い。
残差ブロックを導入することで、結果的に層の深度の限界を押し上げることができ、精度向上を果たすことが出来た。
Bottleneckアーキテクチャ
Residual Blockには2つのアーキテクチャがある。
- Plainアーキテクチャ
- Bottleneckアーキテクチャ
で、こちらがPlainアーキテクチャとなっている。
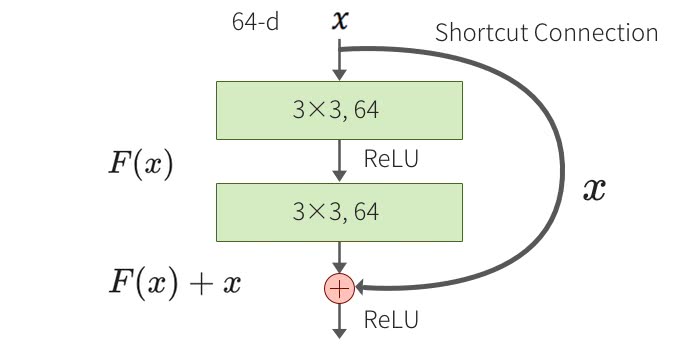
3×3のConvolution層が2つある。そして、こちらがBottleneckアーキテクチャで残差ブロックの中が少しだけ変わっている。
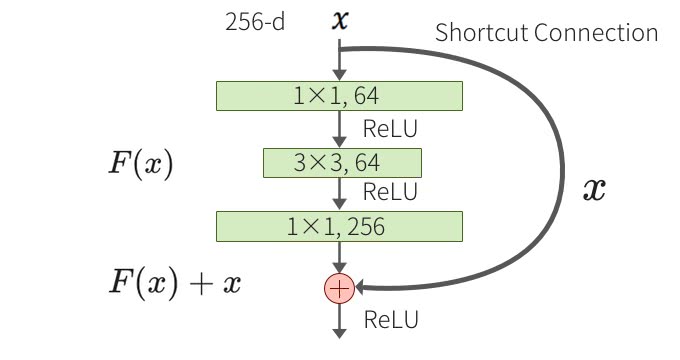
この2つは同等の計算コストとなるが、Bottleneckアーキテクチャの方はPlainよりも1層多くなる。1×1と3×3のConvolution層で出力のDepthの次元を小さくしてから最後の1×1のConvolution層でDepthの次元を復元することからBottleneckという名前がついている。
ResNetの最適化ベストプラクティス
それでは、実際の実装におけるパラメータのチューニングポイントを紹介する。FacebookのTorchのブログにあるTraining and investigating Residual Netsと、ResNetの派生モデルの提案
を参考にしている。
Optimizerの選定
原論文には、SGD+Momentumを使うと書かれていたがTorchのブログでもこれが最良の結果となったようだ。
- RMSprop
- Adadelta
- Adagrad
- SGD+Momentum
で調査したところ、唯一SGD+Momentumだけが0.7%を下回るテストエラーとなったそう。
Batch Normalizationの位置
Batch Normalizationを足し合わせる前に入れるか、足し合わせた後に入れるかをTorchのブログで検証している。
Batch Normalizationについてはこちら:
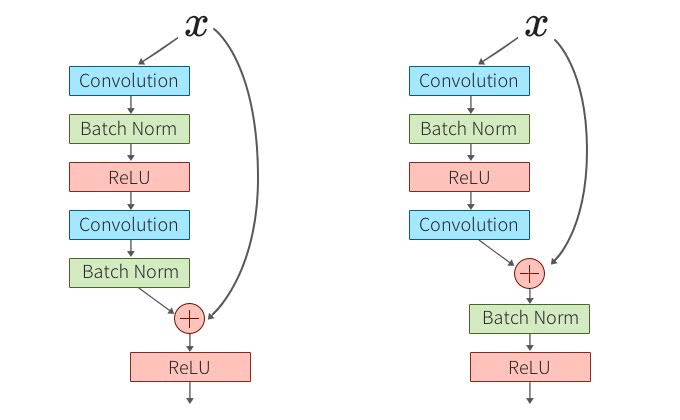
元は左のBatch Normalizationを足し合わせる前に入れるタイプだが、右側の後に入れるタイプにするとどうなるだろうか?
この検証結果は、Batch Normalizationを後に入れた場合、著しくテストデータにおける性能が落ちた。理由は、最後にBatch Normalizationをすれば残差ブロック全てが正規化されて良いように見えるが、実際にはSkip Connectionの情報をBatch Normalizationが大きく変更して情報の伝達を妨げてしまうからだそうだ。
Post Activation vs Pre Activation
次は、Identity Mappings in Deep Residual Networksにおいての検証で下図のように元の構成が左のようになっていた場合、Activation関数とBatch Normalizationの位置を前方に持ってくるとどうなるだろうか?
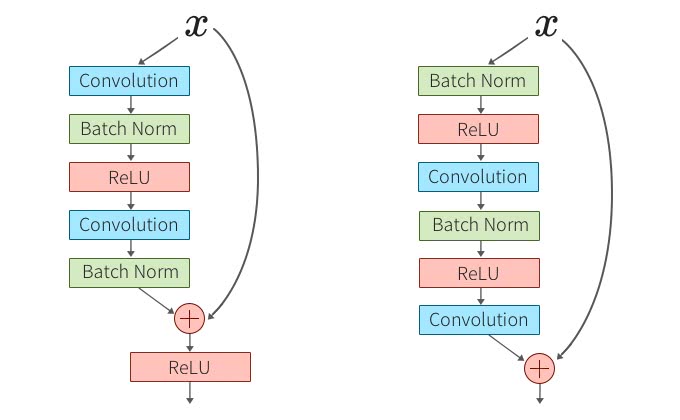
この実験では、層の数が増えれば増えるほど顕著にActivation関数とBatch Normalizationを前に持ってきた後者のほうが良い結果となったそうだ。
画像認識の分類タスクImageNetにおいて、200層のResNetを使った実験ではエラーレート1.1%の改善をしている。
さらにメリットとして、Pre Activationの場合Batch Normalizationを前方に持ってくることで正則化の役割が強くなったという結果が報告されている。
Wide Residual Network
最後はWide Residual Networkで、こちらはBatch NormalizationやActivation関数の順序ではなく、フィルタの数を増やしてネットワークを”広く“したらどうなるのか?
ということを検証したものだ。以下の表を見て欲しい。
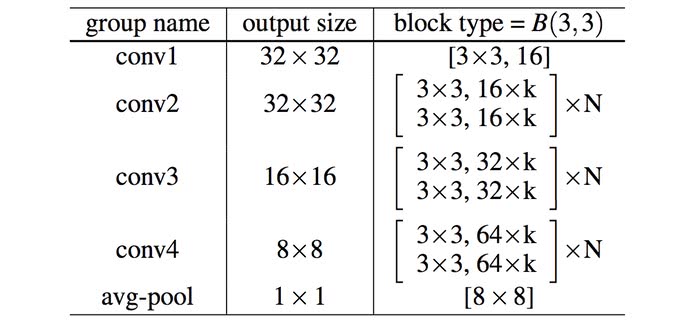
が残差ブロックの数となっていて、が”広さ”係数だ。[]の中のパラメータは、フィルタサイズ,フィルタの数で広いネットワークでは、フィルタの数が大幅に増えることになる。
こうすることで、広さの係数を10倍にすると1000層の”薄い”ResNetと同等のパラメータ数を持つこととなり、さらにGPUによる処理をフルに活かすことができるようになる。
そして実験結果では、”薄い”ResNetよりも高い精度を50分の1の層数で、半分の時間の訓練時間になったそうだ。
そしてさらに、Convolution層の間にDropoutを入れることで更なる性能向上を果たすことができたということが報告されている。
Dropoutについてはこちら:
以下の図のように、最後のConvolution層の手前にDropoutを入れる。
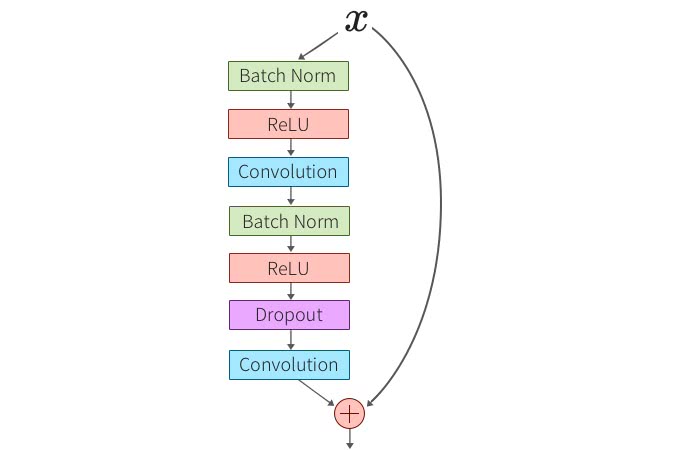
広さの係数10で28層のWide ResNetにDropout率30~40%程度適用すると高い精度となったそうだ。
まとめ
ResNetでVery Deepよりもさらに深い層を学習することが可能になった。そして、パラメータのチューニングやライブラリを使った実装のお役に立てるよう派生モデルのResNetを紹介した。
ResNetの実装や方針の参考にして欲しい。