Pythonでデータサイエンスをしている人は必ずと言っていいほどPandasとNumPyを使用していると思います。Pandasは、NumPyを利用してさらにAPIを拡張し、使いやすくしたものです。
本記事では
- PandasとNumPyの違い
- PandasとNumPyのデータ型の変換方法
について解説します。
PandasとNumPyとの違い
PandasとNumPy、どちらもデータを扱うことに特化していますが、その扱うデータの種類で違いが発生します。
NumPyは計算が速い
NumPyが得意とするのは基本的には多次元配列の数値データが対象です。これ以外のデータ型を処理する関数をほとんど持っていません。
しかしながら、その特異性からNumPyはPythonで弱点とされてきた計算速度の遅さを克服しています。PandasはNumPyを利用して使いやすくしたライブラリです。したがって、一般的にはPandasの抽象化や関数呼び出しのオーバーヘッドが発生する分NumPyを素で利用したほうがパフォーマンスは上がりやすい傾向にあります。
数値演算の処理速度を最適化したい場合には、Pandasだけでは難しいかもしれません。
Pandasは扱うデータが幅広い
Pandasは、NumPyを応用して多次元配列以外の実世界でで扱うようなCSVやSQL、エクセルなどのデータソースの入出力・データ加工をしやすくしています。
このデータの中身は数値データであろうが時系列データであろうが文字列であっても、あらゆるデータを処理する関数が一通り揃っています。
さらに、PandasではIndex機能が非常に充実しており、1つ1つの値に対するラベルづけが簡単に行えます。これらのラベルを元にグループ分けをして値の処理を行ったりすることもできるので、いわゆるデータの前処理に非常に適しています。
PandasのIndexについては以下の記事を参考にしてください。
PandasのIndexの理解と使い方まとめ /features/pandas-index.html
PandasはSQLと似た操作が揃っている
また、PandasではSQLと似た操作関数が揃っているため、データベースをSQLで扱っている人でもPandasは比較的すぐに使えるようになると思います。
Pandasは集計関数などの統計処理に強い
統計的処理に非常に強く、クロス集計なども簡単に行うことができます。
例として、Kaggleのチュートリアル問題で有名なTitanicのデータを使ってみます。CSVデータはこのページからダウンロードしてください。
In [1]: import pandas as pd
In [9]: df = pd.read_csv("train.csv")
In [10]: df = df.dropna() # 例の表示のためなのでとりあえず欠損値は全部落とす
In [12]: pd.pivot_table(df, values="Survived", index="Sex", columns="Age")
Out[12]:
Age 0.92 1.00 2.00 3.00 ... 65.00 70.00 71.00 80.00
Sex ...
female NaN NaN 0.0 NaN ... NaN NaN NaN NaN
male 1.0 1.0 1.0 1.0 ... 0.0 0.0 0.0 1.0
[2 rows x 63 columns]
また、groupby関数で作成したグループごとに平均を求めることも可能です。
In [16]: df.groupby('Survived').mean()
Out[16]:
PassengerId Pclass Age SibSp Parch Fare
Survived
0 402.983333 1.216667 41.350000 0.366667 0.450000 64.048262
1 480.918699 1.178862 32.905854 0.512195 0.487805 85.821107
このように、Pandasは元の不完全なデータ、整っていないデータをそのまま入れ込むことができ、それを整った形でみやすく、処理しやすい形に変換することが非常に得意です。
Pandasは時系列データに強い
また、Pandasは時系列データを扱うことができ、時系列を扱う関数も非常に充実しています。実務で扱うデータは実際には時系列データが多いのではないかと思います。
Pandasの作りとしては1つ1つのデータ自体はNumPyのndarrayをベースにしていますが、行えることの幅が非常に広くなっています。
とりあえずデータを与えられたらPandasのDataFrameに格納してから色々操作を施すのがよいでしょう。
Pandasは様々なインタフェースとの互換性を持つ
Pandasはcsvファイルやjson形式、excelのファイルなど様々な形態のデータを読み込むことができ、出力も同様に行うことが可能です。
また、Apache Sparkと連動させることで計算速度を飛躍的に向上させることもできます。
参考サイト
実際のデータ分析での流れ
では、実際のデータ分析ではどのような流れで処理されることが多いのでしょうか。
機械学習をする場合、元データが存在した場合には、それをまずはPandasのDataFrameに落とし込んで加工します。そして、DataFrame内の必要なデータをNumPyのndarrayに変換し、機械学習の演算や高度なアルゴリズムによる処理を行う、というのがよくある方法だと思います。
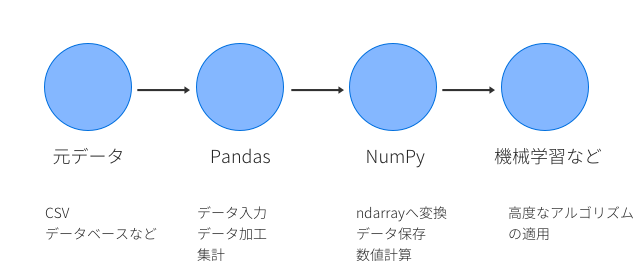
機械学習や画像処理を含む高度なアルゴリズムはDataFrameではなく、ndarrayを引数にとることが多いです。NumPyに落とし込むのは最後の最後の段階で、NumPyが処理するのが得意な形に持っていくようPandasで色々前処理をする役割になることが多いです。
データ分析では作業時間の5割以上は前処理に割くといっても過言ではありません。そう考えると、Pandasを使った処理を覚えておくと役立つ場面が多いでしょう。
データの可視化の比較
Pandasの特徴としてはデータの可視化が非常に容易なことが挙げられます。先ほど言及したようにPandasの持つ豊富なIndex機能によってグループ分けも容易であり、クロス集計なども簡単にできてしまいます。
いわゆる統計的な処理を行うことができ、matplotlibを使ったグラフ描画も、描くだけならDataFrameオブジェクトに.plot()をつけるだけで表示することが可能です。
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: import matplotlib.pyplot as plt
In [5]: df = pd.DataFrame(np.random.randn(10,10)*np.arange(10).reshape(-1,10))
In [6]: df.plot()
Out[6]: <matplotlib.axes._subplots.AxesSubplot at 0x11019ed68>
In [7]: plt.show()
グラフを表示するにはmatplotlibが必要ではありますが、これだけで一応グラフが描けてしまうというのはとても便利です。散布図も描くことが可能です。
matplotlibについては以下の記事を参考にしてください。
Pythonのmatplotlibを使ってデータを可視化する方法 /features/numpy-matplotlib.html
NumPyも比較的簡単に描くことは可能です。
In [31]: a = np.random.randn(10,10)*np.arange(10).reshape(-1,10)
In [35]: plt.plot(a)
Out[35]:
[<matplotlib.lines.Line2D at 0x1131242e8>,
<matplotlib.lines.Line2D at 0x113124438>,
<matplotlib.lines.Line2D at 0x113124588>,
<matplotlib.lines.Line2D at 0x1131246d8>,
<matplotlib.lines.Line2D at 0x113124828>,
<matplotlib.lines.Line2D at 0x113124978>,
<matplotlib.lines.Line2D at 0x113124ac8>,
<matplotlib.lines.Line2D at 0x113124c18>,
<matplotlib.lines.Line2D at 0x113124d68>,
<matplotlib.lines.Line2D at 0x113124eb8>]
In [36]: plt.show()
しかし、ラベルがついていないため凡例などがデフォルトで表示されません。
計算速度の比較
計算速度を比較してみましょう。
In [8]: a = np.random.randn(100000)
In [9]: b = pd.DataFrame(a)
In [10]: %timeit a.mean()
62.4 µs ± 2.11 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [11]: %timeit b.mean()
738 µs ± 39.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
上述したとおり、Pandasの方が遅く、平均を求めてみると10倍もの差がついています。計算スピードを重視される場合には、素のNumPyを使用した方がいい場合もあるでしょう。
ここで使っているNumPyのmean関数についての解説記事はこちら。
配列の要素の平均を求めるNumPyのaverage関数とmean関数の使い方 /features/numpy-average.html
違いのまとめ
以下に、PandasとNumPyの特徴を表にしてまとめました。
| Pandas | NumPy | |
|---|---|---|
| 扱うデータの種類 | ほぼ何でも | 主に数値データ |
| 演算の速度 | NumPyに比べると遅め | 速い |
| 得意な処理 | 欠損値処理 データ整形 他のデータベースとのアクセス 時系列データの扱い |
数値演算 特に行列演算 |
| 特徴 | SQLライクな操作性 |
ブロードキャスト機能 |
PandasとNumPyの互換性
PandasのベースはNumPyということもあって、互換性は非常に高いです。
NumPy→Pandas
PandasのDataFrameやSeriesはNumPyのndarrayから簡単に作ることができます。
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: array = np.arange(10)
In [4]: series_sample = pd.Series(array)
In [5]: array_2 = np.arange(20).reshape(4,5)
In [6]: df_sample = pd.DataFrame(array_2)
In [7]: series_sample
Out[7]:
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
In [8]: df_sample
Out[8]:
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
Indexの指定もNumPyのndarrayを使うことが可能です。
In [10]: df_sample_2 = pd.DataFrame(array_2, index=np.linspace(0,10,4))
In [11]: df_sample_2
Out[11]:
0 1 2 3 4
0.000000 0 1 2 3 4
3.333333 5 6 7 8 9
6.666667 10 11 12 13 14
10.000000 15 16 17 18 19
NumPyのlinspace関数の使い方はこちらの記事で解説しています。
線形に等間隔な数列を生成するnumpy.linspace関数の使い方 /features/numpy-linspace.html
Pandas→NumPy
では逆にPandasからNumPyのndarrayを作ってみましょう。
pd.Series.valuesまたはpd.DataFrame.values属性もしくはas_matrix関数をつかうケースがあります。
as_matrix関数はいずれなくなる関数のようです。values属性を使う方式に統一します。
データの中身をそのまま出力することは可能で、その場合はobject型としてNumPyのndarrayが作成されますが、NumPy自身はこのデータに何らかの処理を施すことはほとんどできないのであまり意味のある変換ではないです。
基本的には、全てのデータが同じ型に揃えるようデータ整形したのちにndarrayに渡すのがよいでしょう。
もしくは一部の要素だけ抜き出してNumPyの演算を行うなどしたほうがよいでしょう。
In [12]: a = {"class": ["a","b","c","b","a","c","a"],"grade": [0, 1, 3, 2, 1, 4, 5]}
In [13]: df = pd.DataFrame(a)
In [14]: df
Out[14]:
class grade
0 a 0
1 b 1
2 c 3
3 b 2
4 a 1
5 c 4
6 a 5
In [15]: array_1 = df.values
In [16]: array_1
Out[16]:
array([['a', 0],
['b', 1],
['c', 3],
['b', 2],
['a', 1],
['c', 4],
['a', 5]], dtype=object)
In [18]: array_1.mean() # 計算ができない
---------------------------------------------------------------------------
(エラーメッセージが表示される)
TypeError: Can't convert 'int' object to str implicitly
In [19]: array_2 = df["grade"].values # 一部だけ抜き出して平均を計算する
In [20]: array_2
Out[20]: array([0, 1, 3, 2, 1, 4, 5])
In [21]: array_2.mean()
Out[21]: 2.2857142857142856
大量のデータを扱うときは、このように一度NumPyに処理を任せるというのも1つの手になります。ではclassも数値として扱いやすくするためにはどうすればよいでしょうか。
このような場合はget_dummies関数がよく使われます。
In [25]: dummies = pd.get_dummies(df)
In [26]: dummies
Out[26]:
grade class_a class_b class_c
0 0 1 0 0
1 1 0 1 0
2 3 0 0 1
3 2 0 1 0
4 1 1 0 0
5 4 0 0 1
6 5 1 0 0
このようなあるクラスに該当するかどうかを0または1で表示することをone-hotエンコーディングと呼びます。
こうすればNumPyでも処理ができますし、機械学習のモデルでも扱いやすくなります。
In [28]: dummy_array = dummies.values
In [30]: dummy_array
Out[30]:
array([[0, 1, 0, 0],
[1, 0, 1, 0],
[3, 0, 0, 1],
[2, 0, 1, 0],
[1, 1, 0, 0],
[4, 0, 0, 1],
[5, 1, 0, 0]])
まとめ
簡単ではありますが、NumPyとPandasとの違いについてまとめてみました。
PandasやNumPyとは何なのか、よくわかってない方にざっくりとした違いとイメージを持ってもらえれば幸いです。
ここで扱った関数は他の記事で詳しく解説していきますので是非そちらも参照してください。