ビームサーチ(Beam Search)は、探索アルゴリズムの一種でメモリをそれほど必要としない最良優先探索です。
機械学習の分野でも、翻訳やチャットボットの返答などに応用されています。本記事では、ビームサーチのアルゴリズムを理解してどのように応用されているのかを解説します。
機械学習を活用したシステムを構築する際にも、探索空間が広い場合などには応用可能なので、使いこなせるようにしておくと役に立ちます。
深さ優先探索と幅優先探索
いきなりビームサーチの解説に入る前に、理解しやすいようにグラフ探索アルゴリズムを紹介します。
深さ優先探索
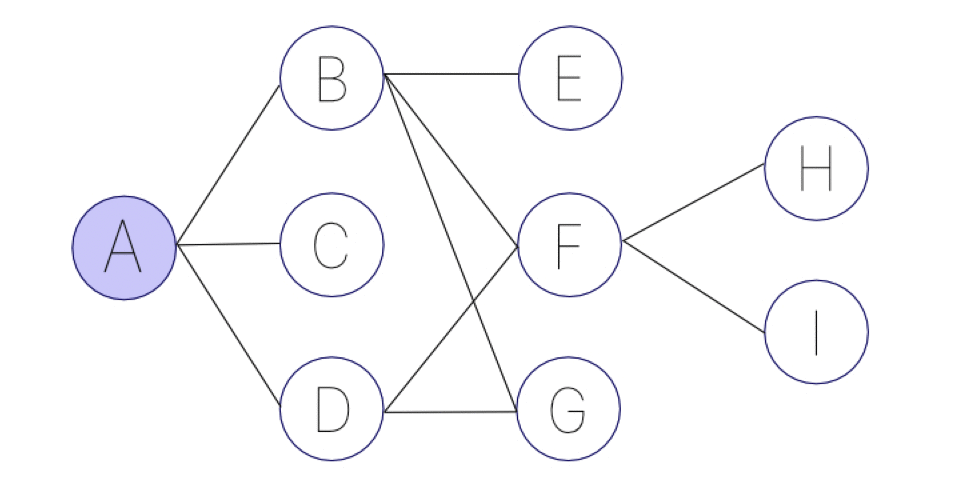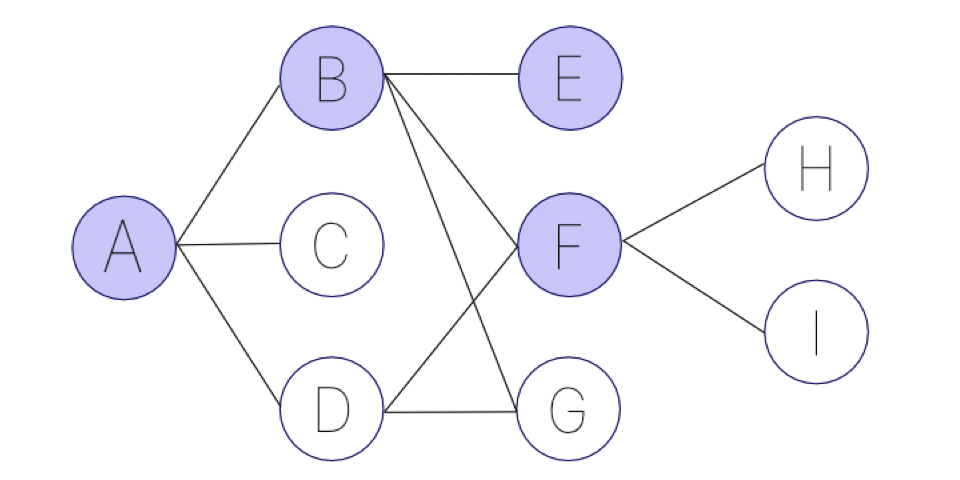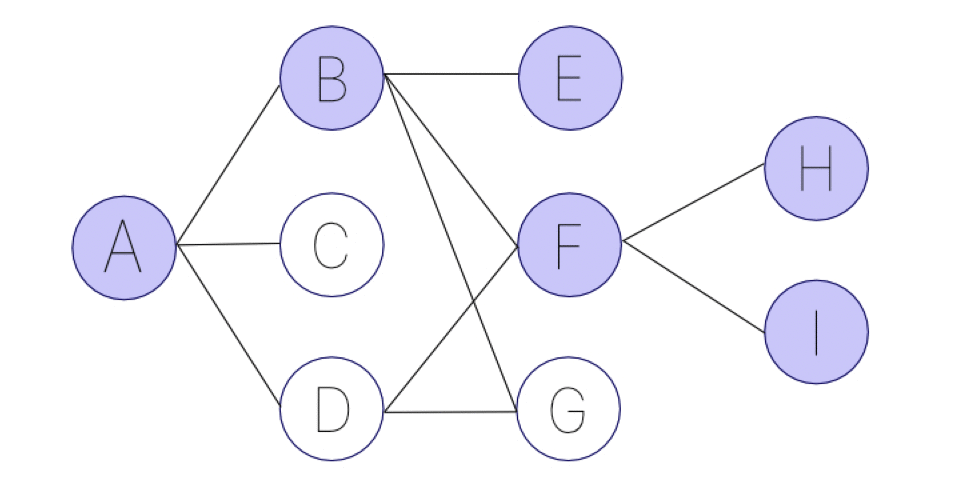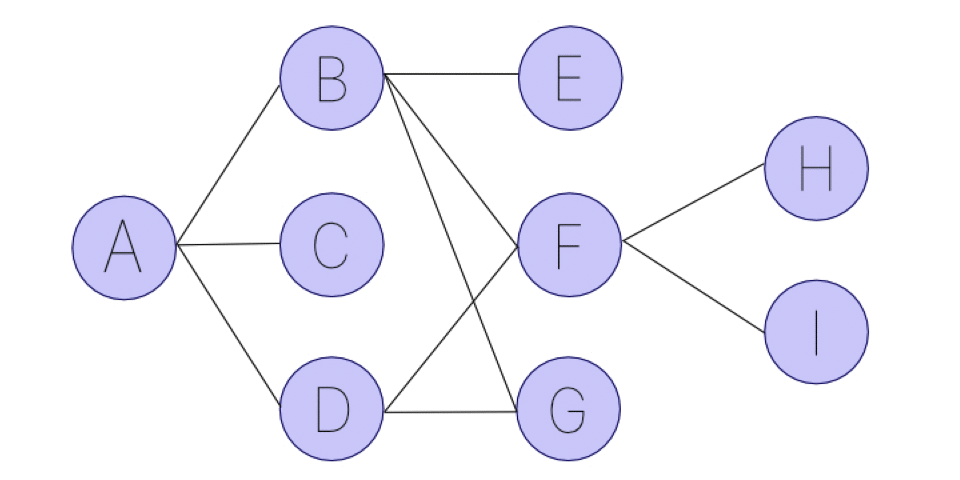
深さ優先探索は、その名の通り可能な限り突き進んで、行けなくなったら戻って再度深く探索していくアルゴリズムです。以下の図を見てください。
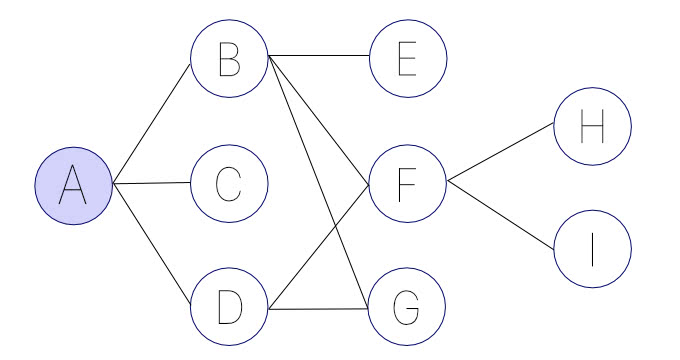
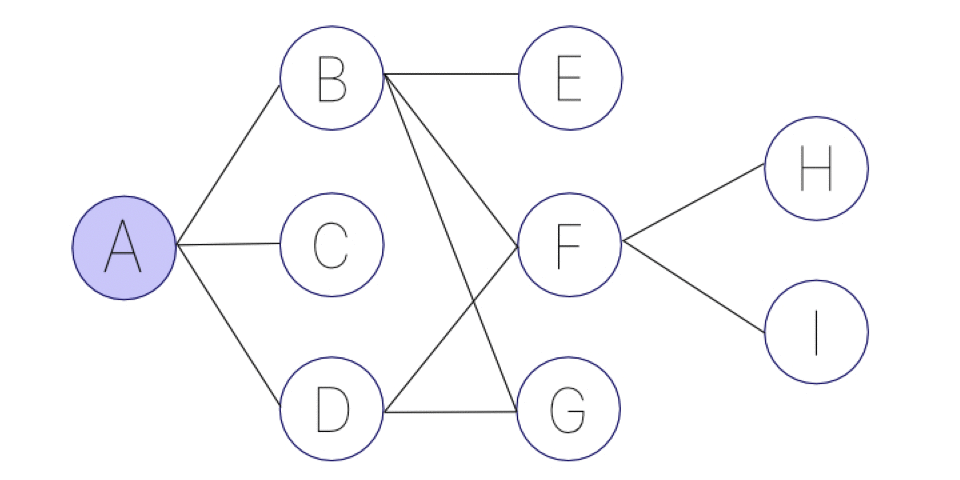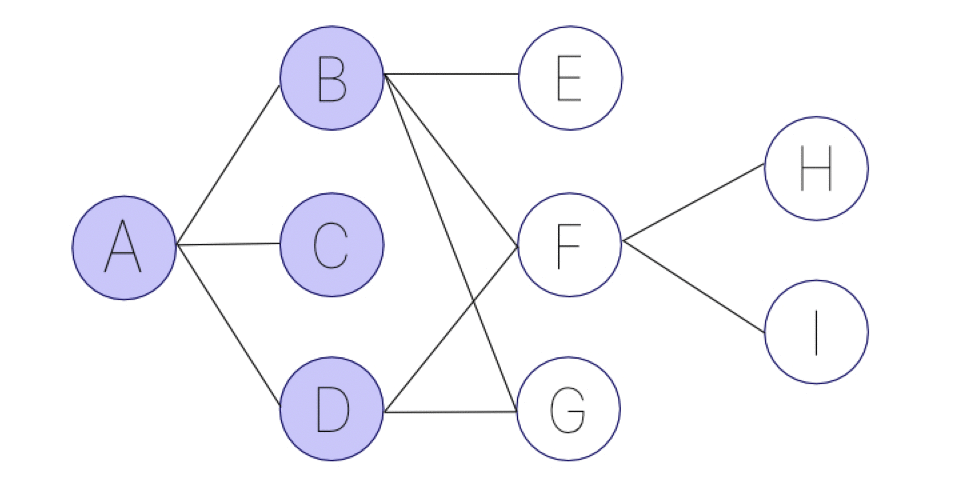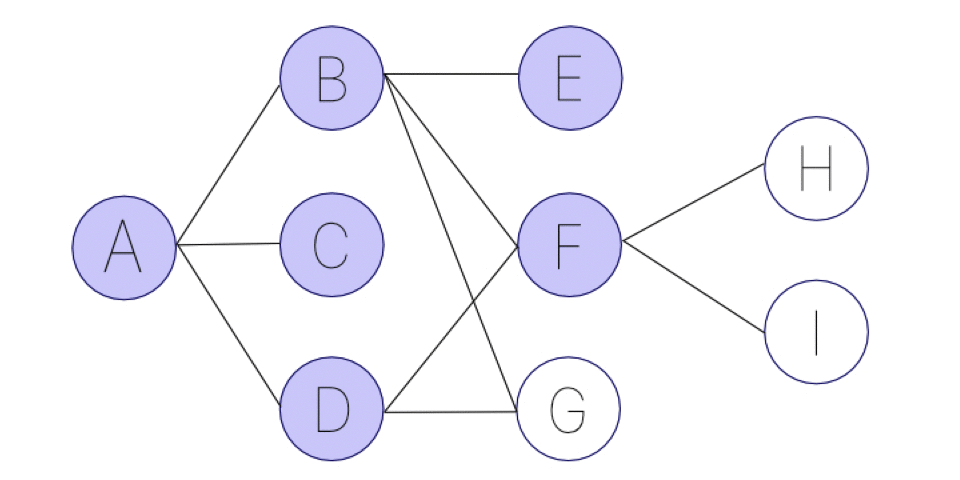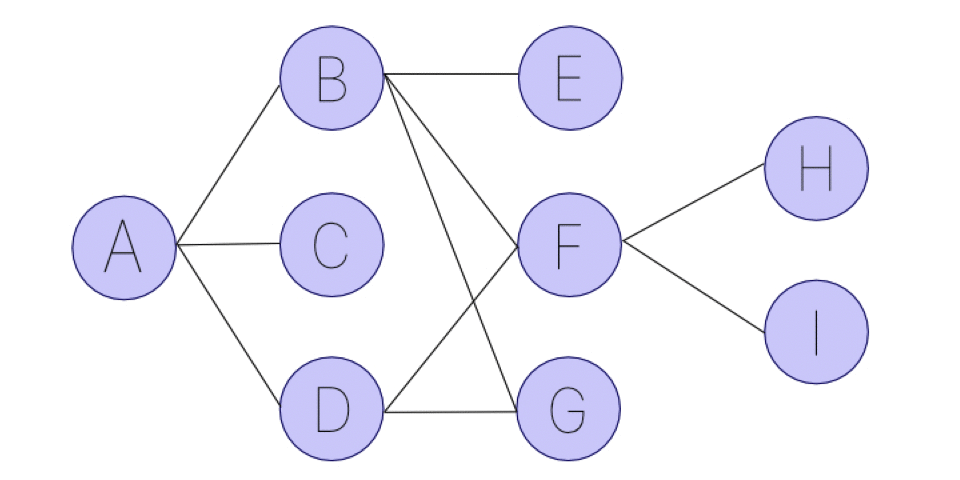
Aを出発地点のノードとして、全てのノードを探索する例を考えてみましょう。深さ優先探索の場合は以下のようなステップを踏みます。
(1) まずは適当にAからBに進む。
(2) Bからさらに突き進むことができるので、適当にEに進む。
(3) Eに行ったら進むことができなくなったので、Bに戻る。
(4) まだ行ったことのない進める場所があるので、Fに進む。
(5) さらに進めるので、適当にHに進む。
(6) 行ける場所がなくなったので、Fに戻る。
(7) (可能な限り続く)
アニメーションにすると、次の画像のようになります。可能な限り、深く突き進むことを優先します。
幅優先探索
幅優先探索は、取りうる選択肢の経路を平等に順番に攻めていくアルゴリズムです。こちらも、先程の下図の例を考えてみましょう。
同様にAを出発点とした場合、幅優先探索は以下の手順を踏みます。
(1) Aからの選択肢はB,C,Dの3つ。まずは適当にBに進む。
(2) その後、(1)の選択肢のCに進んでいないので、Aに戻ってCに進む。
(3) その後、(1)の選択肢のDに進んでいないので、Aに戻ってDに進む。
(4) ここで、(1)の選択肢をすべて通ったので、Bからの選択肢E,F,Gのうち、Eに進む。
(5) その後、(4)の選択肢のFに進んでいないので、Fに進む。
(6) その後、(4)の選択肢のGに進んでいないので、Gに進む。
(7) ここで、(4)の選択肢全て進んだので、Cは選択肢がない。また、Dからの選択肢も既に通っているので、Fからの選択肢H,IのうちHに進む。
(8) (可能な限り続く)
こちらもアニメーションにすると、以下のような画像になります。名前の通り、幅優先になっています。
深さ優先探索では、解が深いところにある場合には進む方向の選択次第では少ないステップで答えが求まります。深さ優先探索では、平等に選択していくために、深い部分に解がある場合は時間がかかります。
ビームサーチ
問題によっては、もっと少ないステップで解が求められる場合があります。上述の深さ優先探索や幅優先探索では、ノード数と辺の数の合計に比例する時間がかかります。ノードの数が爆発的に増大すると、全てを計算することは現実的ではありません。
ビームサーチは、幅優先探索をする際にすべてを考慮すると計算が終わらないので、その場の深さで評価値が良い方から順に上位数個の選択肢のみを考慮するアルゴリズムです。
以下の動画の例が分かりやすいです。文字列シーケンスをRNNで生成することに関する解説です。THE QUICK BR…まで予測したときの、次に続く文字列を決定する際にビームサーチを使用します。
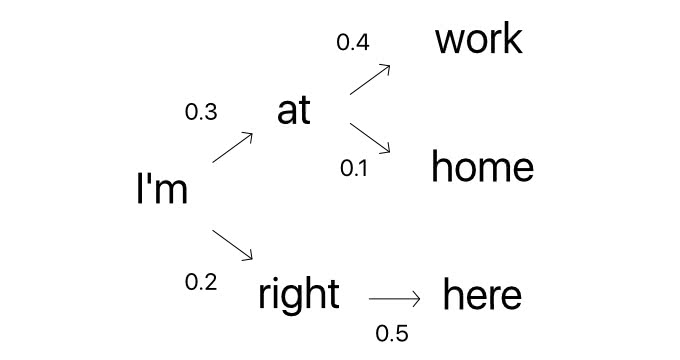
Rの次の時刻 の時点で、AとOが0.3と0.4で確率が高いので解とする可能性を2つだけ保持しておきます。その後の候補として、OAとOWの同時確率が高いので、この2つの解を保持するという戦略で生成する解を決定します。ビームサーチを使用することで、比較的メモリと計算量を抑えながら、そこそこ良い組み合わせの文字列を出力することができます。
RNNについて詳しくは次の記事を参考にしてください。
RNN:時系列データを扱うRecurrent Neural Networksとは /deep_learning/2017/05/23/recurrent-neural-networks.html
機械学習への応用
ビームサーチを機械学習に適用した例を紹介します。大量の選択肢の中から、適切な組み合わせを選択するために使用されます。
Google Alloの返答
Google Alloは、Googleのメッセージングアプリでチャットボットが返答してくれます。Alloは、ユーザーのことを考慮しながら適切な返答をするためにビームサーチを応用しています。 [1]
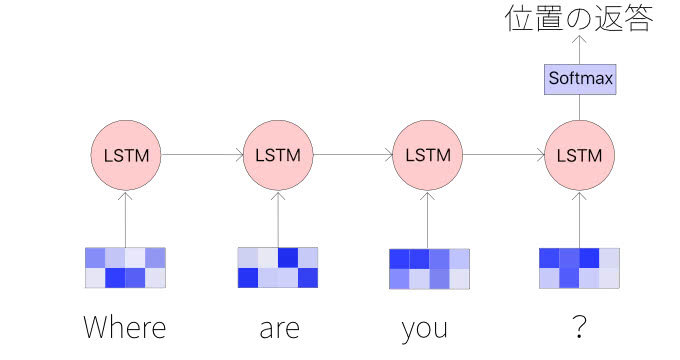
まず、Alloはユーザーからの質問を受け取ると、返答グループを予測します。以下の図の場合、「どこにいる?」と聞かれると場所を答えるという大雑把なカテゴリに分類します。
次に、カテゴリ毎のRNNモデルで返答文を出力します。Alloの出力は、ユーザー毎に返答スタイルを変えているため、ユーザーの埋め込み表現も入力に含めています。
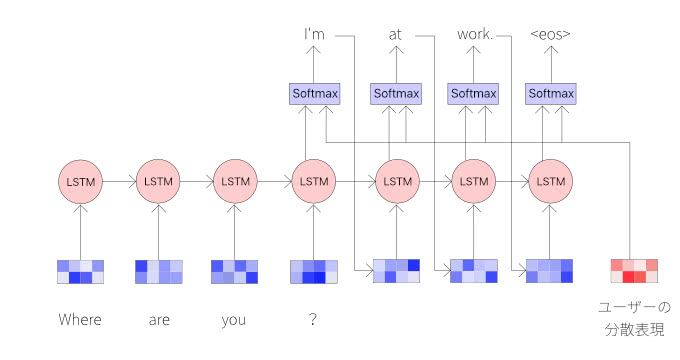
最終的な出力文の単語列は、RNNデコーダで各タイムステップ毎に1つずつ生成されます。各タイムステップでは、RNNデコーダではSoftmax層を介した単語候補の確率分布となっています。予測時の各タイムステップでの出力は、局所的に確からしい単語を選択しているので全体の出力文の単語列の確率分布を最大化していません。
上述のRNNと同じ仕組みですが、ビームサーチを使用することで出力返答文のクオリティを高めつつ、効率的に大量の返答候補から返答文を生成することができます。下図のように、幅優先探索で単語毎に生成確率が上位の単語列のみを検討候補にしながら最終文を決定します。
学習時にビームサーチの幅を持たせて学習
上述のRNNの結果を、予測時にビームサーチを使用して確からしい単語列を生成するアプローチでは、学習時にビームサーチされることを考慮していません。予測時には正しくない単語列を出力してしまう可能性があるのにも関わらず、正しい単語列のみを訓練してしまいます。
そこで、下図のように訓練時に単語列として一番確率の高い黄色の単語列とは別に”ビーム幅”をもたせて学習するBeam Search Optimizationというアプローチが提唱されています。
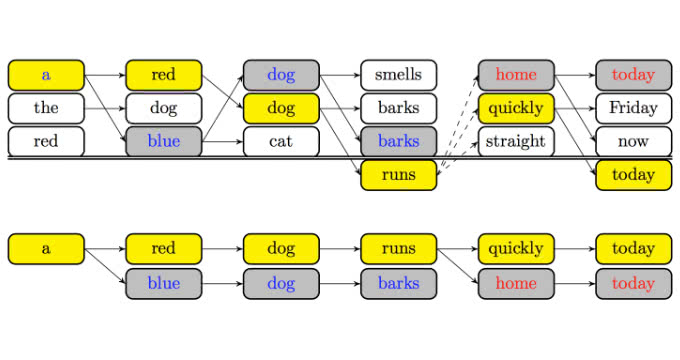
[2] Sequence-to-Sequence Learning as Beam-Search Optimization
こうすることで、ドイツ語と英語間の翻訳タスクでSeq2Seqモデルより良い性能を出しており、単語の並べ替え・依存構造解析でもSeq2Seqモデルよりも良い性能になります。
3D形状の学習への応用
3Dボクセルの形状を分類するために、Beam Search for Learning a Deep Convolutional Neural Network of 3D Shapesという論文では、ビームサーチでCNNのアーキテクチャを探索するために応用しています。
CNNについて詳しくは以下の記事を参考にしてください。
定番のConvolutional Neural Networkをゼロから理解する /deep_learning/2016/11/07/convolutional_neural_network.html
従来のShapeNetという3Dオブジェクトを認識するためのアーキテクチャは、AlexNetというCNNのアーキテクチャを拡張して3D対応したものです。ImageNetなどの分類タスクでは、大量の学習データがあるのに対して、3Dオブジェクトの形状分類はそれほど公開されている学習データがありません。結果として、あまりにパラメータが多くなってしまうと、少ない学習データでモデルが良好に学習されるかどうかは、手作業のチューニングに依存してしまいます。
まずは次のような、小さなCNNをアーキテクチャの初期値として使います。
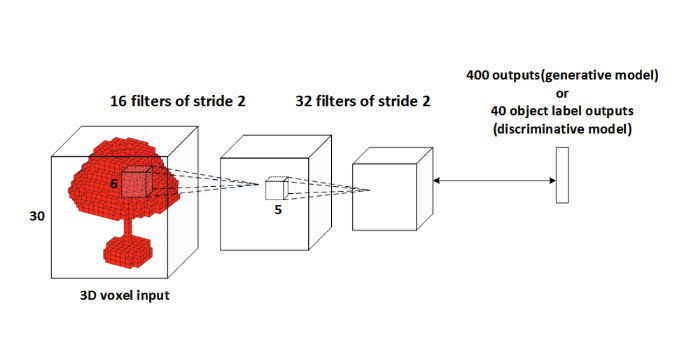
その後、以下の2つの種類の変更を加えて、正答率を基準にビームサーチしていきます。
(1) 新しくConvolution層を追加する
(2) 最上位のConvolution層のフィルタサイズを2倍にする
これによって、従来アーキテクチャのパラメータ数を99.4%減らしながら、3%の正答率の向上に成功しています。
まとめ
ビームサーチを使用することで、機械学習システムの性能を高めることができる例を紹介しました。
Seq2Seqのデコーダのように、順序列がある場合や、アーキテクチャの選択などへの使用例を頭の中に入れておくだけでも今後の開発や研究に活かすことができると思います。