TensorFlow Foldは、TensorFlowに動的な計算グラフを構築する機能を追加するフレームワークです。
この記事では、TensorFlow Foldの紹介をしながら
- 動的な計算グラフのメリット・デメリット
- Dynamic Batching
- TensorFlow Foldの設計
- TensorFlow Foldの使い所
について焦点を当てて解説します。この記事を読めば、柔軟なフレームワークを使うことのメリットや、より複雑なニューラルネットワークを組む際の参考になるはずです。
動的な計算グラフと静的な計算グラフ
ディープラーニングフレームワークの大きな違いとして、言語と計算グラフの構築方法があります。 言語は、C++やPythonが主流になっています。LuaをベースとしていたTorchもPythonで記述できるPyTorchをリリースしました。
もう一つが、ニューラルネットワークの計算に必要な計算グラフの構築を動的にやるか静的にやるかという違いです。
例えばTheanoやCNTK、TensorFlowはすべての計算グラフを事前に構築してから実行する「静的に」計算グラフを構築するアプローチをとっていました。一方でChainerやDyNetはその都度必要な計算グラフを構築して実行する「動的に」計算グラフを構築するアプローチをとっています。
この違いを、静的なアプローチを最初に全て構築してから実行するので「Define and Run」、動的なアプローチを必要な計算グラフを構築して即座に実行することから「Define by Run」と表現することもあります。
では、どちらが優れたアプローチでしょうか?
動的な計算グラフを構築するアプローチのメリットは、柔軟にネットワークを構築できるため、複雑なモデルを定義して実装しやすい点があります。以下の画像は、標準的なRNNのネットワーク構造です。RNNは、データの順序を考慮することができるネットワーク構造で、動画などの時系列データや自然言語処理に利用されています。
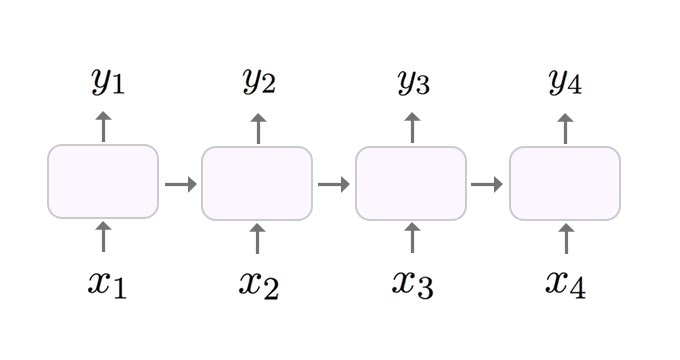
順序がありますが、この構造であればそれほど複雑ではないですね。
コンピュータサイエンスでは、自然言語から構文解析木を構築することがあります。プログラミング言語では、文字列を解析して抽象構文木を構築することがあります。ニューラルネットワークでも、以下の画像のようなネットワーク構造をしたTree-LSTM [2] という木構造での学習が提案されています。
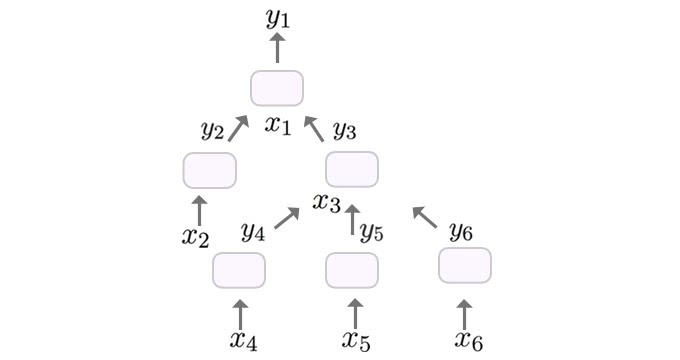
こうすることで、自然言語の感情分類や文の関連度予測のタスクで標準的なLSTMよりも高い精度を実現することができます。問題点は、静的な計算グラフでは、サンプル毎に構造が変化するような複雑なネットワーク構造の実装が難しいことです。実際、Stanford大学のBowman教授は、論文中で「TreeRNNsは各文において、様々なモデルを使わなければならないので、標準的な実装で効率的なバッチングは不可能である。[3]」と述べています。
こうしたネットワーク構造では、動的に計算グラフを構築する手法では柔軟にモデルを都度構築することができるため、比較的容易に実装することができます。
動的な計算グラフにもデメリットがあります。サンプル毎に毎回計算グラフを構築するため、構築のオーバーヘッドによる学習速度が犠牲になります。静的な計算グラフの構築であれば、計算を実行する前に、並列処理を含めて省メモリで計算コストが小さくなるように事前に計算を最適化することが出来ます。
Dynamic Batching
TensorFlow Foldに導入された機能はDynamic Batchingと呼ばれるものです。動的な計算グラフを使いながら、訓練時と推論時に効率的なバッチ処理を実現しています。Dynamic Batchingを導入することで、静的な計算グラフしかサポートしていないライブラリでも、動的な計算グラフ構築機能を追加することができます。
なぜ動的な計算グラフを静的な計算グラフ上で実行することができるのでしょうか?
計算グラフの処理単位は、テンソルと演算の2つに分けることができます。テンソルがデータで、演算がデータの操作に対応します。Dynamic Batchingは足し算や引き算といった演算の処理単位をまとめたサブグラフ(オペレーション)を基本的な処理単位として考えます。このオペレーションは、RNNCellのようなテンソルを入力として、テンソルを出力するものになります。
Dynamic Batchingは、静的な計算グラフの中に各オペレーションはたった1つのインスタンスしか保持しません。
適用するオペレーションをスケジューリングして、concatとgatherでwhile_loopで評価するオペレーションを組み替えることで実現しています。
入力の前に、gatherでテンソルを読み込んで、出力のテンソルはconcatで処理されます。オペレーションの評価はwhile_loopの中でされます。
このような設計にすることで、各オペレーションは非循環の有向グラフであれば、任意のサイズでどんな構造でも入力にすることができます。動的な結合と評価を、concatとgather、while_loopの3つの演算が対応します。この演算はすべて微分可能なので、追加のコードは不要で勾配の計算をすることができます。計算グラフの構築回数も減らすことができるので、効率的に計算することができるのです。
以下の画像は、Googleの公式アナウンス[1]中でのTensorFlow Foldを紹介するために使われたアニメーションGIFです。
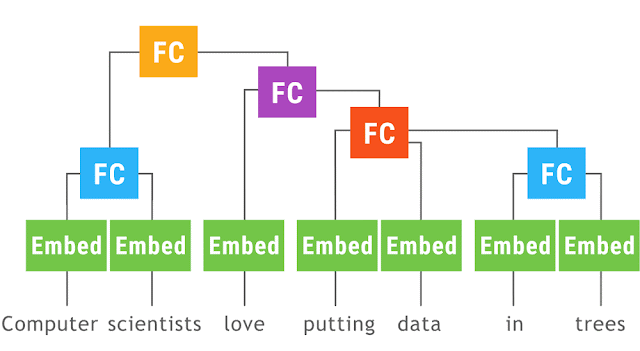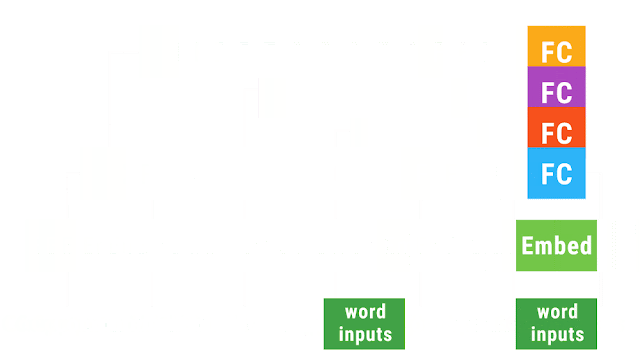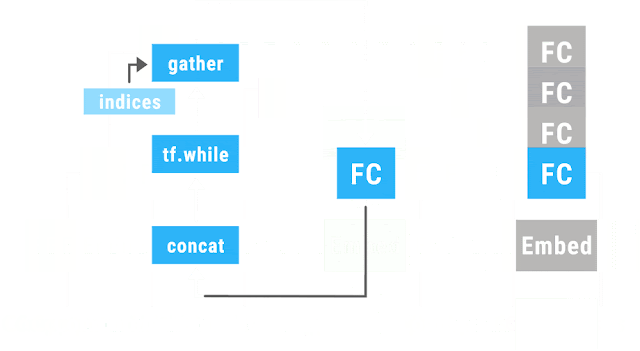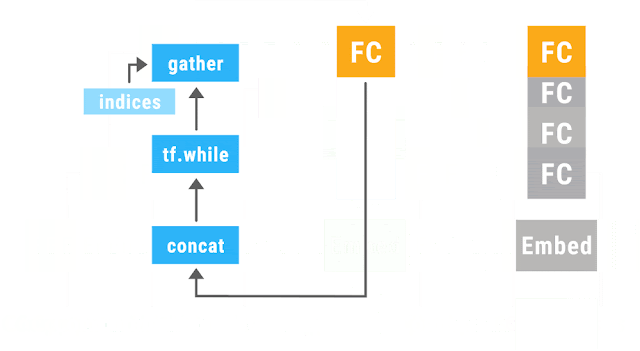
Announcing TensorFlow Fold: Deep Learning With Dynamic Computation Graphs
「Computer scientists love putting data in trees.」という文から文法に沿って木構造の計算グラフを構築するものです。各オペレーションと結合部分の演算は、たった1つのサブグラフしか構築していません。
論文中では、十分に大きなバッチサイズで実験したところ、Tree-LSTMの実装では、GPUでは100倍以上高速になり、CPUでも10倍以上高速になると報告されています。
関数型からインスパイアされた設計
このフレームワークは、関数型プログラミングを参考にデザインされています。関数型のスタイルをとることで、より高レベルなAPIを通して素早い開発と検証のフィードバックサイクルを実現することが目的です。
関数合成
TensorFlow Foldでは、関数合成のようにオペレーションのブロックを合成していきます。
以下のコードは、単語の分散表現を獲得するための、Word2Vecの処理ブロックを構築する例です。
word2vec = (InputTransform(word_idx.get) >>
Optional(Scalar('int32')) >>
Function(Embedding(initializer=word_matrix)))このコードは3つのオペレーションを合成しています。
- 単語から単語IDへと変換するオペレーション
- インデックスをスカラ値のテンソルに変換するオペレーション
- テンソルを埋め込み表現に変換するオペレーション
この3つのブロックが定義されていれば、>>演算子だけで合成して、新しいブロックを定義することができます。
Word2Vecについては以下の記事を参考にしてください。
この新しいWord2Vecのブロックを定義することができれば、もう少し複雑なブロックも簡単に定義することができるようになります。以下のコードは、任意のテキストをベクトル化するブロックを定義する例です。
split = InputTransform(str.split)
rnn_cell = Concat() >> Function(FC(d, activation=tf.nn.relu))
text2vec = split >> Map(word2vec) >> Fold(rnn_cell, Zeros(d))このコードは、3つのブロックを合成しています。
- テキストを単語に分割するブロック
- Word2Vec
- 活性化関数にReLUを使ったRNNセルのブロック
ここで、Mapはスカラではなく、ベクトルを操作するために使います。それぞれの要素にword2vecのブロックを適用します。Pythonプログラマにとっては、リスト内包で [f(x) for x in xs]のような操作だと考えたほうが分かりやすいでしょう。最後に、出力はベクトルのベクトルになるので、FoldでRNNのセルブロックを適用しながら1つのベクトルにします。
TensorFlow Foldのインストール
TensorFlow Foldのインストール方法は、pipを使ってインストールします。現状Linuxでしか動作しないので注意してください。
まずはTensorFlowが必要になります。TensorFlowのインストールは以下の記事を参考にしてください。
機械学習初心者でもすぐに出来るTensorFlowのインストール方法 /tensorflow/2017/01/17/how-to-install-tensorflow.html
注意点として、現行では、TensorFlowのバージョン1.0.1では不具合が発生するバグが報告されているので、1.0.0を使いましょう。pipでバージョンを指定しながらインストールする方法は以下のようにしてバージョンを指定します。
$ pip install tensorflow==1.0.0TensorFlow FoldはURLから直接インストールします。Python2系をお使いの方は、こちらのコマンドでインストールしてください。
$ pip install https://storage.googleapis.com/tensorflow_fold/tensorflow_fold-0.0.1-cp27-none-linux_x86_64.whlPython3系はこちらでインストールします。Python3.3以上であれば動作します。
$ pip install https://storage.googleapis.com/tensorflow_fold/tensorflow_fold-0.0.1-py3-none-linux_x86_64.whl動かしてみる
それでは、TensorFlow Foldを動かしてみます。必要なライブラリをimportします。
>> import tensorflow as tf
>> import tensorflow_fold as tdtensorflow_foldは省略するとtfですが、TensorFlowのtfと被るのでtdが公式では省略として使われています。
次に、1~10までを足し合わせるコードを書いてみます。以下のコードで、1~10の配列をテンソルに変換して足し合わせるブロックを構築して実行することができます。
>> sess = tf.InteractiveSession()
>> (td.Map(td.Scalar()) >> td.Sum()).eval(range(1, 11))
array(55.0, dtype=float32)合計値が評価され、55だけが入った配列が返ってきました。TensorFlow Foldでは、スカラ値は1つの要素を持つ配列として扱われるようです。
まとめ
TensorFlow Foldを使うことで、簡単にTensorFlowに動的な計算グラフの機能を追加することができます。
バッチ毎にネットワーク構成が変わるような複雑なネットワーク構成を組みたいときには、実装が楽になるだけでなく、高速化も期待できます。
まだTensorFlow Foldはリリースされたばかりなので、これからフィードバックを受けてさらに使いやすくなると嬉しいですね。
参考
[1] Announcing TensorFlow Fold: Deep Learning With Dynamic Computation Graphs
[2] Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks
[3] A Fast Unified Model for Parsing and Sentence Understanding
[4] Deep Learning with Dynamic Computation Graphs
[5] DyNet: The Dynamic Neural Network Toolkit