Hinton先生がDeep Learningの研究成果を上げてから、Microsoftでもディープラーニングに関する様々な取り組みをしてきたそうだ。
Skype翻訳ではビデオ会議中のリアルタイム自動翻訳に活用され、Microsoft Researchにおいても様々な研究がなされてきた。
そんなMicrosoftも、2016年1月にはCNTKという機械学習フレームワークにMITライセンスを適用させてGitHub上に公開している。
本記事では、
- Microsoftが公開したCNTKとは何か
- CNTKの特徴
- CNTKのメリット
を紹介する。
CNTKとは
CNTKは、Microsoft Cognitive Toolkitの略でDeep Neural Networksにおける学習と評価をするために開発されている機械学習ライブラリだ。
オープンソースでGitHub上に公開されており、MITライセンスなので誰でも無償で無制限に利用できる。
当然のように、CNNやRNN、LSTMといったモデルを構築することができるが、何より複数のマシンの複数のGPUを十分に利用可能なところが魅力だろう。
CNTKの公式サイトには、
- Speed & Scalability: 他のディープラーニング開発ツールよりも速く学習・実行できること
- Commercial-Grade Quality: 洗練されたアルゴリズムで構築され、巨大なデータセットでも信頼性のおける製品を構築できること
- Compatibility: 簡単に利用可能であり、自身でアルゴリズムをカスタマイズできること
という3つの方針を掲げているようだ。
シンプルな構成要素を組み合わせることで、どんなニューラルネットワークでも構築できるように設計されている。
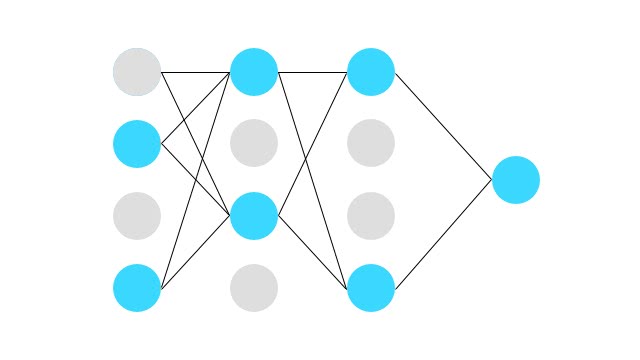
2つの隠れ層を持つ順伝播型ニューラルネットワークを数式で表現する。
CNTKでは数式と似たような形式で書いていくことができ、
h1 = Sigmoid(W1 * x + b1)
h2 = Sigmoid(W2 * h1 + b2)
P = Softmax(Wout * h2 + bout)
ce = CrossEntropy(y, P, tag='criterion')
このように書いていける。その後、CNTK内部ではComputation Graphと呼ばれる表現に変換される。
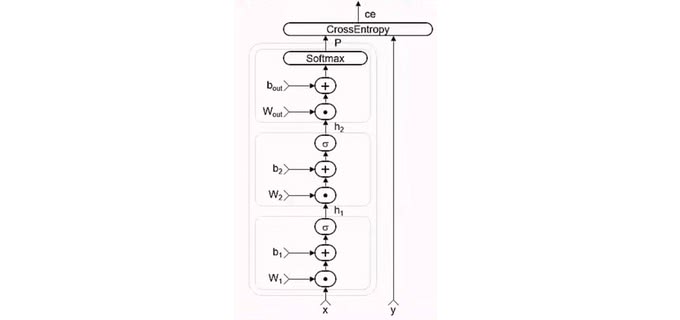
グラフ上のノードが関数となっており、エッジが値となる。先にグラフ表現に変換することで、
- 自動微分による学習
- 事前に最適化することで、実行時のメモリ・計算コストの削減
を実現できる。
CNTKの特徴
それでは、CNTKの特徴を見ていこう。
パフォーマンス
CNTKが他と最も違う点はパフォーマンスだろう。CNTKはサーバ・GPUのパラレル学習に最適化することを念頭に設計されている。CNTK1.0と比較するとほぼ2倍の高速化に成功したようだ。
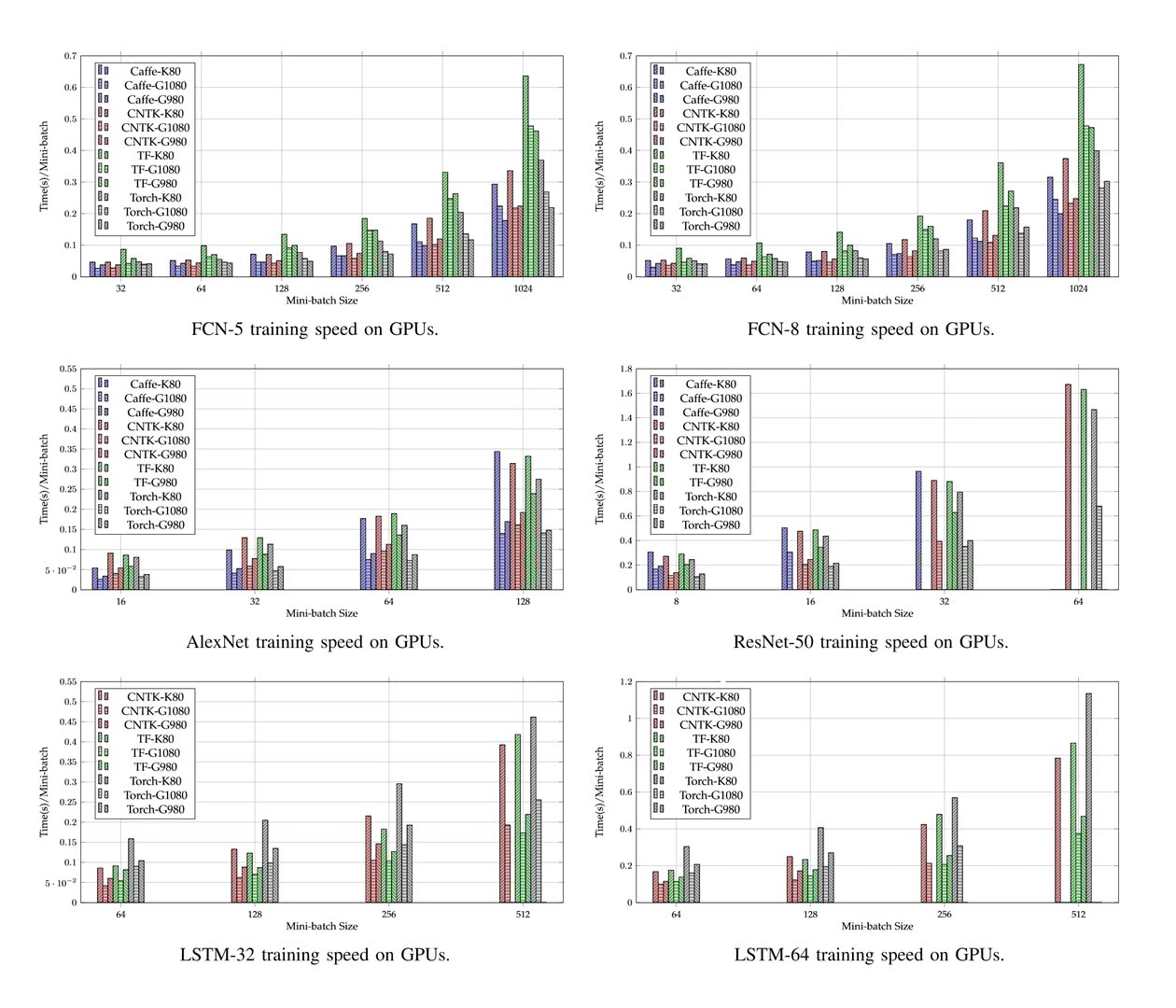
こちらが、全結合・AlexNet・ResNet・LSTMにおけるベンチマークとなっている。少し見にくいが、赤色がCNTKの結果だ。CNTKは全結合とLSTMにおいて最も高速なパフォーマンスを出している。AlexNetはCaffe、そしてResNetはTorchが最速となった。
スケーラビリティ
CNTKがリリースされた時、最も魅力的だったものがスケーラビリティだったのではないだろうか。開発者は単一マシンに搭載されたGPUの数に縛られることなくモデルを学習させることができる。たった一つのマザーボードには4つしかGPUを積むことができないのだ。
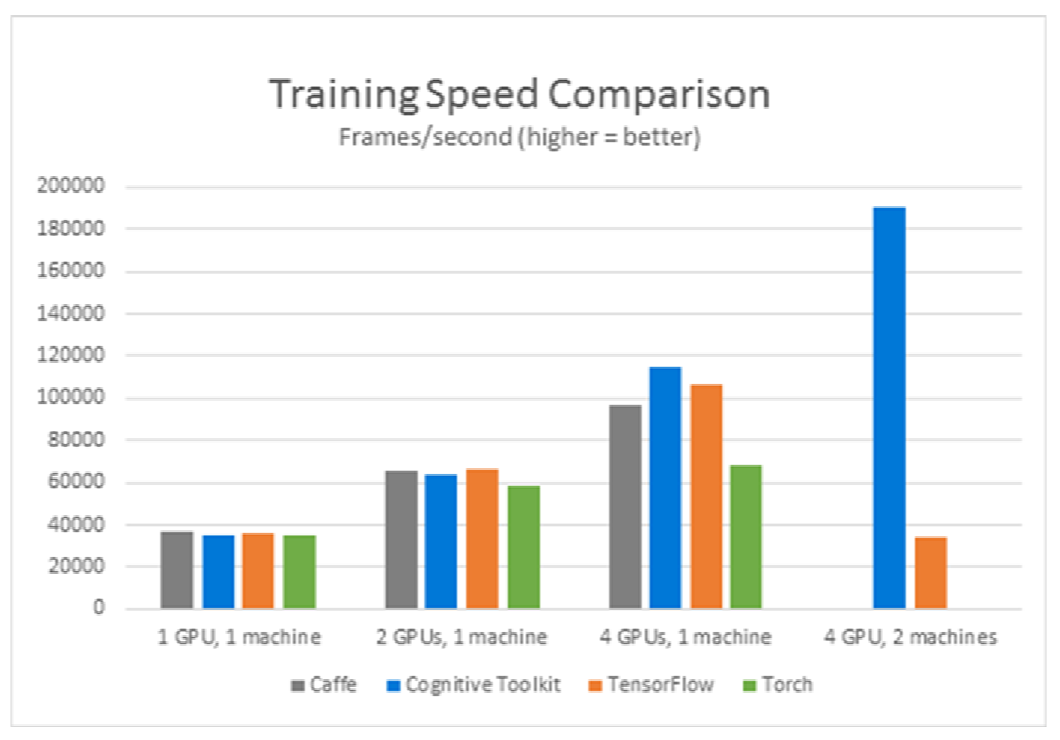
こちらが、Hong Kong Baptist Universityで実験されたベンチマークだ。単一のマシンにおける複数GPUのタスクにおいてはほとんど変わらない結果となった。複数台のマシンで実行できるものはTensorFlowとCNTKのみとなっているが、圧倒的にCNTKが高速だったようだ。
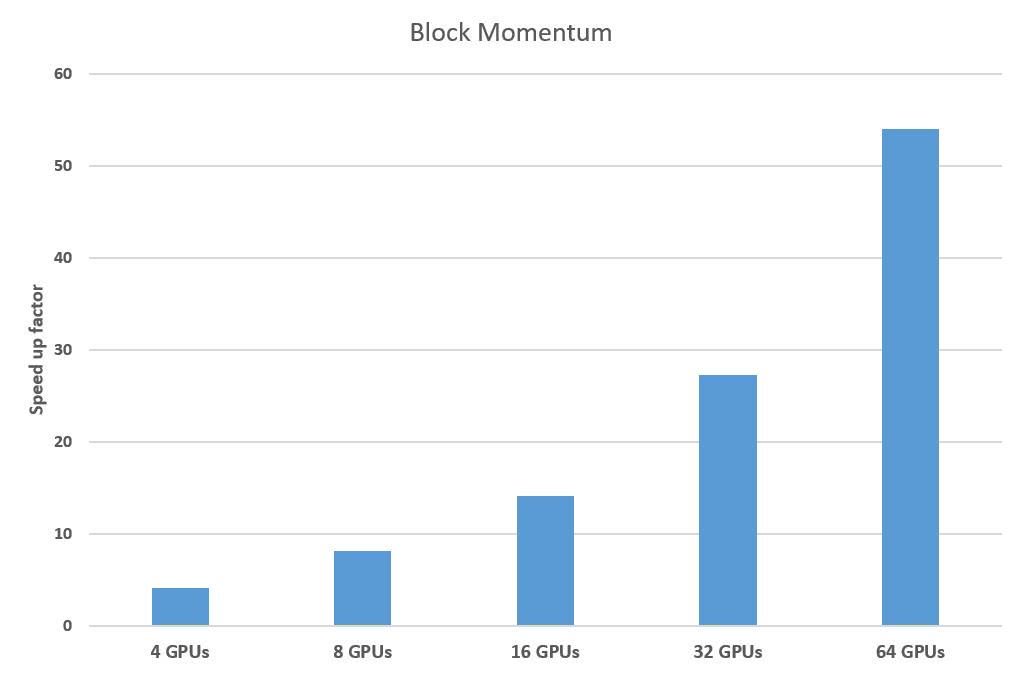
CNTK1.5ではBlock Momentumをサポートした。これにより、大幅にGPU間での通信コストを削減できる。精度を維持したまま、複数GPUで高速化するテクニックだ。
CNTKでは、マシンを超えてGPUの数を増やしていける。64個のGPUクラスタで実行したところ、上図のタスクにおいては1個の場合と比べてパフォーマンスは50倍以上になっている
1-bit SGD
CNTKには、1-bit SGDという、勾配を1bitにまで量子化することで通信コストを削減する機能が存在する。分散GPUでボトルネックとなるのは通信コストである。並列計算中の通信コストを大幅に削減することで、ニューラルネットワークの訓練時の学習速度を著しく向上させることができる。
この機能が利用できるCNTKは、少しライセンスが違うので商用利用する場合には以下のライセンスをよく読んでおいたほうがいい。
1-bit Stochastic Gradient Descent for the Computational Network Toolkit Custom License
世界最高水準のモデルが作成できること
これまでMicrosoft Researchにおいても、Deep Neural Networkの研究をしてきた。
2015年のImageNet Competitionという画像認識のタスクで認識精度を競うコンペで勝利したのはMicrosoft Researchが発表したResNetだった。

Microsoft ResearchでもCNTKを使ってこういった研究がされている。つまり、おもちゃレベルのフレームワークではなく研究レベルのものも開発できるようになっている。
モデルギャラリーには、ResNetだけでなくFast RNNやSequence to Sequence、音声認識用のモデルなど様々なモデルの実装例が公開されている。
多様なインターフェース
CNTK2のベータではパフォーマンスの向上の他に、Pythonサポートが大きいだろう。
Microsoftの音声認識の研究者であるXuedong Huang氏は、CNTK2.0のリリースを「民主化」と呼んでいる。これまで、C++とNDLという言語しかサポートしておらず、Microsoftの社内で利用する分には問題なかったが、オープンソースのコミュニティーはPythonで利用可能なことを求めていたのだ。
現在では、C++・Python・.NET・BrainScriptをサポートしている。
Python
機械学習エンジニアが主に使っているのはPythonだ。Jupyter notebook、オープンソースコミュニティ、Numpyなどエコシステムが整っている。
CNNやResNet、RNNなど一般的に利用されるコンポーネントは準備されている。CNNの例は理解しやすい。
with default_options(activation=relu):
conv_net = Sequential ([
# 3 layers of convolution and dimension reduction by pooling
Convolution((5,5), 32, pad=True), MaxPooling((3,3), strides=(2,2)),
Convolution((5,5), 32, pad=True), MaxPooling((3,3), strides=(2,2)),
Convolution((5,5), 64, pad=True), MaxPooling((3,3), strides=(2,2)),
# 2 dense layers for classification
Dense(64),
Dense(10, activation=None)
])LSTMのコードも簡単に理解できる。CNTKのPythonバージョンは可読性高く設計されている。
tagging_model = Sequential ([
Embedding(150), # embed into a 150-dimensional vector
Recurrence(LSTM(300)), # forward LSTM
Dense(labelDim) # word-wise classification
])BrainScript
CNTKの大きな特徴は、このBrain Scriptだろう。設定ファイルのように宣言的にネットワークの構成を書いていき、コマンドラインツールで訓練を実行する。素早くプロトタイプをつくって試したい場合や、ネットワークの構成をチューニングする場合には便利だ。
MNISTの文字認識をCNNで書く例:
command = trainNetwork:testNetwork
precision = "float"; traceLevel = 1 ; deviceId = "auto"
rootDir = "../../.." ; dataDir = "$rootDir$/DataSets/MNIST" ;
outputDir = "./Output" ;
modelPath = "$outputDir$/Models/ConvNet_MNIST"
#stderr = "$outputDir$/ConvNet_MNIST_bs_out"
# TRAINING CONFIG
trainNetwork = {
action = "train"
BrainScriptNetworkBuilder = {
imageShape = 28:28:1 # image dimensions, 1 channel only
labelDim = 10 # number of distinct labels
featScale = 1/256
Scale{f} = x => Constant(f) .* x
model = Sequential (
Scale {featScale} :
ConvolutionalLayer {32, (5:5), pad = true} : ReLU :
MaxPoolingLayer {(3:3), stride=(2:2)} :
ConvolutionalLayer {48, (3:3), pad = false} : ReLU :
MaxPoolingLayer {(3:3), stride=(2:2)} :
ConvolutionalLayer {64, (3:3), pad = false} : ReLU :
DenseLayer {96} : Dropout : ReLU :
LinearLayer {labelDim}
)
# inputs
features = Input {imageShape}
labels = Input {labelDim}
# apply model to features
ol = model (features)
# loss and error computation
ce = CrossEntropyWithSoftmax (labels, ol)
errs = ClassificationError (labels, ol)
# declare special nodes
featureNodes = (features)
labelNodes = (labels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (ol)
}
SGD = {
epochSize = 60000
minibatchSize = 64
maxEpochs = 40
learningRatesPerSample = 0.001*10:0.0005*10:0.0001
dropoutRate = 0.5
momentumAsTimeConstant = 0*5:1024
numMBsToShowResult = 500
}
reader = {
readerType = "CNTKTextFormatReader"
# See ../REAMDE.md for details on getting the data (Train-28x28_cntk_text.txt).
file = "$DataDir$/Train-28x28_cntk_text.txt"
randomize = true
keepDataInMemory = true
input = {
features = { dim = 784 ; format = "dense" }
labels = { dim = 10 ; format = "dense" }
}
}
}
# TEST CONFIG
testNetwork = {
action = test
minibatchSize = 1024 # reduce this if you run out of memory
reader = {
readerType = "CNTKTextFormatReader"
file = "$DataDir$/Test-28x28_cntk_text.txt"
input = {
features = { dim = 784 ; format = "dense" }
labels = { dim = 10 ; format = "dense" }
}
}
}
設定ファイルの記述のように、パラメータやネットワークの構成を書いていく。これでデータの読み込みやData Augmentationなど一通りのことができる。
Microsoftでの実績
Microsoftは実際にDeep Learningを活用したサービスをいくつも提供している。CNTKはSkype翻訳や音声認識の機能を実現するために実際に利用されている。
こうした製品の開発や研究・運用を通して問題点は即座にCNTKへフィードバックされている。
6月には、音声認識のベンチマークで6.3%のエラー率を達成した。ソフトウェアがたったの6.3%しか間違えなかったのだ。人間でも4%近く間違えるので、ほぼ人間レベルまで到達している。その1ヶ月後、電話の書き取りミスを5.9%にまで減らすことに成功した。これは、人間と同程度しか間違えていない。そして最近では、Microsoft Translatorもニューラル翻訳に対応したそうだ。
WindowsのアシスタントCortanaもCNTKを利用していて、生産性を10倍近く向上させている。
Microsoftが開発する女子高生AIの「りんな」もRNN-GRUで出来ている。これもCNTKが実運用されているはずだ。
まとめ
CNTKに限らず、TensorFlowやTorchなど開発速度が速くAPIや使い方、ドキュメントなどそれほど揃っている状況ではない。
開発者の環境やツールもまだまだ進歩しそうだ。
この記事を見て使ってみた人は、是非Web上に学んだことを公開して欲しい。