本記事はAttention and Augmented Recurrent Neural Networksの著者の許諾を得て翻訳しました。
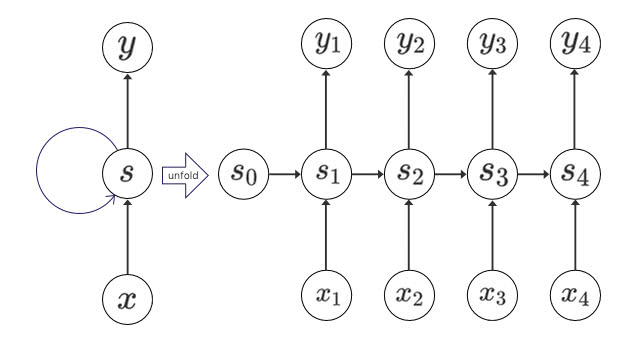
Recurrent Neural Networksは、文章や音声、動画などの順序を持つデータをニューラルネットワークで扱うことができるディープラーニングの重要な要素のうちの1つです。 RNNを使うことで、一連の順序に現れるパターンを抽象的に理解して、注釈をつけたり、まったくのゼロから一連のデータを生成することすらできるのです!

シンプルなRNNの設計では、長期の時系列データには苦戦しますが、「long short-term memory(長期短期記憶) [1]」という種類のネットワークでは、このようなデータでも機能します。 このようなモデルは非常に強力であると分かっており、翻訳、音声認識、画像キャプションを含む多くのタスクで顕著な結果を残しています。結果としてRecurrent Neural Networksはここ数年で幅広い分野に普及しました。
こういったことが起こるにつれて、私たちはRNNを新しい特性で補強しようとする試みが増えるのを見てきました。特に以下の4つの方向性が興味深く際立っています。
-

Neural Turing Machines
読み書き可能な外部記憶を持ちます -

Attentional interfaces
RNNに入力の一部分を注目させます。 -

Adaptive Computation Time
ステップごとに可変の計算量を割り当てることが可能になります。 -

Neural Programmers
実行中に組み立てたプログラムを呼び出すことができます。
個々の特性を見ると、これらのテクニックはすべてRNNの強力な拡張ですが、本当に印象的な点は、一緒に組み合わせることができる点で、まだまだ応用先がたくさんあるように見えることです。さらに、それらはすべて同様のAttentionと呼ばれるトリックを使って実現しているのです。
私たちの推測では、これらの「拡張RNN」は、ディープラーニングの能力を今後の数年で拡張する上で重要な役割を果たすことでしょう。
Neural Turing Machines
Neural Turing Machines [2] は、RNNと外部のメモリバンクを組み合わせています。 ベクトルはニューラルネットワークにとっての共通言語であるため、メモリはベクトルの配列となっています。

しかし、メモリのアクセスはどのように動作するのでしょうか。問題となっているのは、それらを微分可能にしたいということです。 特に、私たちはメモリにアクセスする位置変数で微分可能にすることで、アクセスする位置を学習することができるようになります。 これは、メモリアドレスが根本的に離散的であるように見えるので、意外と困難です。 NTMは非常に賢明な解決策をとっています。 すべてのステップで、すべての位置に異なる量のアクセスをするのです。
一例として、読み込みについて考えてみましょう。 単一の場所を指定する代わりに、RNNは異なったメモリの領域をどのくらい気にしているかを表す「注目分布」を提供します。 その分布から、読み出し操作の結果は加重合計となります。
同様に、私たちはすべての位置に、一度に異なる量を書きこみます。 繰り返しになりますが、注目分布はすべてのメモリ領域に対して、それぞれ書き込む量を表します。 ここで、メモリ内の位置の新しい値は、古いメモリの内容と書き込み値とを、その位置におけるAttentionの重みで凸結合した値によって決定されます。
しかし、NTMはどのようにしてメモリ内のどの位置に注目するべきか決めているのでしょうか。 実際には、異なった2つの手法を組み合わせています。コンテンツベースの注目と、位置ベースの注目です。 コンテンツベースの注目は、NTMがメモリを検索し、探しているものに合った場所に焦点を当てます。一方で、位置ベースの手法はメモリ内の相対的な移動に注目して、NTMをループさせることができます。
メモリアクセス可能なこの機能のおかげで、従来のニューラルネットワークには出来なかった様々なシンプルなアルゴリズムをNTMで実行できます。 たとえば、長い時系列データをメモリに格納し、格納されたデータが何度も繰り返すことを学習することができます。 NTMがやっているように、私たちはNTMが何をしているのかをよりよく理解するために、アクセスしているところを見ることができます。

[3]のさらなる実験を参照してください。この図は、反復コピーの実験結果を表したものです。
NTMは、ルックアップテーブルを模倣することを学ぶこともできますし、数字を並べ替えることもできます(チートのようなものですが)! 一方、まだ基本的な足し算や掛け算のようなことをすることができないのです。
NTMの原論文以来、同様の方向性を模索しているエキサイティングな論文がいくつも発表されました。 Neural GPU [4] は、NTMが足し算や掛け算ができないことを克服したものです。 Zaremba&Sutskever [5] は、原論文で使用されている微分可能なメモリアクセスの代わりに強化学習を使用してNTMを訓練します。 Neural Random Access Machines [6] はポインタに基づいて動作します。 スタックやキューのような微分可能なデータ構造について検討した論文もあります [7,8]。 また、Memory Networks [9,10] も同様の問題を克服しようとする試みです。
客観的には、足し算のようなタスクを実行することができるモデルを学習することはそれほど難しく感じません。 これまでのプログラミングコミュニティにとっては、そんなことは楽勝でしょう。 しかし、ニューラルネットワークには従来出来なかったことが数多くできます。そして、Neural Turing Machinesのようなモデルはさらにその能力の限界を打ち破ったように感じています。
ソースコード
これらのモデルには数多くのオープンソース実装があります。 Neural Turing Machineのオープンソースの実装には、Taehoon Kimの実装(TensorFlow)、Shawn Tanの実装(Theano)、Fuminの実装(Go)、KaiSheng Taiの実装(Torch)、Snipの実装(Lasagne)などがあります。 Neural GPUの原論文のソースコードはオープンソースで、TensorFlow Modelsリポジトリにあります。 Memory Networksのオープンソース実装には、Facebookの実装(Torch / Matlab)、YerevaNNの実装(Theano)、Kim Taehoonの実装(TensorFlow)などがあります。
Attentionインターフェース
文章を翻訳するときに、私は今まさに翻訳しようとしている単語に特に注意を払っています。録音した音声を書き写しているときには、今まさに書き写している部分を慎重に聞いています。私が座っている部屋を説明するように求められれば、私が説明している物を見ながら説明することでしょう。
ニューラルネットワークもAttentionを使うことによって、私たちと同じように与えられた情報の一部分に注意を向けた振る舞いをすることができます。 たとえば、別のRNNの出力を考慮することができるRNNがあるとします。このRNNは、タイムステップごとにもう一方のRNNの出力の異なった位置に注目し、焦点を当てることができるものです。
どこに注意を向けるべきかを学んでもらうために、異なった注目度を考慮できるようにしたいですね。 そうするためには、Neural Turing Machinesと同様のトリックを使います。つまり、すべてに注目しながら、注目度合いを変えるのです。

通常、注目度分布は、コンテンツベースのAttentionをもとに生成されます。 別のRNNの注意を向ける側のRNNは、何を重視したいのかを記述するクエリを生成します。 どれほどクエリーとマッチするかのスコアを生成するクエリと各項目との内積を計算します。その結果をsoftmax関数に適用して注目度分布は算出されます。

2つのRNNの間にAttentionインターフェースを適用する例として翻訳[11]があります。 従来のsequence-to-sequenceモデルでは、入力全体を単一の意味ベクトルに要約してから、それを再構築する必要がありました。 Attentionではそのようなことはせずに、まず入力を処理するRNNに各単語についての情報を渡して、出力を生成するRNNに関連のある単語に注意を向けさせる手法をとります。
こういった複数のRNNの間にAttentionを使う手法には、数々の応用事例があります。 例えば、音声認識 [12] に活用することができます。1つのRNNに音声を処理させて、もう1つのRNNに関連する部分に注意を向けさせて認識結果を生成するのです。
この種のAttentionの他の用途にテキスト解析があります。構文解析木 [13] を生成する時にモデルに必要な単語に注意を向けさせたり、会話のモデリング [14] では返答する際に、1つ前の会話部分に注意を向けさせることができます。
Attentionは、Convolutional Neural NetworkとRNNとの間を繋ぐインターフェースとして使用することもできます。 つまり、各ステップで画像の異なった一部分に注意を向けさせることができるのです。 この種のAttentionでよく使われる方法に、画像のキャプションがあります。 まず、CNNが画像を処理して、高水準の特徴を抽出します。 その後、RNNが実行され、画像の説明が生成されます。 説明文の各単語を生成するとき、RNNは画像の関連部分でのCNNの解釈に注意を向けるのです。 この様子を以下の画像のようにはっきりと可視化することができます。
 [3]の図より
[3]の図より
より抽象的に使用可能な場合を定義するなら、ニューラルネットワークの出力が何らかの繰返しの構造となっている場合にはいつでも、Attentionインタフェースを使用することができます。
Attentionインターフェースは、非常に汎用的で強力な技術であることが分かってきました。これから、ますます普及することでしょう。
Adaptive Computation Time
標準的なRNNは、各タイムステップで同じ量の計算をします。 これは直感的ではありません。 疑う余地もなく、より難しい事柄ではもっと考えなければならないでしょう? さらに、長さが \(n\) のリストに対しての操作は、 \(O(n)\) に制限されてしまうのです。
Adaptive Computation Time [15] は、RNNが各ステップごとに異なる量の計算を行う方法です。 全体像のアイデアはシンプルです。RNNが各タイムステップごとに複数の計算ステップを実行できるようにするのです。
ネットワークに何ステップの計算を実行するべきかを学習させるために、異なった実行ステップ数を考慮できるようにしたいと感じるはずです。これまでと同様の方法で可能にしましょう。 実行する離散的なステップ数を決定するのではなく、実行可能なステップ数の全てに注目度の分布を形成します。 最終的な出力は、各ステップでのすべての計算ステップ数とその重みの加重合計です。

上図では、含まれていない機能が少しだけ残っています。 ここでは、3つの計算ステップを含むタイムステップの完全な図を示します。

こちらの図は少し複雑なので、一歩一歩理解していきましょう。 広く捉えれば、いまだにRNNが実行されています。そして、出力は状態の重みの組み合わせです。

各ステップの重みは、「停止ニューロン」によって決定されます。 停止ニューロンは、RNNの状態を監視して、現在のステップで停止すべき確率と考えることができる「停止荷重」を提供するシグモイドニューロンです。

停止荷重の合計は1となります。なので、1からそれぞれの停止荷重を減算していきます。計算結果がεよりも小さくなった場合に停止します。

停止したとき、ε未満で止まるという条件のために、停止荷重の許容値が若干残っているかもしれません。 この許容値をどうするべきでしょうか?技術的には、将来のステップに温存することも出来ますが、こういった計算をしたくないので、最後のステップに付与します。

Adaptive Computation Timeのモデルを学習するときに、「熟考するコスト」という項をコスト関数に追加します。 こうすることで、モデルは使用する計算量を節約するようになります。この項を大きくすればするほど、計算時間を短縮するようになります。この関係はトレードオフとなります。
Adaptive Computation Timeは斬新なアイデアではありますが、似たようなアイデアが元になっているということが非常に重要であると考えています。
コード
現在のところ、Adaptive Computation Timeの公開されているオープンソースには、Mark Neumannの実装(TensorFlow)があります。
Neural Programmer
ニューラルネットワークは、多くのタスクにおいて優れた成果を残していますが、通常の計算をするための基本的な算術のような些細なことですら苦戦することもあります。 通常のプログラミングをニューラルネットワークと融合させて、両者のいいとこ取りが出来れば本当に素晴らしいことでしょう。
Neural Programmer[16]はこういった問題に対する1つのアプローチです。 問題を解決するために、プログラムを作成することを学ぶのです。実際には、正しいプログラムの例を必要とせずにそういったプログラムを生成することを学びます。 つまり、何らかの課題を達成するための手段としてプログラムを作り出す方法を発見する技術なのです。
論文中の実際のモデルは、テーブルに関する質問を、テーブルを照会するSQLライクなプログラムを生成することによって回答します。 しかし、この過程の中には、いくつか複雑な部分があるので、少しシンプルなモデルを考えてみましょう。 算術式を与えられると、その式を評価するプログラムが生成されるモデルです。
生成されたプログラムは一連のオペレーションです。 各オペレーションは、過去のオペレーションの出力を元にして動作するように定義されています。 したがって、オペレーションは「2ステップ前のオペレーションの出力と1ステップ前のオペレーションの出力を追加する」のようなものかもしれません。 このオペレーションは、変数が割り当てられて読み込まれるプログラムよりも、UNIXパイプに似ています。

コントローラRNNが一度に1つのオペレーションとなるプログラムを生成します。 各ステップにおいて、このRNNは、次の動作が何であるべきかについての確率分布を出力します。 たとえば、最初のタイムステップで追加のオペレーションを実行する確率だけが高いかもしれませんが、 2番目のステップでは、乗算または除算についてのオペレーションをするかどうかについての確率は同じくらいで判断に迷うかもしれません。

このようにすることで、一連のオペレーションがどうなるかを示す確率分布を評価することができるようになりました。 各ステップで1回のオペレーションを実行するのではなく、ここでもAttentionのテクニックを応用します。 全てのオペレーションを実行する確率に応じて重み付けして、加重平均したものを出力とします。

ニューラルネットワークの動作中には、導関数が定義可能であれば、このプログラムの出力は確率変数で微分可能となります。 その後に、損失を定義して、正しい回答を出力するプログラムを生成するニューラルネットワークを学習することができます。 こういった手法を使うことで、Neural Programmerは、正しいプログラムの例を必要とせずに、プログラムを生成することができるようになります。 唯一、教師と言えるものは、プログラムが生み出した答えなのです。
ここまでがNeural Programmerのコアアイデアですが、この論文中の使用方法は、算術式ではなくテーブルに関する質問に答えるものとなっています。 すっきり整理するためのトリックがあります:
-
複数の型:Neural Programmerの操作の多くはスカラー値以外の型を扱います。一部の操作では、表の列の選択やセルの選択を出力するものがあります。同じ型の出力だけが一緒にマージされます。
-
入力を参照する:Neural Programmerは、人口のカラムを持つ都市のテーブルが与えられて、「1,000,000人以上の人口がある都市はいくつですか?」といった質問に答える必要があります。このような問題を容易にするために、ネットワークに、回答しようとしている質問の中の定数やカラムの名前を参照する操作をできるようにします。Pointer Network [17]のような方式のAttentionによって、参照されます。
Neural Programmerは、ニューラルネットワークにプログラムを生成させる唯一のアプローチではありません。 別の素晴らしいアプローチとして、Neural Programmer-Interpreter [18]があります。 これは、非常にバラエティに富んだ面白いタスクをこなすことができますが、正解となる教師データのプログラムを必要とします。
私たちは、より伝統的なプログラミングとニューラルネットワークとの間のギャップを橋渡しするこの一般的な空間が非常に重要であると考えています。 Neural Programmerは明らかに最終的な解決策ではありませんが、そこから学ぶべき重要な教訓がたくさんあると考えています。
ソースコード
Question AnsweringのためのNeural Programmerのより新しいバージョンとして、論文の著者のTensorFlowモデルを利用することができます。 また、Ken Morishitaが実装したNeural Programmer-Interpreterもあります。
総括的な今後の展望
紙を使うことができる人間は、ある分野においては、紙を持たない一般的な人間よりも賢いでしょう。 数学的な表記を使いこなす人間は、それを使うことができない人が解けない問題を解くことができます。 コンピュータにアクセスすることによって、アクセスできない人からすると驚異的な偉業を可能にしていることでしょう。
一般的に言って、人間の創造的な経験則による直感と、方程式や言語のような真新しく慎重なメディアとの相互作用が、多くの知性の興味深い形態ではないでしょうか。 時々、そのメディアは物理的に存在し、私たちのために情報を保存し、ミスを防いだり、面倒な計算を代わりにやってくれたりします。 その他の例では、メディアは私たちの頭の中にある普段使っているモデルでもあります。 いずれにせよ、メディアは知性にとっては深く、基本的なことのように思えます。
機械学習の分野における近年の成果の中には、ニューラルネットワークと何かを結びつけたものも出始めています。 このアプローチの例として、「ヒューリスティックサーチ」と呼ばれるものがあります。 例えば、AlphaGo [19]は、囲碁の仕組みをモデル化して、ニューラルネットワークの直感に基いて、囲碁を打つ方法を探索します。 同様に、DeepMath [20]は、数学的な表現を操作するための直感的な部分を補完するために、ニューラルネットワークを使用します。 この記事で取り上げた「拡張RNN」は、汎用的な能力を伸ばすためにRNNを工学的に構築されたメディアと結びつけた別のアプローチです。
自然にメディアと関わることで、私たちは行動をして、結果を観察し、さらに行動を取るという一連の流れが促されます。 このことは、より大きな挑戦に繋がります:私たちはどの行動をするべきかをどのように学ぶのでしょうか? これは、強化学習が扱う問題のように感じますし、実際、そのようなアプローチを取ることもできるでしょう。 強化学習の研究は、本当にこの最も難しい問題に挑戦している最中にありますが、その解決策は使いにくいものです。 Attentionの素晴らしい点は、すべての行動に対して可変的な量の行動をするという方法で、この問題を簡単に回避して解決することができることです。 私たちは、NTMメモリのようなメディアを設計することができるので、すべての行動量を調節し、微分可能にすることができます。 強化学習ではたった1つの道筋しか見えておらず、そこから何かを学ぼうとします。 Attentionはすべての進路の方向を考慮して、進路を再びマージします。
Attentionの大きな弱点は、すべての 「行動」を毎ステップしなければならないということです。 つまり、Neural Turing Machineのメモリ量を増やすといった処理をするたびに、計算コストは線形的に増加するということです。 あなたも、注意を向ける対象が疎であるならば、記憶を向ける対象もわずかで済むということは想像することができるでしょう。
しかし、それはまだ難しいのです。メモリの内容に頼って注意するというようなことをしたいかもしれませんが、それでは愚かなことに、各メモリをいちいち調べる事態に自分を追い込みかねません。 [21] のように、この問題を解決する初期の試みがなされましたが、まだまだ解決には程遠いように感じています。 もし、私たちが線形未満、つまり \(o(n)\) 時間でAttentionを処理することができれば、もっとパワフルになるでしょう!
拡張されたRecurrent Neural Networksとその基礎となる技術は非常にエキサイティングです。 次は何が起こるのを楽しみにしています!
参考
[1] Understanding LSTM Networks
[2] Neural Turing Machines
[3] Show, attend and tell: Neural image caption generation with visual attention
[4] Neural GPUs Learn Algorithms
[5] Reinforcement Learning Neural Turing Machines
[6] Neural Random-Access Machines
[7] Learning to Transduce with Unbounded Memory
[8] Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets
[9] Memory Networks
[10] Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
[11] Neural machine translation by jointly learning to align and translate
[12] Listen, Attend and Spell
[13] Grammar as a foreign language
[14] A Neural Conversational Model
[15] Adaptive Computation Time for Recurrent Neural Networks
[16] Neural Programmer: Inducing Latent Programs with Gradient Descent
[17] Pointer networks
[18] Neural Programmer-Interpreters
[19] Mastering the game of Go with deep neural networks and tree search
[20] DeepMath - Deep Sequence Models for Premise Selection
[21] Learning Efficient Algorithms with Hierarchical Attentive Memory