Googleは全社的にヘルスケア領域にディープラーニングを活用することに対して積極的です。DeepMindは2016年の7月には大手眼科病院のMoorfieldsとパートナーシップを発表し、眼疾患の早期発見と患者への正しい治療を提供することを目的として共同開発を開始しています。
そして今回、Google BrainチームはJAMAに「Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs」というタイトルで糖尿病網膜症の診察プロセスを変えうる研究成果の発表をしました。
糖尿病網膜症の現状
糖尿病網膜症は、失明の原因とされている疾患で、糖尿病の3大合併症のうちの1つとされています。糖尿病患者のうち米国でおおよそ28.5%、インドで18%もの患者が発症しています。
日本眼科学会の糖尿病網膜症のページによると、日本においても成人の失明原因の第一位とされています。
現状では、非常に高度な研修を受けた医師のみが眼の検査をして発症しているかどうかを診察しています。そして、この世界的な病気を一人ひとり検査できるほど眼科医は存在していません。早期発見できれば有効な治療を受けることで失明を防止することができるでしょう。
糖尿病網膜症を検出する技術
Google Brainのヘルスケアページには機械学習技術をヘルスケア領域に適用していく事に関して以下のようなビジョンを示し、糖尿病網膜症の解決のために舵を切ったと語っています。
ディープラーニングはコンピュータービジョンの分野に革命をもたらしました。ほんの数年前にはSFのように見えていたことを実際に可能にしています。これらの新しいコンピュータービジョンを活用したシステムが人間並みに犬の品種を区別できるのであれば、医療画像を使って病気を識別することに応用できるのではないでしょうか?2年ほど前に、この可能性を探求し始めました。
ディープラーニングを使って自動診察できるメリットは以下のようなことが考えられます。
- 診察の効率性の向上により、早期発見や診察費を下げることができます。
- 医師が不足している地域の人にも診察することができます。
- 診察の再現性が高まります。
- 根本的な医師不足の解決策となります。
さらに、高度な訓練を受けた医師ですら誤診をすることは避けられないでしょう。ヒューマンエラーというのは必ず起きるのです。
データセット
Googleはアルゴリズムの開発にあたって、ディープラーニングに学習させるためのデータセットを構築しています。
インドと米国の両方の医師と緊密に強力して、54名の眼科医と1つの画像あたり3~7名から評価された12万8175枚の開発データセットを使って実験しています。
それぞれのデータセットを以下の画像のように
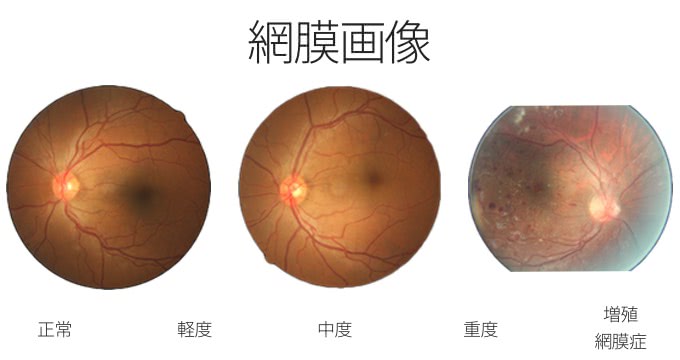
- 正常
- 軽度の糖尿病網膜症
- 中度の糖尿病網膜症
- 重度の糖尿病網膜症
- 増殖網膜症
に医師と強力して分類しています。
アルゴリズム
GoogleはDeep Learningの手法であるConvolutional Neural Networkを使って網膜画像から症状の識別をしています。
Convolutional Neural Networkについて詳しくは以下の記事を参考にしてください。
2014年のILSVRC優良モデルとして勝利したアーキテクチャは、VGGNetとGoogLeNetです。糖尿病網膜症の検出には、このGoogLeNetのアーキテクチャの進化系のInception-v3を採用しています。どちらも、オブジェクト検出や超解像などのコンピュータービジョンのタスクにおいて従来よりも高いパフォーマンスを発揮することができるモデルです。
この両者のモデルの違いは何でしょうか。
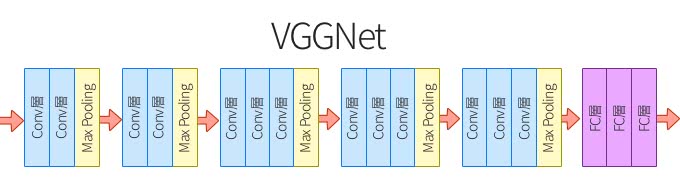
VGGNetは以下の図のように構成をシンプルに保っているものの、計算コストが高いのです。16層のVGGNetのVGG-16では1億3800万ものパラメータを使います。
一方で、以下の図のようにInception-v3は構成は複雑なものの、たったの2500万以下のパラメータしか使用しません。
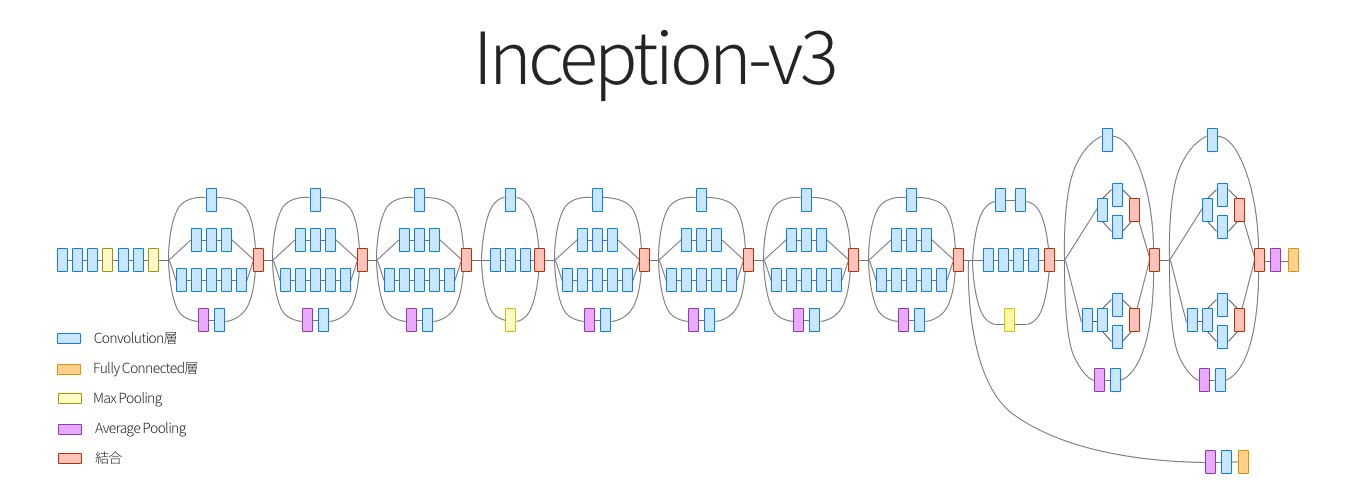
つまり、学習にかかる計算コストやメモリコストを抑えられるので、ビッグデータを扱うが高精度を求める場合には非常に向いているといえます。また、実行環境のメモリや計算リソースなどの制約がある場合には役立つはずです。
糖尿病網膜症の検出モデルは、さらに10個のニューラルネットワークのアンサンブル学習を適用して出力を平均した結果を識別結果とすることで精度を高めています。
結果
テストには2つのデータセットを使っています。どちらも複数の眼科医から評価を受けた網膜画像となっています。
医療の分野では、病気を診断する際の指標として感度と特異度が使われます。コンピューターサイエンスではTrue Positive Rate(Precision)とTrue Negative Rateがよく指標として使われます。以下のように患者の疾患と検査結果を表にすると
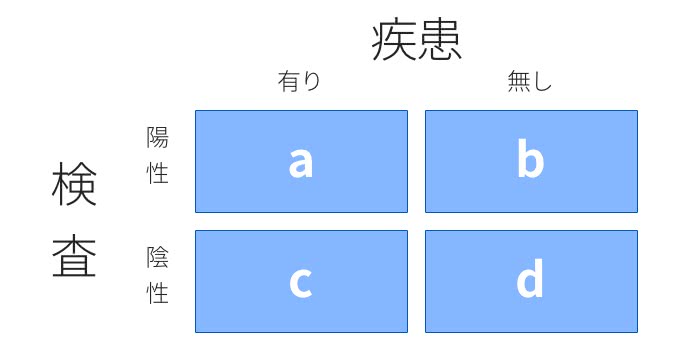
このように計算することができます。
つまり感度は疾患を正しく陽性として診察できた確率で、特異度は疾患のない患者を正しく陰性として診察できる確率となります。
ディープラーニングを使ったアルゴリズムにおいて2つのデータセットで評価したとき、以下の表のような結果となった。正解データは眼科医の選択の多数決となっています。
| データセット名 | 感度 | 特異度 | 眼科医の正答率 |
|---|---|---|---|
| EyePACS-1 | 97.5% | 93.4% | 95.8% |
| Messidor-2 | 96.1% | 93.9% | 95.9% |
ほとんど眼科医と同等の結果となったようです。これまで、Kaggleなどのコンペティションなど開催されてきました。以前もConvolutional Neural Networkを活用したものでしたが、感度と特異度両方において高い成績を残すことが出来ませんでした。膨大な数のデータセットを作ることで高い精度の実験結果を出すことができたのです。
終わりに
今回のGoogleの実験では、医療の現場においても活用しうる可能性が示唆されています。
コンピューターサイエンスの領域でもまだまだ活発に技術が進歩していく中で、こういった実際の現場との協力でフィードバックを得ながら新しい価値を創出することはとても価値あることだと感じています。