
横方向にデータを結合する関数の代表例としてmerge関数があります。
merge関数は細かい設定ができる一方で、3つ以上のDataFrame(もしくはSeries)をまとめて結合することができません。一方で、join関数は3つ以上のデータを結合することが可能になっています。
また、大きな違いの1つとして結合の基準となるキーのデフォルトが異なっており、merge関数では列データからキーを探してくるのが基本でしたが、join関数はインデックスラベルがキー となっている状態がデフォルトです。
結合していくものはインデックスラベルがキーになっている必要があります。
この違いからも、インデックスラベル同士を基準にDataFrameを結合する場合はjoin関数の方が手軽になります。
merge関数の詳しい解説は以下の記事を参考にしてください。
Pandasで2つのデータを横方向に結合するmerge関数の使い方 /features/pandas-merge.html
本記事ではjoin関数の使い方について詳しく見ていきます。
join関数
join関数は冒頭でも触れたように、3つ以上の複数のDataFrame(もしくはSeries)を効率的に結合できる関数となっています。
また、結合する側(右側から結合するデータ)に関してはインデックスラベルが必ずキーとなるのでその点に注意が必要です。
これからは結合される側のデータを左側データ、結合する側(関数の引数に設定される側のデータ)を右側データと呼称することにします。
APIドキュメント
まずはAPIドキュメントから見てみましょう。
pandas.DataFrame.join(other, on=None, how=’left’, lsuffix=’’, rsuffix=’’, sort=False)
params:
| パラメータ名 | 型 | 概要 |
|---|---|---|
| other | DataFrame, nameが設定されているSeries, DataFrameのリスト |
この引数に渡されるDataFrameとSeriesのインデックスラベルはキーとなるため、元のDataFrameのインデックスラベルもしくは特定の列データと対応している必要があります。Seriesを渡す場合はname属性(attribute)を設定する必要があります。 |
| on | name、 nameのリストもしくはタプル |
(省略可能)初期値None 結合される側(左側データ)でキーとなる列データもしくはインデックスラベルを指定します。特に指定のない限りインデックス同士をキーとして結合します。複数の列(もしくはMultiIndexの階層)が指定された場合、結合する側(右側データ)のインデックスラベルはMultiIndexである必要があります。 |
| how | ‘left’,’right’,’outer’ ‘inner’のいずれか |
(省略可能)初期値’left’ 結合する際にどのように結合するかを指定します。 |
| lsuffix | str | (省略可能)初期値’‘ 左側データの被りのあった列ラベル(インデックスラベルのname)の後につける文字列を指定します。 |
| rsuffix | str | (省略可能)初期値’‘ 右側データの炙りのあった列ラベル(インデックスラベルのname)の後につける文字列を指定します。 |
| sort | bool値 | (省略可能)初期値False 結合したあとに、データをソートするか指定します。 |
returns:
結合されたDataFrameが返されます。
このように、結合する際に使用するキーは右側データではインデックスラベルに固定されています。
左側データではデフォルトでインデックスラベルに固定されており、on引数で列データを指定することでキーの値を変更することができます。
how引数で指定できる'left','right','inner','outer'の違いはどちらの集合を優先してとるかという話で、'inner'の場合は両方ともに含まれるもののみを、'outer'の場合はどちらか一方にでも含まれていれば使われます。
以下の記事の冒頭でhow引数ごとの違いの詳しい解説をしています。
Pandasで2つのデータを横方向に結合するmerge関数の使い方 /features/pandas-merge.html
基本的な結合
まずは基本的な使い方となっている、インデックスラベルをキーにした結合を行って見ます。
In [1]: import pandas as pd
In [2]: left = pd.DataFrame({'A':['a', 'b', 'c'],
...: 'B':[ 0, 1, 2] },
...: index=['K0','K1','K2'])
...:
In [3]: right = pd.DataFrame({'C':['aa', 'bb', 'cc'],
...: 'D':[ 0, 2, 4]},
...: index=['K0','K1','K3'])
...:
In [4]: result = left.join(right)
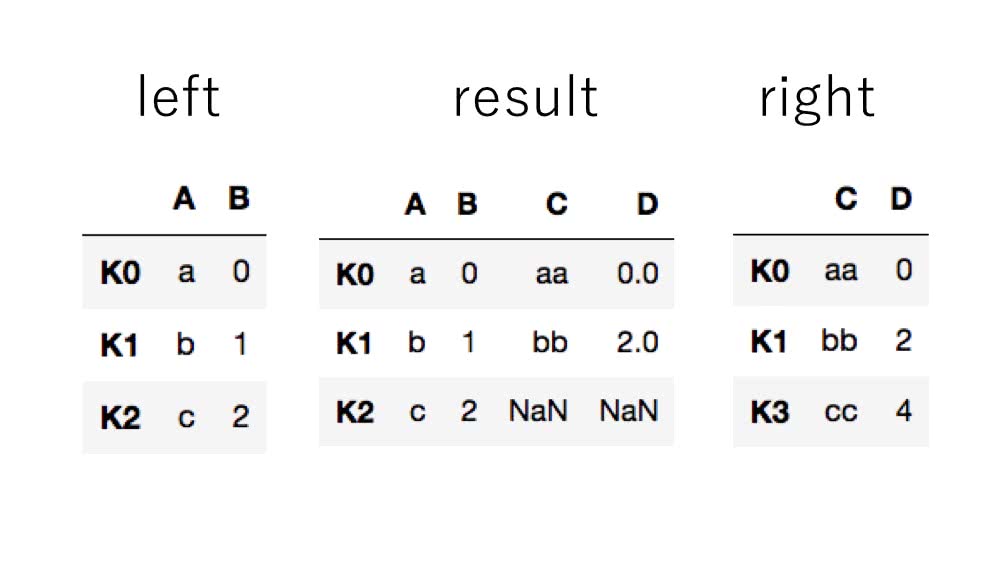
このように、インデックスラベルがキーとなって結合されます。
3つ以上のデータの結合
次は3つ以上のデータを結合してみます。 リストもしくはタプルで指定すれば問題なくできます。
In [5]: left
Out[5]:
A B
K0 a 0
K1 b 1
K2 c 2
In [6]: right_1 = right.copy()
In [7]: right_1
Out[7]:
C D
K0 aa 0
K1 bb 2
K3 cc 4
In [8]: right_2 = pd.DataFrame({'E' : ['A', 'B', 'C'],
...: 'F' : [ 0, 3, 6] },
...: index=['K0','K2','K4'])
...:
In [9]: right_2
Out[9]:
E F
K0 A 0
K2 B 3
K4 C 6
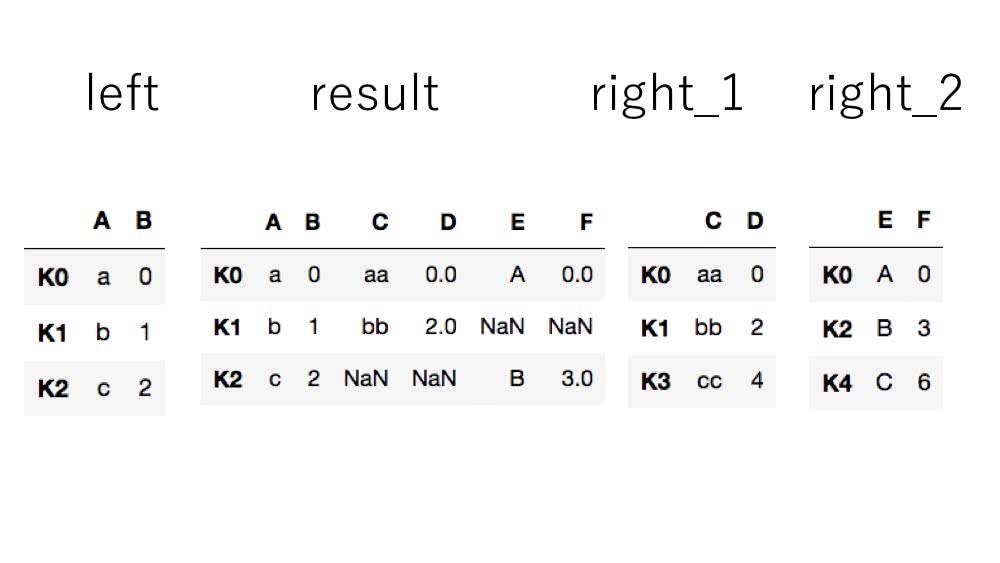
In [10]: result = left.join([right_1, right_2])
In [11]: result
Out[11]:
A B C D E F
K0 a 0 aa 0.0 A 0.0
K1 b 1 bb 2.0 NaN NaN
K2 c 2 NaN NaN B 3.0
図にすると以下のようになります。
Seriesを結合する
次にSeriesを結合していきます。name属性の設定を忘れないようにしましょう。
In [12]: left
Out[12]:
A B
K0 a 0
K1 b 1
K2 c 2
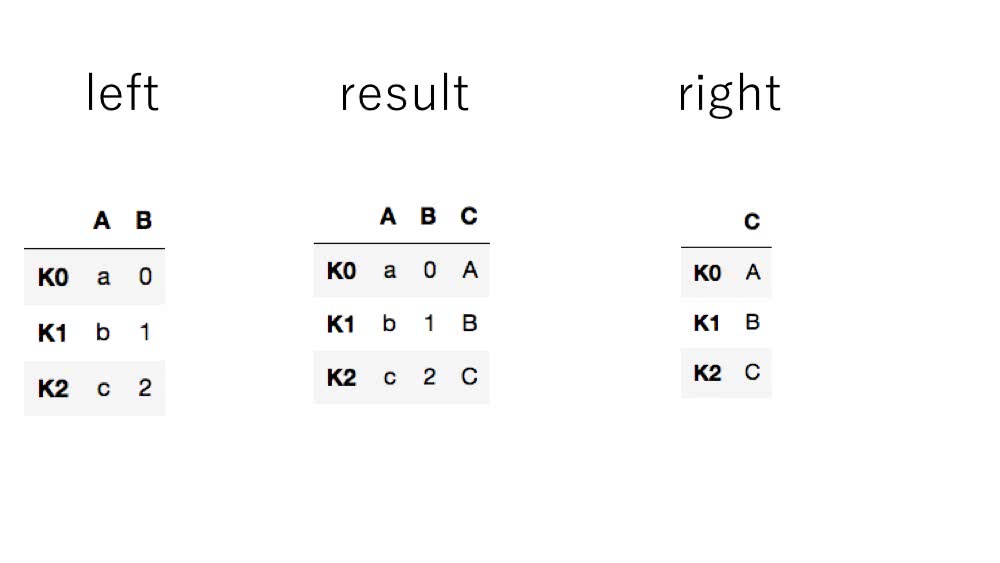
In [14]: right = pd.Series(['A','B','C'], name='C', index=['K0','K1','K2'])
In [15]: result = left.join(right)
図にすると以下のようになります。
結合後のキーの使用範囲を指定する
次に、結合後に使用するキーの範囲を指定します。
how引数で指定することができ、デフォルトではhow='left'となっているため、元のDataFrameのキーのみ使われている設定になっています。
色々変えて確かめてみましょう。まずはデフォルトのhow='left'から指定してみます。
In [16]: right = pd.DataFrame({'C':['aa', 'bb', 'cc'],
...: 'D':[ 0, 2, 4]},
...: index=['K0','K1','K3'])
...:
In [17]: left
Out[17]:
A B
K0 a 0
K1 b 1
K2 c 2
In [18]: left.join(right, how='left') # これがデフォルト
Out[18]:
A B C D
K0 a 0 aa 0.0
K1 b 1 bb 2.0
K2 c 2 NaN NaN
次は両方ともに含まれているキーを使用するhow='inner'です。
In [19]: left.join(right, how='inner') # 両方に含まれているキーなので['K0','K1']
Out[19]:
A B C D
K0 a 0 aa 0
K1 b 1 bb 2
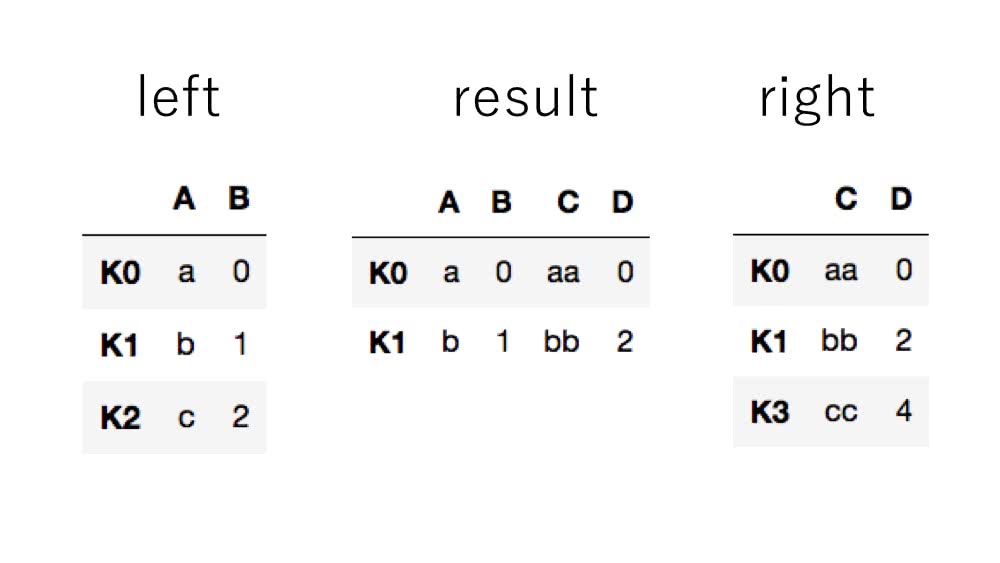 次はどちらか一方にでも含まれていれば使用される
次はどちらか一方にでも含まれていれば使用されるhow='outer'です。
In [20]: left.join(right, how='outer') # どちらかに含まれているキーなので['K0','K1','K2','K3']
Out[20]:
A B C D
K0 a 0.0 aa 0.0
K1 b 1.0 bb 2.0
K2 c 2.0 NaN NaN
K3 NaN NaN cc 4.0
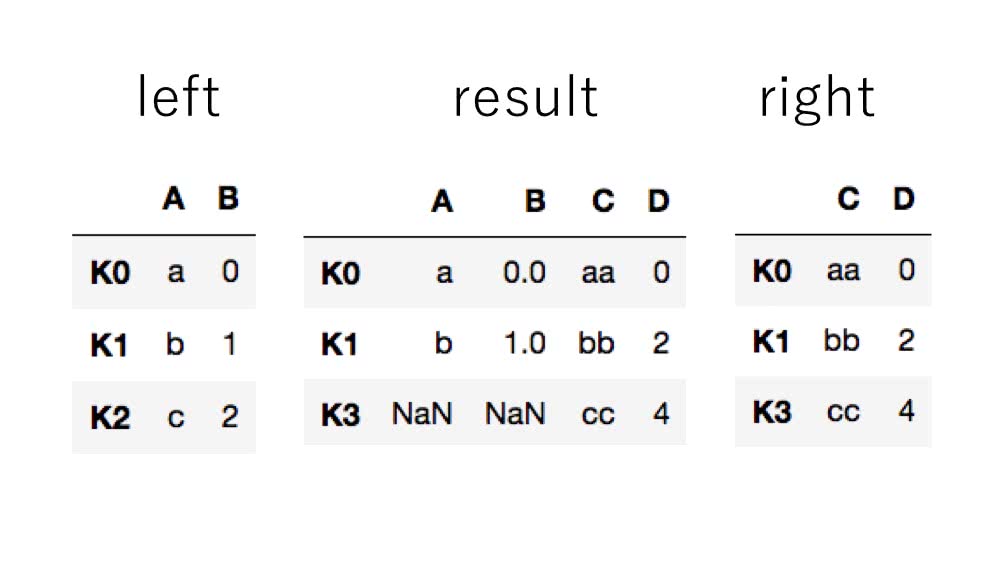
右側データのキーだけを使うhow='right'です。
In [21]: left.join(right, how='right') # 右側データのキーだけを使う
Out[21]:
A B C D
K0 a 0.0 aa 0
K1 b 1.0 bb 2
K3 NaN NaN cc 4
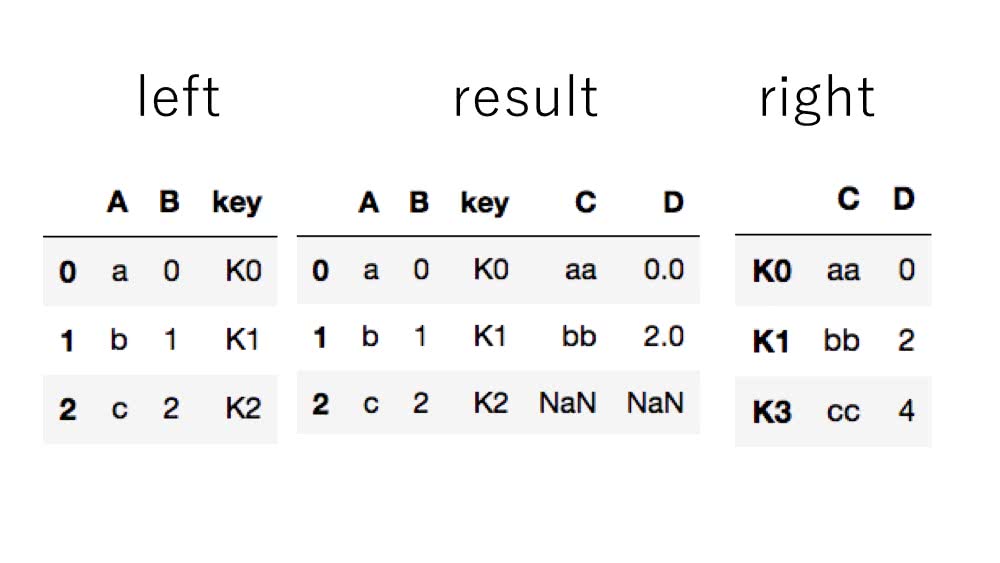
左側データで使うキーを指定する
on引数を使うことで左側データにおいて使用するキーを指定することができます。
あくまで左側データのみとなるのでこれには注意が必要です。
In [22]: left = pd.DataFrame({'A': ['a','b','c'],
...: 'B': [0, 1, 2],
...: 'key':['K0','K1','K2']})
...:
In [23]: right
Out[23]:
C D
K0 aa 0
K1 bb 2
K3 cc 4
In [24]: left.join(right, on='key')
Out[24]:
A B key C D
0 a 0 K0 aa 0.0
1 b 1 K1 bb 2.0
2 c 2 K2 NaN NaN
複数キーを指定する
複数のキーを元に結合させてみます。 この時、右側データはMultiIndexをインデックスラベルに持っている必要があります。
In [29]: left = pd.DataFrame({'A' : [ 'a', 'b', 'c', 'd'],
...: 'B' : [0, 1, 2, 3],
...: 'key1': ['foo', 'bar', 'foo', 'bar'],
...: 'key2': ['A', 'B', 'C', 'A']})
...:
...:
In [32]: right = pd.DataFrame({'C': ['A', 'BB', 'CC', 'D'],
...: 'D': [0, 2, 4, 6]},
...: index =
...: [['foo', 'foo', 'bar', 'bar'],
...: ['A', 'B', 'A', 'C']]) # MultiIndexの作成
...:
In [33]: left.join(right, on=['key1','key2'])
Out[33]:
A B key1 key2 C D
0 a 0 foo A A 0.0
1 b 1 bar B NaN NaN
2 c 2 foo C NaN NaN
3 d 3 bar A CC 4.0
これを図にすると以下のようになります。

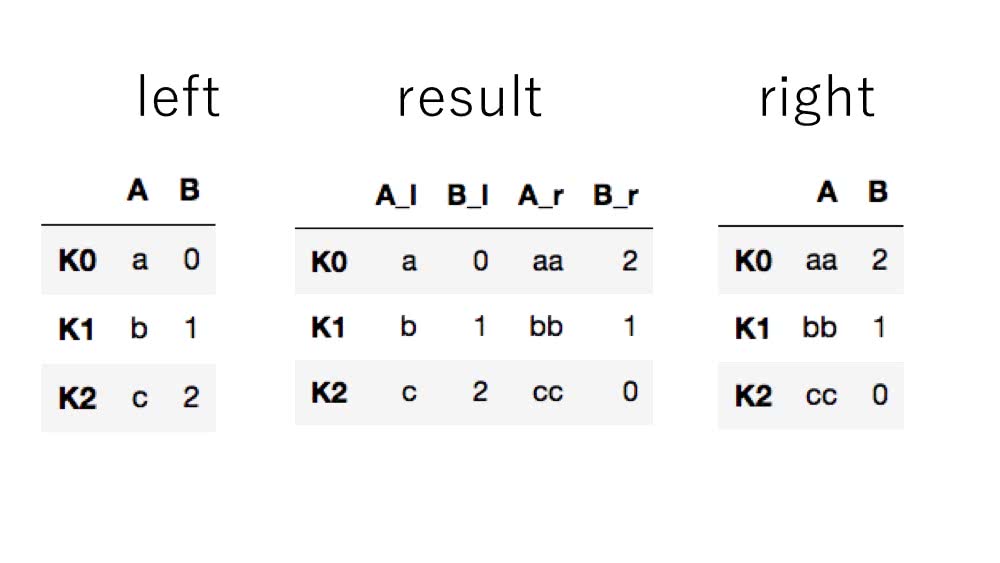
被りのあるカラムラベルに文字列を付け足す
被りがあった時にそれらを識別するため、カラムラベルの後ろに文字列を付け加えることができます。
lsuffixで左側データ、rsuffixで右側データに付け加えられます。
In [34]: left = pd.DataFrame({'A':['a', 'b', 'c'],
...: 'B':[0, 1, 2]},
...: index=['K0','K1','K2'])
...:
In [35]: right = pd.DataFrame({'A':['aa','bb','cc'],
...: 'B':[2, 1, 0]},
...: index=['K0','K1','K2'])
...:
In [36]: left.join(right, lsuffix='_l',rsuffix='_r')
Out[36]:
A_l B_l A_r B_r
K0 a 0 aa 2
K1 b 1 bb 1
K2 c 2 cc 0
まとめ
今回はjoin関数の使い方について解説しました。
merge関数は列データをキーに扱うのに対し、join関数はインデックスラベルをキーに扱うものを得意としています。
merge関数の引数を変えるだけでjoin関数で行っている操作を実現すること自体は可能ですが、設定する項目が多いため少々面倒です。
なので、インデックスラベルを使って結合することが明確な場合はjoin関数を使って結合をし、それ以外の場合はmerge関数に頼るといったようにするとコードの量も煩雑にならずに済むでしょう。
参考
- Python for Data Analysis 2nd edition –Wes McKinney(書籍)
- pandas.DataFrame.join - pandas 0.23.4 documentation
- Merge, join, and concatenate — pandas 0.23.4 documentation