日本語は、英語と違ってスペースで単語が区切られていない。
だから、日本語の自然言語処理においては、まず単語の境界と品詞を推定することから始めることが多い。
このテキストを単語に分割して品詞や意味を推定することを、「形態素解析」という。
本記事では、その形態素解析をニューラルネットワークの一種であるRNNLM(Recurrent Neural Network Language Model)で構築された、JUMAN++を紹介する。
本記事を読むと、
- JUMAN++とRNNLMについて
- MeCabなど他の形態素解析器との違い
- JUMAN++の使い方
が分かることだろうと思う。
JUMAN++とは
JUMAN++は、黒橋・河原研究室から発表されたRNNを使用した形態素解析器で、テキストを単語に分割するために使用する。
古くからあるJUMANという形態素解析器の拡張のような名前をしているが、ロジックや設計が根本から違っている。
言語解析をする上で、格や構文・文脈を推定するタスクもあるが、このタスクが上手くいかない例では形態素解析の失敗が原因であることも多々あるので、形態素解析が精度向上することで、恩恵を受ける分野は多い。
こういった統計的な言語モデルは、文脈から次の単語を予想する問題といえる。
これは、近年劇的に精度向上が見られるディープラーニングの一種であるRNNが得意とすることだ。
事実、ウォール・ストリート・ジャーナルの音声認識のタスクに応用したところ、RNNLMは従来型のn-gramを利用した言語モデルよりも18%もエラー率を抑えることができている。 [1]
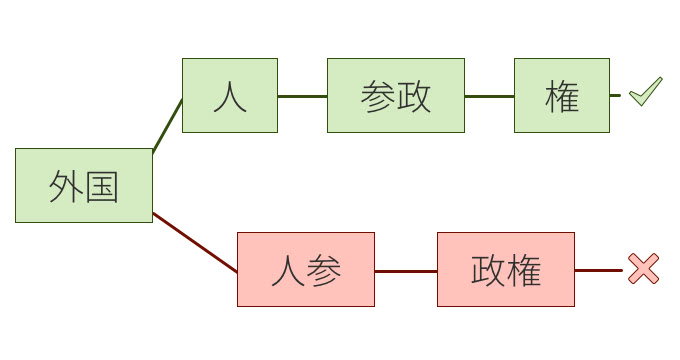
外国人参政権?
「外国人参政権」を形態素解析する例を見てみよう。答えはもちろん、「外国/人/参政/権」である。
これをMeCabで解析してみよう。

外国の人参になってしまった…。
外国人参政権は、「外国/人参/政権」と区切られてしまうのだが、こういった使用頻度が高くない名詞の並びから意味を考慮して区切ることは難しいのだ。RNNLMを使っているJUMAN++では、次の単語を予測するために、単語の並びに対する意味的な自然さも考慮しているため、こういった曖昧な例も正しく分割することができる。
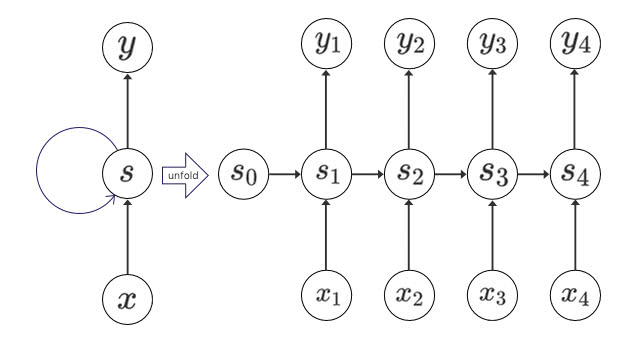
RNNLM
RNNLMは、Word2Vecなんかも提案しているMikolov氏によって発案されたものである。
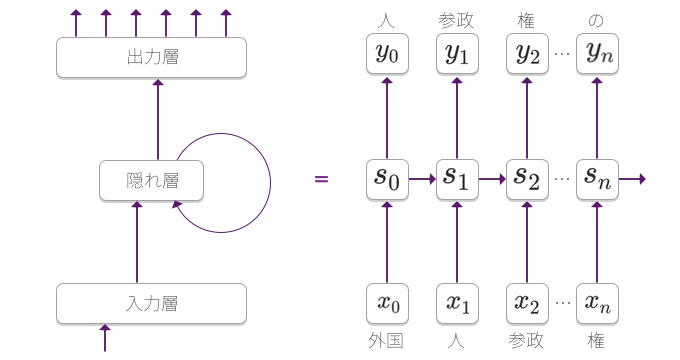
RNNを次の語の予測のために使う。入力層は、単語のサイズのone-hotベクトルか分散表現とする。そして、隠れ層を経て、出力層で次の後の出現確率を求める。
大規模語彙知識
JUMAN++のRNNLMでは、言語モデルを獲得するために、大規模なテキストコーパスを利用している。
以下の表にJUMAN++の学習に使われている辞書一覧をまとめた。
| コーパス名 | 語彙数 | 例 |
|---|---|---|
| 基本辞書 | 3万語 | 走る、行く、明日 |
| Wikipedia | 85万語 | 橋本、お茶の水 |
| Wiktionary | 2千語 | インセンティヴ |
| Web text | 1万語 | 逆進税、政独委 |
| 合計 | 90万語 |
もちろん、語彙を増やそうと思えば自分で追加することができるが、デフォルトでこれだけの語彙を学習してくれているのは嬉しい。
JUMANやMeCabとの比較
では、もうMeCabは時代遅れでJUMAN++一択になってしまったのだろうか。せっかくなのでJUMAN++の全身のJUMANも含めて精度と速度を比較してみよう。
精度
MeCabやJUMANにおいては、Wikipediaなどの大規模辞書を使ったモデルで比較実験をしている。
森田らの実験 [3] では、京都大学テキストコーパス、京都大学ウェブ文書リードコーパスを訓練データと分析用データと精度評価用データに分割し検証したところ、F値は以下の表のようになった。
| 解析器 | 分析用データ | 精度評価用データ |
|---|---|---|
| JUMAN | 97.89 | 97.91 |
| MeCab | 97.99 | 98.00 |
| JUMAN++ * | 98.52 | 98.44 |
* JUMAN++は論文中のRNNLMと部分アノテーションを追加したもの
JUMAN++はF値が最も高いスコアを出している。それだけではない。JUMAN++の誤りの仕方を分析用データで以下の4つに分類したところ
許容できる誤り
- 基準の違い (北極点⇔北極/点)
- 意味的曖昧性に起因するもの (さか/のぼって/みる⇔さかのぼって/みる)
許容できない誤り
- 未知語、複合語の分割誤り (北/大西洋⇔北大/西洋)
- その他 (おすすめな⇔お/すすめ/な)
許容できない誤りの数は、JUMANは合計55個になったのだが、 以下の表のように、995文中で許容できない誤りはたったの10個。さらに、未知語に起因する誤りを除くとたったの9個しか許容できない誤りはないという結果となっている。
| 誤りの種類 | 誤り数 |
|---|---|
| 基準の違い | 138 |
| 意味的曖昧性に起因するもの | 27 |
| 未知語、複合語の分割誤り | 10(1) |
| その他 | 8 |
速度
実用に足りうる速度なのかどうかを検討するために、13193語の文章をそれぞれのツールで形態素解析して、処理を終える時間を手元のMacBook Proで測定してみた。
MeCab
$ time cat test.txt | mecab
cat test.txt 0.00s user 0.00s system 56% cpu 0.005 total
mecab 0.01s user 0.03s system 5% cpu 0.837 total
MeCabは0.01秒で形態素解析を終えている。速い。
JUMAN
$ time cat test.txt | juman
cat test.txt 0.00s user 0.00s system 56% cpu 0.004 total
juman 0.08s user 0.04s system 7% cpu 1.682 total
JUMANは0.08秒形態素解析に時間がかかっている。8倍の時間がかかるようだ。
JUMAN++
$ time cat test.txt | jumanpp
cat test.txt 0.00s user 0.00s system 55% cpu 0.004 total
jumanpp 10.85s user 0.26s system 97% cpu 11.346 total
JUMAN++はなんと、10.85秒形態素解析に時間が掛かっている。ということは、MeCabの1085倍の時間がかかる。時間と精度はトレードオフになっているようだ。ここらへんはJUMAN++の今後の課題と言えそうだ。
JUMAN++とPythonバインディングのインストール
Mac OSをお使いの方は、homebrewから以下のコマンドでインストールすることができる。
$ brew install jumanpp
それ以外の方は、こちらのコマンドでインストールしよう。
$ wget http://lotus.kuee.kyoto-u.ac.jp/nl-resource/jumanpp/jumanpp-1.01.tar.xz
$ tar xvf jumanpp-1.01.tar.xz
$ cd jumanpp-1.01
$ ./configure
$ make
$ sudo make install
これでインストールできたはずだ。以下のコマンドで、インストールしたかを確かめよう。
$ jumanpp -v
JUMAN++ 1.01
もし、コマンドが見つからないと警告が出たのであれば、パスを通す必要がある。
$ sudo echo "include /usr/local/lib" >> /etc/ld.so.conf
$ sudo ldconfig
$ jumanpp -v
JUMAN++ 1.01
続いて、KNPをインストールする。KNPは日本語構文解析器で、JUMANと組み合わせて形態素解析から構文解析までできるようになる。
$ wget http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/knp/knp-4.16.tar.bz2
$ tar xvf knp-4.16.tar.bz2
$ cd knp-4.16
$ ./configure
$ make
$ sudo make install
動作確認をしてみよう。正常にインストールされていれば、以下のような出力が表示されるはずだ。
$ echo "knpとjumanを組み合わせる" | jumanpp | knp
# S-ID:1 KNP:4.16-CF1.1 DATE:2017/01/08 SCORE:-17.62124
knpと<P>─┐
jumanを<P>─PARA──┐
組み合わせる
EOS
続いて、KNPのPythonから利用するために、KNPのPythonバインディングであるPyKNPをインストールしよう。
$ wget http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/knp/pyknp-0.3.tar.gz
$ tar xvfz pyknp-0.3.tar.gz
$ cd pyknp-0.3
$ python setup.py install
JUMAN++の使い方
JUMAN++は、コマンドラインアプリケーションとして使う方法とプログラミング言語から使用する方法がある。
使い方を見るためのファイルを準備しよう。
$ echo "形態素解析の使い方を調べる" > jumanpp.txt
$ cat jumanpp.txt
形態素解析の使い方を調べる
コマンドライン
まずは、コマンドラインを使った使い方から見ていこう。JUMAN++はパイプを使って標準入力からテキストを読みこんで、解析結果を出力する。
$ cat jumanpp.txt | jumanpp
形態 けいたい 形態 名詞 6 普通名詞 1 * 0 * 0 "代表表記:形態/けいたい カテゴリ:形・模様"
素 そ 素 名詞 6 普通名詞 1 * 0 * 0 "代表表記:素/そ 漢字読み:音 カテゴリ:抽象物"
解析 かいせき 解析 名詞 6 サ変名詞 2 * 0 * 0 "代表表記:解析/かいせき カテゴリ:抽象物 ドメイン:教育・学習;科学・技術"
の の の 助詞 9 格助詞 1 * 0 * 0 NIL
使い つかい 使い 名詞 6 普通名詞 1 * 0 * 0 "代表表記:使い/つかいv 連用形名詞化:形態素解析"
方 かた 方 接尾辞 14 名詞性述語接尾辞 1 * 0 * 0 "代表表記:方/かた 同義:名詞:方法/ほうほう 内容語 カテゴリ:抽象物"
を を を 助詞 9 格助詞 1 * 0 * 0 NIL
調べる しらべる 調べる 動詞 2 * 0 母音動詞 1 基本形 2 "代表表記:調べる/しらべる"
EOS
JUMAN++は、N-best解の出力にも対応している。-s オプションを付けることで上位N個の候補を出力する。少し読みにくいが、以下のように最初の行にN-bestスコアの表示され、その後に各行が1つの形態素を表し、形態素の各項目はタブで区切られる。
$ cat jumanpp.txt | jumanpp -s 3
# MA-SCORE rank1:-19.4517 rank2:-19.5028 rank3:-20.1362
- 6 0 0 1 形態 形態/けいたい けいたい 形態 名詞 6 普通名詞 1 * 0 * 0 カテゴリ:形・模様|漢字|特徴量スコア:-3.17429|言 語モデルスコア:-1.6504|形態素解析スコア:-4.82469|ランク:1;2;3
- 8 6 2 2 素 素/そ そ 素 名詞 6 普通名詞 1 * 0 * 0 漢字読み:音|カテゴリ:抽象物|漢字|特徴量スコア:-1.72767|言語モデ ルスコア:-1.70325|形態素解析スコア:-3.43091|ランク:1;2;3
- 16 8 3 4 解析 解析/かいせき かいせき 解析 名詞 6 サ変名詞 2 * 0 * 0 カテゴリ:抽象物|ドメイン:教育・学習;科学・技術| 漢字|特徴量スコア:-0.706863|言語モデルスコア:-0.97845|形態素解析スコア:-1.68531|ランク:1;2;3
- 29 16 5 5 の の/の の の 助詞 9 接続助詞 3 * 0 * 0 特徴量スコア:0.399189|言語モデルスコア:-0.352632|形態素解析スコ ア:0.0465568|ランク:2;3
- 28 16 5 5 の の/の の の 助詞 9 格助詞 1 * 0 * 0 特徴量スコア:0.288716|言語モデルスコア:-0.352632|形態素解析スコア:-0.0639158|ランク:1
- 38 29;28 6 7 使い 使い/つかいv つかい 使い 名詞 6 普通名詞 1 * 0 * 0 連用形名詞化:形態素解析|特徴量スコア:-1.46047|言語モデルスコア:-0.867377|形態素解析スコア:-2.32784|ランク:1;2;3
- 96 38 8 8 方 方/かた かた 方 接尾辞 14 名詞性述語接尾辞 1 * 0 * 0 同義:名詞:方法/ほうほう|内容語|カテゴリ:抽象物|漢字|特徴量スコア:-1.2527|言語モデルスコア:-0.0391932|形態素解析スコア:-1.29189|ランク:1;2
- 95 38 8 8 方 方/がた がた 方 接尾辞 14 名詞性名詞接尾辞 2 * 0 * 0 |漢字|特徴量スコア:-1.88344|言語モデルスコア:-0.0391932|形態素解析スコア:-1.92264|ランク:3
- 98 96;95 9 9 を を/を を を 助詞 9 格助詞 1 * 0 * 0 特徴量スコア:0.280753|言語モデルスコア:-0.165051|形態素解析スコア:0.115702|ランク:1;2;3
- 108 98 10 12 調べる 調べる/しらべる しらべる 調べる 動詞 2 * 0 母音動詞 1 基本形 2 特徴量スコア:-0.30786|言語モデルスコア:-0.527902|形態素解析スコア:-0.835762|ランク:1;2;3
EOS
Pythonから使用する
Pythonから使う場合は、PyKNPモジュールからJUMAN++を呼び出して使う。
from pyknp import Jumanpp
jumanpp = Jumanpp()
result = jumanpp.analysis('形態素解析の使い方を調べる')
for mrph in result.mrph_list():
print('見出し: {}'.format(mrph.midasi))このコードをjumanpp.py として保存して、以下のコマンドで実行しよう。すると、見出しの語と品詞が取得できるようになる。
$ python jumanpp.py
見出し: 形態, 品詞: 名詞
見出し: 素, 品詞: 名詞
見出し: 解析, 品詞: 名詞
見出し: の, 品詞: 助詞
見出し: 使い, 品詞: 名詞
見出し: 方, 品詞: 接尾辞
見出し: を, 品詞: 助詞
見出し: 調べる, 品詞: 動詞
まとめ
JUMAN++はRNNLMを使った新しい形態素解析器だ。そして、その精度は著しく向上している。
だが、まだ速度の面でMeCabには劣るようなので、リアルタイム性が求められる処理や、CPU負荷を掛けられない場合などはMeCabを利用した方が良いだろう。
だが、機械学習の前処理など精度を求められる場合には、積極的にJUMAN++を使っていった方が良さそうだ。
使用用途に合わせて、適切に形態素解析器を使いこなして欲しい。
参考
[1] Recurrent neural network based language model
[2] Morphological Analysis for Unsegmented Languages using Recurrent Neural Network Language Model
[3] RNN 言語モデルを用いた日本語形態素解析の実用化