ディープラーニングなどの機械学習技術の進歩によって、過去のデータから学習する技術は大きく進化し、写真の中に写っている対象を認識することや病気の診断、多言語間の翻訳をする性能を著しく向上させることができました。
すでにその性能は専門的な教育を受けた人間の能力と同等 [1] か超えている分野もあるほどです。
一方で、人間にはデータを与えなくとも自ら経験から学び、スキルを上達させることができます。特に何も教えられなくとも、経験からゲームを攻略することやロボットの正しい動作の仕方を学んでいくことができます。
機械学習の中でも、このようなアプローチで試行錯誤をしながら行動を最適化する手法とるものが強化学習(Reinforcement Learning)と呼ばれる分野です。
本記事では、これから学び始める人やプログラミングして遊んでみたい人、活用してみたい人を対象に
- 強化学習でできることと、応用分野
- 強化学習の概念と基礎知識
- TensorFlowを使った簡単な例での実践
を通して学習や活用の第一歩となるように解説しました。
強化学習の位置づけ
David Silverさんの強化学習のレクチャーであるUCL Cource on RLの最初の講義に分かりやすく強化学習の位置づけに関する解説がされています。
9分あたりに以下の図のようなスライドがでてきます。
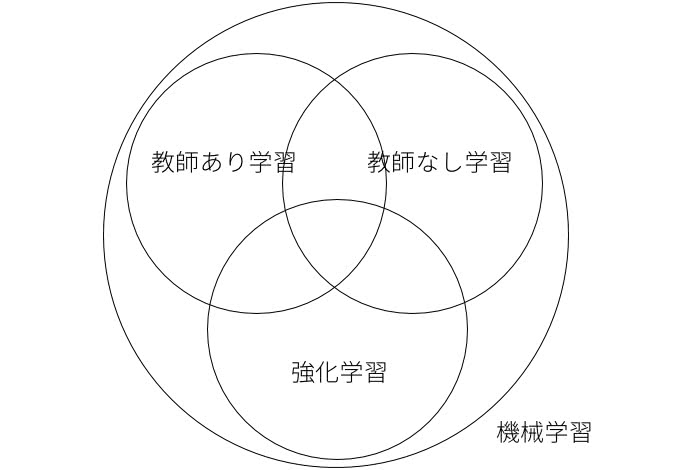
機械学習の中で分野を分類するとしたら次の3つが大半を占めます。これがすべてではないことと、それぞれが重なった学問や応用があることが特徴です。
教師あり学習
教師あり学習は、ある入力値と予測してほしい出力値を含む訓練データセットから、未知の新しい入力値に対してもある程度の予測性能を持つ機械学習モデルを構築することを目的としています。
例えば、はがきに書かれた郵便番号を自動で認識したい場合、入力画像とその出力を揃えることによって、未知の新しいはがきに書かれた郵便番号を自動で認識するものなどです。
もしすでに過去のデータとそれの基づく予測してほしい結果・分類・価値などを持っていたとするなら、教師あり学習を検討したほうがいいですね。
教師なし学習

教師なし学習は、教師あり学習と違って出力値を必要とせずに分類することや、データの分布をモデル化するために使用します。
k-meansなどのクラスタリングがこれにあたります。また、次元削減などの分散表現の獲得も教師なし学習の分野です。次元削減は、ニューラルネットワークなどの教師あり学習の入力値の前処理にもよく使用されます。
強化学習
強化学習は上記の2つとは根本的に問題の設定が違います。
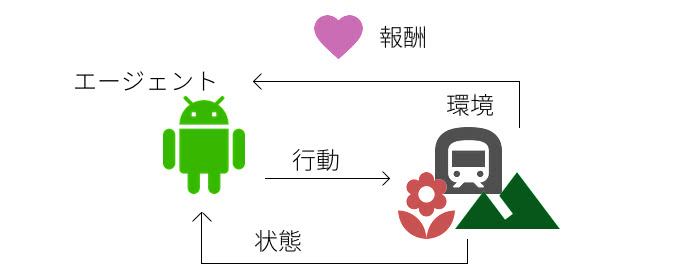
強化学習では、事前に教師あり学習のようなラベル付けされたデータセットが用意されているものではなく、上図のように環境の中で試行錯誤した結果の報酬シグナルしかありません。
行動した結果を元に学習するという考えでは、教師あり学習のようにも考えられますが、探索空間での行動の仕方や行動系列の結果の報酬を最大化するように意思決定の仕方を学んでいくところが特徴です。
強化学習の応用事例
ここ数年、強化学習で成果を残した研究発表が増えてきました。その中でも熱い分野が、ディープラーニングと強化学習を合体させた深層強化学習です。
その結果として、強化学習は、2017年のMIT Technology ReviewのBreakthrough Technologies [2] に選択されているほどです。研究成果の一部を紹介します。
Atariの攻略
DeepMind社が有名になったのは、2013年にAtariのゲームを攻略する論文を公開してからです。この論文では、Atariの6ゲームで人間の能力を上回ることが示されたことがキャッチーで話題を呼びました。
こちらの動画のように、学習が進むと、神業級にゲームを攻略するようになります。特に強化学習のエージェントには、ゲームに登場する障害物の位置などの情報を与えず、生のピクセルデータしか使用していないところが凄いところです。
AlphaGo
囲碁のトップ棋士に勝利して有名になったAlphaGoにも強化学習が使われています。AlphaGoの内部では、碁の盤面から打つ手の有効性を判断するCNNのパラメータを対戦相手への勝利を報酬のフィードバックとして使って強化学習で訓練しています。その後、モンテカルロ木探索で有望な手をさらに深く探索していきます。
この映像は、18歳の最強天才棋士柯潔氏とAlphaGoの勝負です。ゲームは報酬のフィードバックから学習していく強化学習にとって理想的な環境だったことから、アルゴリズムの検証としてよく利用されています。AlphaGoの詳細は以下のページを参考にしてください。
AlphaGo | DeepMind https://deepmind.com/research/alphago/
ロボットの自動動作獲得
エンジニアが動作方法をコーディングする必要性を最小限に抑えるために、強化学習を使ってロボットが行動方法を獲得していく自律型ロボットの研究は以前からなされています。以下の映像は、ドアの開け方を強化学習で自動獲得する研究成果 [3] です。
この実験でも、ロボットに動作方法を人間がデモすることも、知識を与えること無く、複数のロボットで協調しながら自動で動作方法を獲得しています。ハードウェアの進化とDeep Deterministic Policy GradientやNormalized Advantage Functionなどのアルゴリズムが実世界のロボティクスでも現実的な学習速度で行動獲得できるようになったおかげで、このようなことが実現できるようになってきています。
ファイナンスへの応用
環境からのフィードバックを利用して学習する強化学習は、資産管理やリスク管理、価格決定、消費者の信用予測などのファイナンスに対しても相性が良さそうです。中身がブラックボックスなニューラルネットワークは結果を説明しにくいところが難点でしょうか。
実際のところ、利益率を最大化する複利型強化学習 [4] で、ポートフォリオを管理する方法も研究が進んでいます。また、最近では深層強化学習をリアルタイムトレードに応用した事例 [5] も出てきています。
広告配信の最適化
長期的な報酬を最適化することのできる強化学習を使用して、CTRではなく、LTVを指標として広告の配信をする研究 [7] もされています。従来型のレコメンドシステムでは、CTRや購買率のような短期的な指標を使って評価しているものが多いのですが、ユーザの長期的なLTVを元に自動で配信をパーソナライズすることができます。
OpenAI Gymを使ってQ-learningを実装してみる
実際の問題を通して強化学習を理解していきましょう。Open AI Gymを使ってエージェントにゲームの攻略方法を学ばせてみます。
Open AI Gymは、強化学習アルゴリズムの評価・比較のために開発されたPythonライブラリでpipを使ってインストールすることができます。以下のコマンドでインストールします。
$ pip install gym今回は、CartPole-v0をQ学習(Q-learning)で学習させながら理解していきます。
CartPole Balancingは、カートの上に乗ったポールを長い間大きく傾くことなくバランスさせることを報酬として、右に行くか左にいくかの2択の選択をさせます。以下のようにポールがほとんど傾くことなく絶妙なバランスを保つことを覚えさせることを目標とします。
今回の問題を強化学習の設定にあてはめて整理していきます。
強化学習の問題設定は、環境とエージェントとのやりとりを、報酬・行動・状態の3つの変数を使ってフィードバックのやりとりをしながら学習していくことでした。今回は、CartPole-v0問題を環境として、CartPole-v0のプレイヤーのエージェントに攻略させます。
状態
環境から出力される状態 は以下の表の4つの変数からなります。
| 番号 | 名前 | 最小値 | 最大値 |
|---|---|---|---|
| 0 | カートの位置 | -2.4 | 2.4 |
| 1 | カートの速度 | -inf | inf |
| 2 | ポールの角度 | -41.8° | 41.8° |
| 3 | ポールの速度 | -inf | inf |
行動
ある状態からとりうる行動は以下の2つになります。
| 番号 | 名前 |
|---|---|
| 0 | 左にカートを押す |
| 1 | 右にカートを押す |
報酬
報酬はポールが倒れない限り1タイムステップ毎に1得られます。
残りの細かい設定は以下の通りです。エピソードは1つのゲームが終了するまでや少し長期的な期間をまとめたものです。
- 100エピソード連続で195以上の報酬が得られれば成功
- エピソードのタイムステップの長さは最大で200
実装
Open AI Gymを使ってルールに沿って雛形を書いていきましょう。Pythonで以下のコードをcartpole.pyとして保存してください。
import gym
import numpy as np
env = gym.make('CartPole-v0')
goal_average_steps = 195
max_number_of_steps = 200
num_consecutive_iterations = 100
num_episodes = 5000
last_time_steps = np.zeros(num_consecutive_iterations)
for episode in range(num_episodes):
# 環境の初期化
observation = env.reset()
episode_reward = 0
for t in range(max_number_of_steps):
# CartPoleの描画
env.render()
# ランダムで行動の選択
action = np.random.choice([0, 1])
# 行動の実行とフィードバックの取得
observation, reward, done, info = env.step(action)
episode_reward += reward
if done:
print('%d Episode finished after %d time steps / mean %f' % (episode, t + 1,
last_time_steps.mean()))
last_time_steps = np.hstack((last_time_steps[1:], [episode_reward]))
break
if (last_time_steps.mean() >= goal_average_steps): # 直近の100エピソードが195以上であれば成功
print('Episode %d train agent successfuly!' % episode)
breakこのコードは、何も学習はしておらずnp.random.choice([0, 1])を使ってランダムで行動を決定するものです。このまま実行してみます。
$ python cartpole.py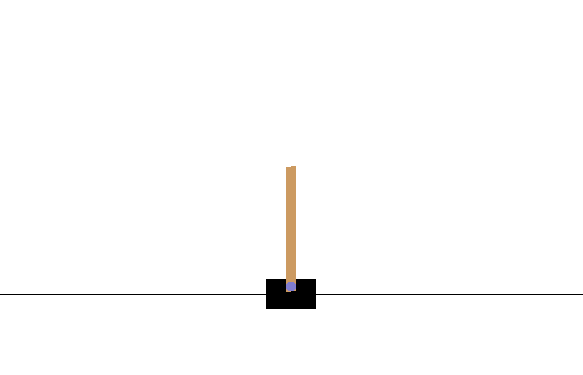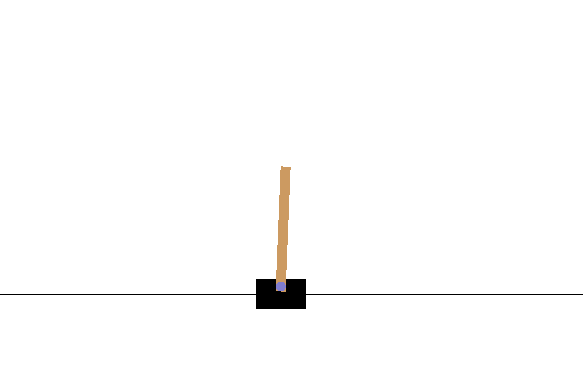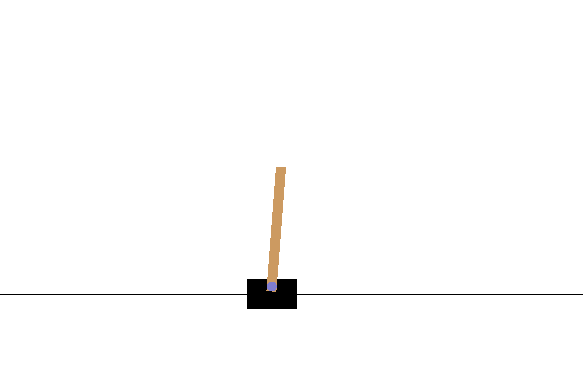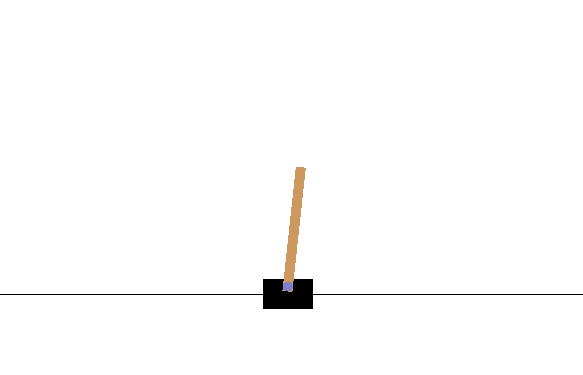
すぐに大きく傾いてしまってエピソードが終了してしまいますね。環境からのフィードバックを使ってバランスをとることを学習させてみましょう。Q-learningは、ある時刻 での状態 のときに取る行動 としたとき、行動価値 を以下の式によって更新するアルゴリズムです。
このとき は学習係数と呼ばれるパラメータで小さな値を使用します。 は割引報酬和のための割引率です。また、タイムステップ で得られた報酬を とします。
難しそうに感じますが、単に多次元配列で価値観数の値を保持して、更新すれば良いだけです。まずは状態を多次元配列で扱えるように離散値にしなければいけないですね。多次元配列のQテーブルを定義して、フィードバックで得られた状態を各値ごとに4個に分割して合計 の離散値に変換する関数を書きます。
q_table = np.random.uniform(low=-1, high=1, size=(4 ** 4, env.action_space.n))
def bins(clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
def digitize_state(observation):
# 各値を4個の離散値に変換
cart_pos, cart_v, pole_angle, pole_v = observation
digitized = [np.digitize(cart_pos, bins=bins(-2.4, 2.4, 4)),
np.digitize(cart_v, bins=bins(-3.0, 3.0, 4)),
np.digitize(pole_angle, bins=bins(-0.5, 0.5, 4)),
np.digitize(pole_v, bins=bins(-2.0, 2.0, 4))]
# 0~255に変換
return sum([x * (4 ** i) for i, x in enumerate(digitized)])それでは先程のQ-learningの数式
に従って、状態から行動を選択する関数を書いていきます。まず、現在の価値関数から最大の価値のある行動を選択した後に数式に従って更新する関数を書いてランダムに選択していた箇所を新しく定義した関数に変更します。
def get_action(state, action, observation, reward):
next_state = digitize_state(observation)
next_action = np.argmax(q_table[next_state])
# Qテーブルの更新
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return next_action, next_state
for episode in range(num_episodes):
# 環境の初期化
observation = env.reset()
state = digitize_state(observation)
action = np.argmax(q_table[state])
episode_reward = 0
for t in range(max_number_of_steps):
# CartPoleの描画
env.render()
# 行動の実行とフィードバックの取得
observation, reward, done, info = env.step(action)
# 行動の選択
action, state = get_action(state, action, observation, reward)
episode_reward += reward
# ...Q関数の実装ができました!それでは変更したスクリプトを動かしてみます。
$ python cartpole.py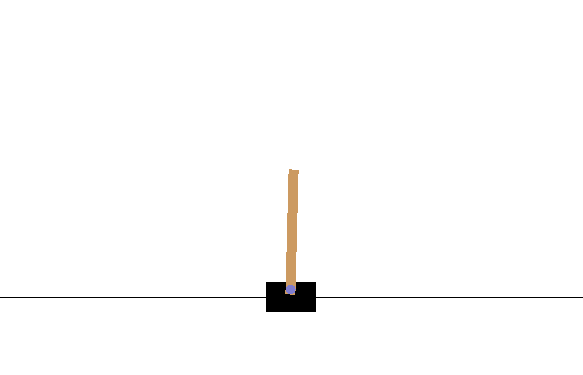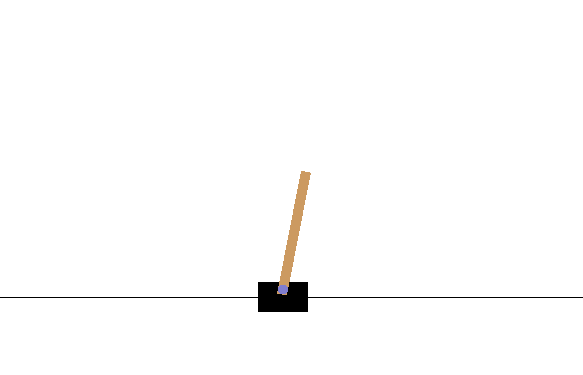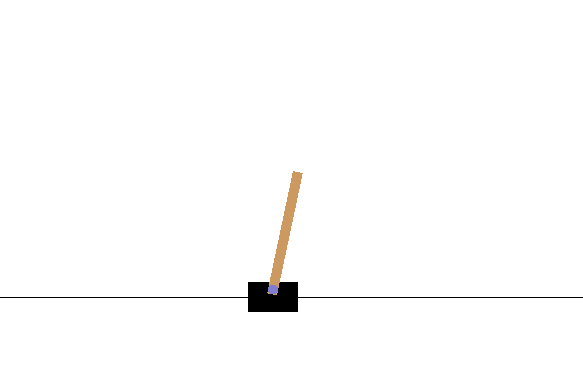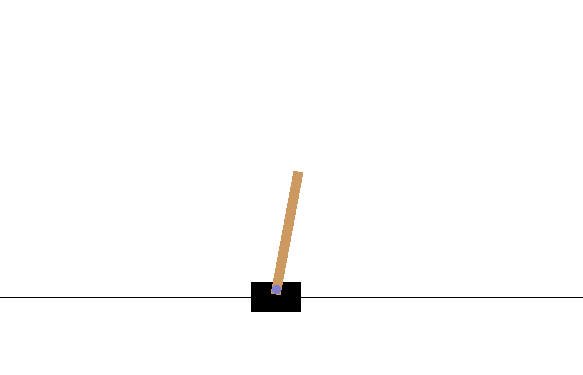
しかしこれでも上手くいきません。何エピソード経ても数ステップ進んだだけで大きく傾いてしまい、すぐに新しいエピソードが始まってしまいます。
エージェントが一番良いと思う行動だけを選択していても、行動の範囲が狭まってしまうからです。エージェントにとってまだ分からない行動の選択肢をとることで、新しい知識を探索しながら学習しなければいけません。しかし新しい知識を探索しすぎると、これまで獲得した知識を利用することができず、報酬はいつになっても増えていきません。このことは、探索と利用のジレンマ(exploration-exploitation dilemma)として知られています。
利用と探索を織り交ぜながら、探索も行いつつ、報酬を確保しなければなりません。ここでは、ε-greedyアルゴリズムを使ってみます。ε-greedyアルゴリズムは、一定の確率でランダムに次の行動を選択するアルゴリズムです。
get_action関数の中身を次のように変更してみましょう。
def get_action(state, action, observation, reward):
next_state = digitize_state(observation)
epsilon = 0.2
if epsilon <= np.random.uniform(0, 1):
next_action = np.argmax(q_table[next_state])
else:
next_action = np.random.choice([0, 1])
# Qテーブルの更新
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return next_action, next_stateこれで実行してみましょう。エージェントはより新しい経験を得られるように一定の確率で探索するようになります。
$ python cartpole.py
随分とバランスを取るのがうまくなりました。しかし5000エピソード経ってもこの答えを解くことができませんでした。学習開始時点では、不確実性が高いためにもっと多い頻度で探索させて、学習が進むにつれて経験を利用するように変更してみましょう。get_action関数を以下のように変更してみます。パラメータが増えたので、get_action関数を呼び出している箇所も変更します。
def get_action(state, action, observation, reward, episode):
next_state = digitize_state(observation)
epsilon = 0.5 * (0.99 ** episode)
if epsilon <= np.random.uniform(0, 1):
next_action = np.argmax(q_table[next_state])
else:
next_action = np.random.choice([0, 1])
# Qテーブルの更新
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return next_action, next_state
# ...
# 行動の選択
action, state = get_action(state, action, observation, reward, episode)
episode_reward += rewardこれで実行してみます。
$ python cartpole.py
惜しいですね。最後に、バランスが取れず失敗してしまったときに罰則を加えてみます。失敗した後の報酬をマイナスの値にして、最後のエピソードの報酬を保存する部分の値をt + 1に変更します。
# ...
# 行動の実行とフィードバックの取得
observation, reward, done, info = env.step(action)
# 罰則の追加
if done:
reward = -200
# 行動の選択
action, state = get_action(state, action, observation, reward, episode)
if done:
print('%d Episode finished after %f time steps / mean %f' % (episode, t + 1,
last_time_steps.mean()))
last_time_steps = np.hstack((last_time_steps[1:], [t + 1]))
break
# ...これで実行してみます。罰則項を加えたことで、悪い動きを覚えてより学習が速くなるはずです。
$ python cartpole.py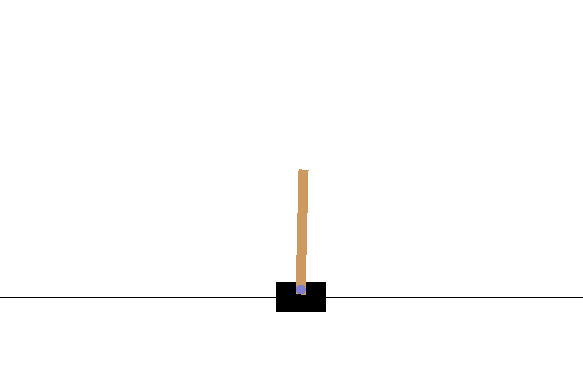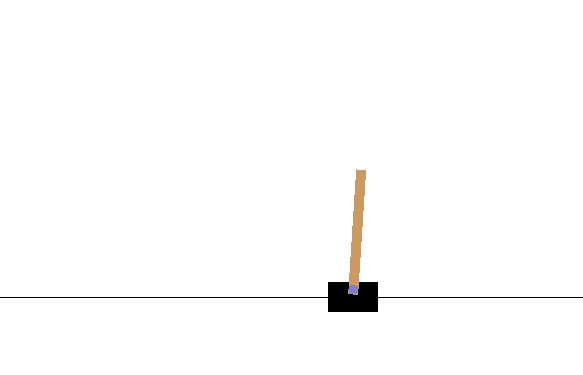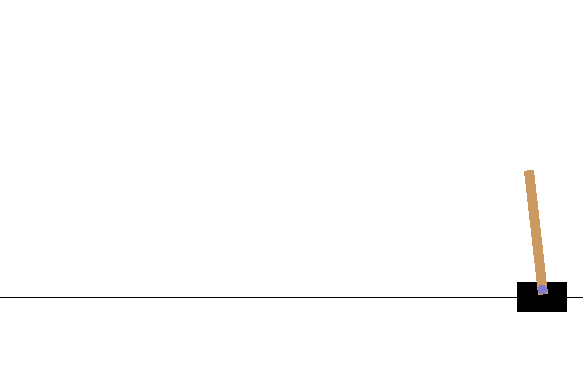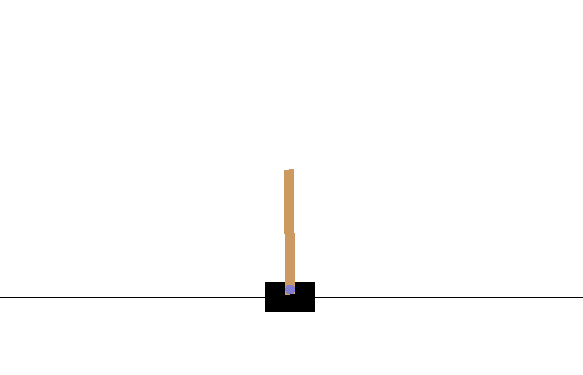
上手に攻略できました!1000エピソード前後で平均が195を超えるようになるはずです。
参考文献
- [1] 通信量75%削減に成功!画像を爆速で高精細化するAI「RAISR」の実力
- [2] 10 Breakthrough Technologies 2017
- [3] Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
- [4] 複利型強化学習
- [5] Deep Direct Reinforcement Learning for Financial Signal Representation and Trading
- [6] DeepMind AI Reduces Google Data Centre Cooling Bill by 40%
- [7] Ad Recommendation Systems for Life-Time Value Optimization