PandasでDataFrameを結合する関数はいくつかあり、DataFrameを横方向に結合する関数として
merge関数とjoin関数とがありました。
-
merge関数は列データをキーとする -
join関数はインデックスラベルをキーとする
という点に違いがあります。またjoin関数では複数のDataFrame(またはSeries)を結合することが可能です。
詳しい解説は以下の記事を参考にしてください。
Pandasで2つのデータを横方向に結合するmerge関数の使い方 /features/pandas-merge.html
Pandas複数のデータをまとめて横方向に結合するjoin関数の使い方 /features/pandas-join.html
今回紹介するconcat関数はただつなぎ合わせるような特徴が強い関数となっており、その分手軽に使うことができます。
しかも、横方向だけでなく横方向の結合にも使える というのが魅力です。
複雑な連結処理をする必要がない場合、concat関数を使って連結するのが簡単でしょう。
concat関数
APIドキュメント
まずはAPIドキュメントから見ていきます。
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
params:
| パラメータ名 | 型 | 概要 |
|---|---|---|
| objs | Series,DataFrameもしくは Panelオブジェクトのシーケンス |
結合したいデータを指定します。辞書形式で渡された場合、ソートされた辞書のキーがkey引数の値として使われます。 |
| axis | 0, ‘index’または 1, ‘columns’ |
(省略可能)初期値0 結合する方向を指定します。デフォルトでは縦方向に結合します。 |
| join | ‘inner’もしくは’outer’ | (省略可能)初期値’outer’ 結合する際にどの集合を使うかを指定します。’outer’にすると各々のデータで1回でも使われていれば含まれます。’inner’の場合、全部のデータに含まれているものだけが含まれます。 |
| join_axes | listもしくはIndexオブジェクト | (省略可能)初期値None 結合の際に使いたいラベルを指定する。これを指定するとjoin引数が無効になります。 |
| ignore_index | bool値 | (省略可能)初期値False Trueにすると結合する軸方向のラベルがリセットされ、0から振り直されます。 |
| keys | シーケンス | (省略可能)初期値None Indexオブジェクトの最も外側の層に追加するラベルを指定します。 |
| levels | シーケンスのリスト | (省略可能)初期値None MultiIndexを構築するために使用する特定の階層(level)を指定します。 |
| names | リスト | (省略可能)初期値None 階層的なインデックスの各階層のname属性を指定します。 |
| verify_integrity | bool値 | (省略可能)初期値None 結合する軸に被りの値が含まれていないかどうかを検証します。 |
| sort | bool値 | (省略可能)初期値True 結合されていない軸方向のデータをソートするかどうかを指定します。 |
| copy | bool値 | (省略可能)初期値True Falseの時、不必要にcopyを作りません。 |
returns:
結合されたDataFrameもしくはPanel
結合した後にどのような整形にするかを指定する引数が多めとなっています。
mergeなどと比較するとかなり意味合いが異なるものもあったりと名称で混乱するケースが多いので1つ1つ抑えていけると良さそうです。
結合の基準となるものは縦方向ならインデックスラベル、横方向ならカラムラベルが基本です。
では実際に使っていきます。
シンプルに結合する
まずはシンプルに縦方向に結合してみます。
In [1]: import pandas as pd
In [2]: df1 = pd.DataFrame({'A' : [ 'A0', 'A1', 'A2', 'A3'],
...: 'B' : [ 'B0', 'B1', 'B2', 'B3']},
...: index = [0, 1, 2, 3])
...:
In [3]: df2 = pd.DataFrame({'A' : ['A4','A5', 'A6'],
...: 'C' : ['C4','C5', 'C6']},
...: index = [4,5,6])
...:
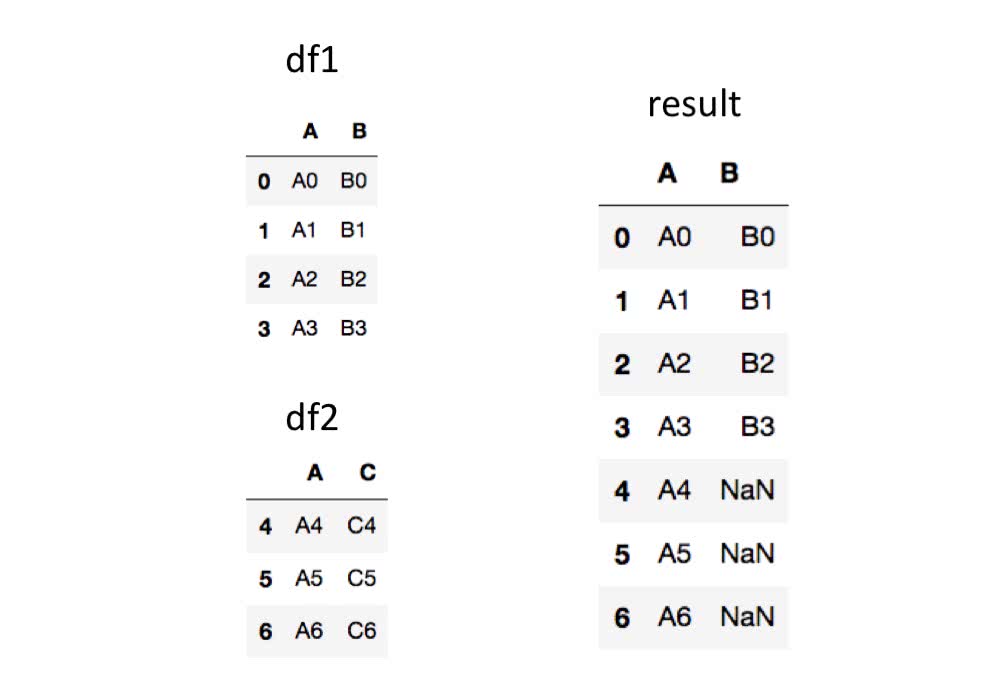
In [4]: pd.concat([df1, df2])
Out[4]:
A B C
0 A0 B0 NaN
1 A1 B1 NaN
2 A2 B2 NaN
3 A3 B3 NaN
4 A4 NaN C4
5 A5 NaN C5
6 A6 NaN C6
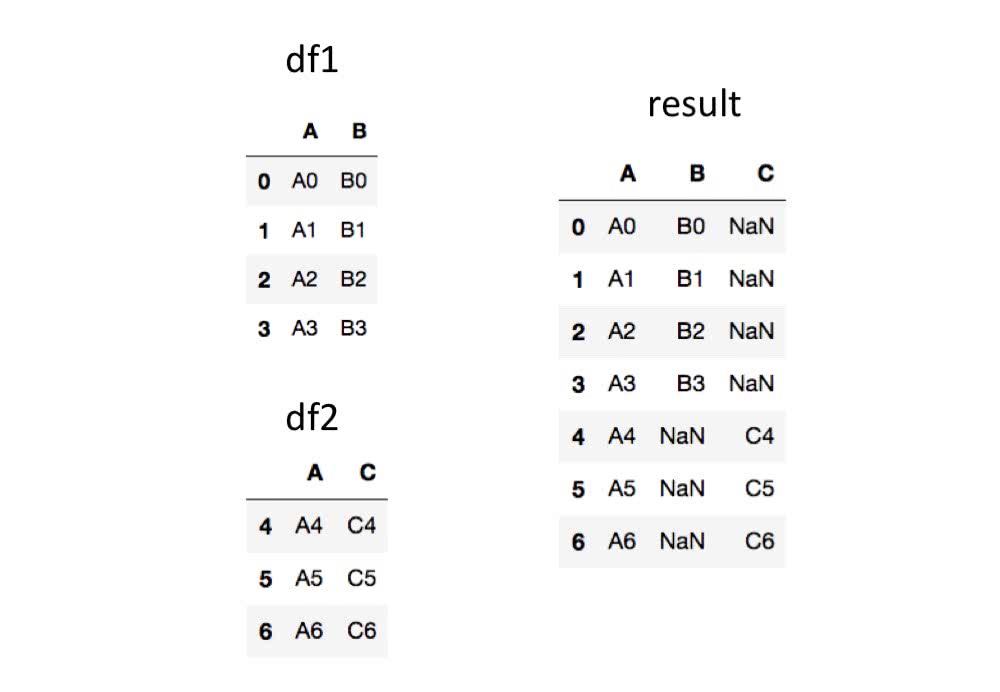
このように結合されます。
列ラベルの値が一致するもの同士が結合されます。 列ラベルの値が存在しない所のデータはNaN値で返されます。
結合の方向を指定する
デフォルトでは縦方向の結合でしたが、今度は横方向で結合してみましょう。
axis引数を設定することで変更可能です。
In [7]: df3 = pd.DataFrame({'C' : ['C0', 'C1', 'C2', 'C4'],
...: 'D' : ['D0', 'D1', 'D2', 'D4']},
...: index=[0, 1, 2, 4])
...:
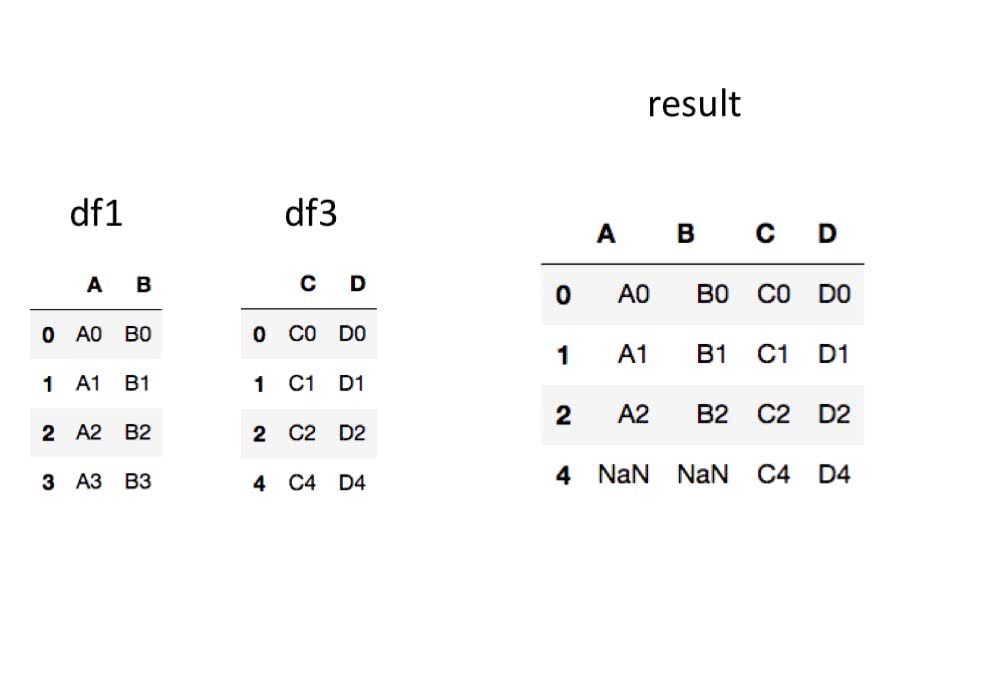
In [8]: pd.concat([df1, df3], axis=1) # もしくはaxis='columns'
Out[8]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 NaN NaN
4 NaN NaN C4 D4
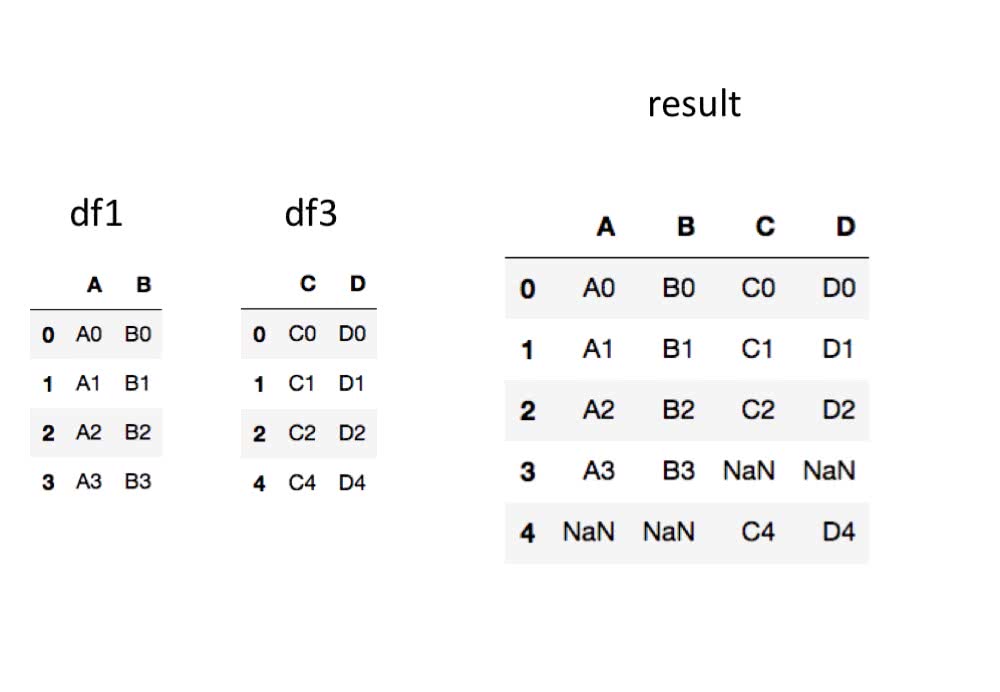
結合したあとにインデックスを振り直す
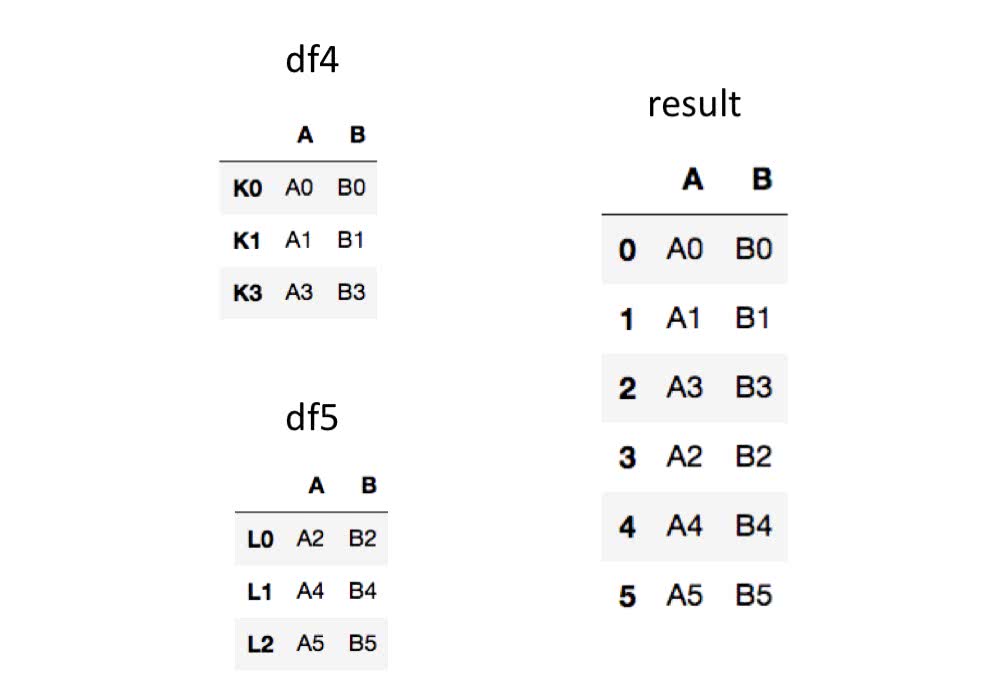
データを連結する際新たにインデックスラベルを0から振り直したい場合はignore_index=Trueにするとできます。
In [11]: df4 = pd.DataFrame({'A':['A0','A1','A3'],
...: 'B':['B0','B1','B3']},index=['K0','K1','K3'])
...:
In [12]: df5 = pd.DataFrame({'A':['A2','A4','A5'],
...: 'B':['B2','B4','B5']},index=['L0','L1','L2'])
...:
...:
In [13]: pd.concat([df4,df5],ignore_index=True)
Out[13]:
A B
0 A0 B0
1 A1 B1
2 A3 B3
3 A2 B2
4 A4 B4
5 A5 B5
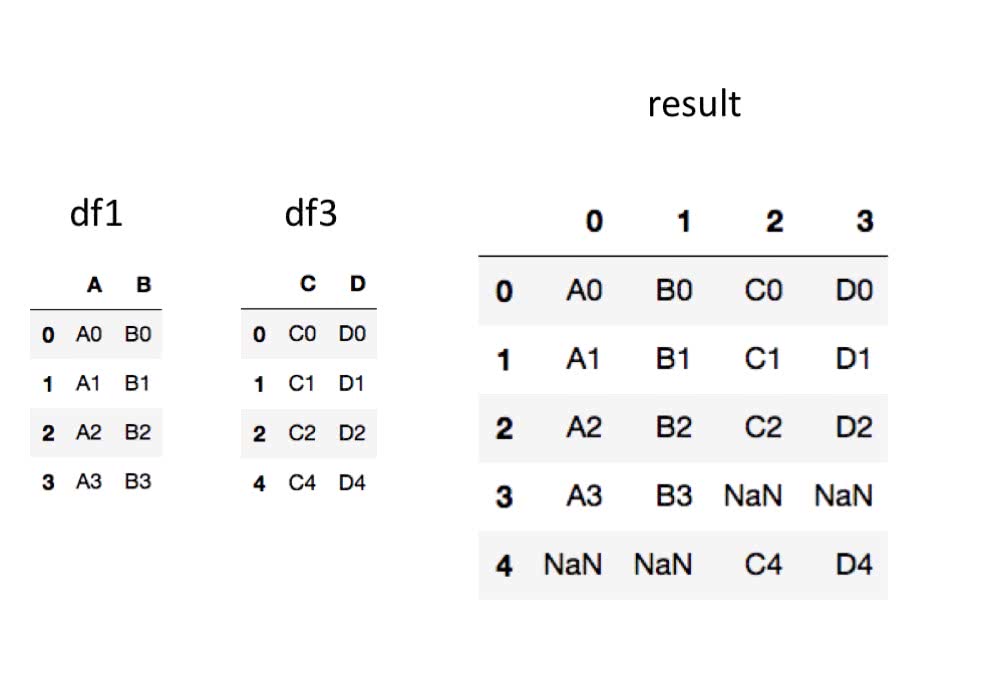
In [10]: pd.concat([df1, df3], ignore_index=True, axis='columns') # 横方向
Out[10]:
0 1 2 3
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 NaN NaN
4 NaN NaN C4 D4
元のデータの判別にラベルをつける
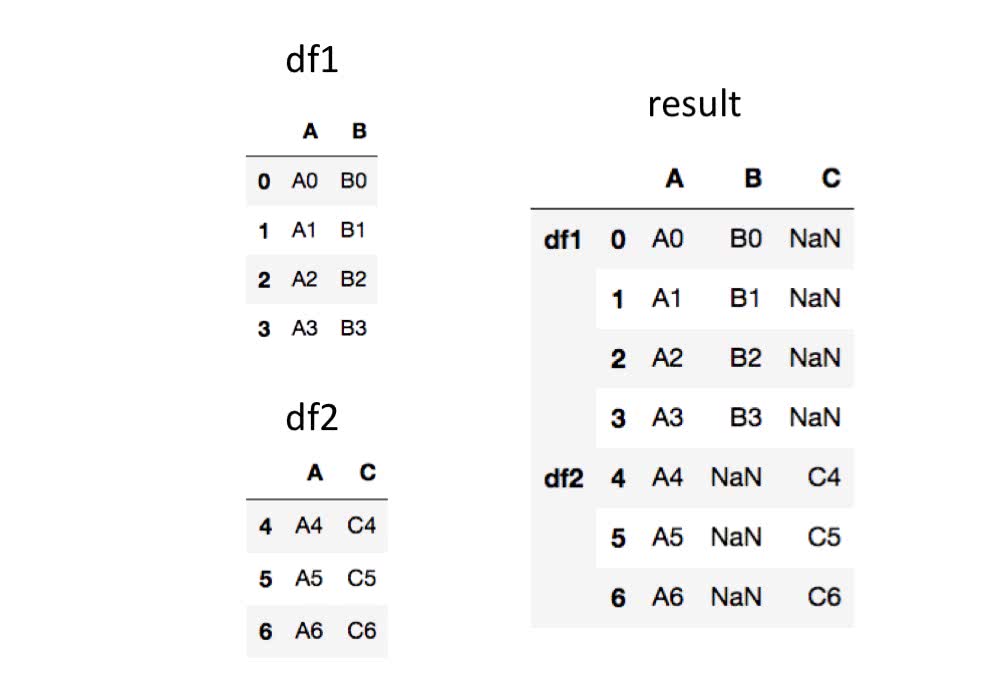
keys引数で各々のデータに対してつけるラベルを指定することができます。
被りのある列ラベル(インデックス)が存在していたとしても、これで判別可能です。
In [16]: pd.concat([df1, df2],keys=['df1','df2'])
Out[16]:
A B C
df1 0 A0 B0 NaN
1 A1 B1 NaN
2 A2 B2 NaN
3 A3 B3 NaN
df2 4 A4 NaN C4
5 A5 NaN C5
6 A6 NaN C6
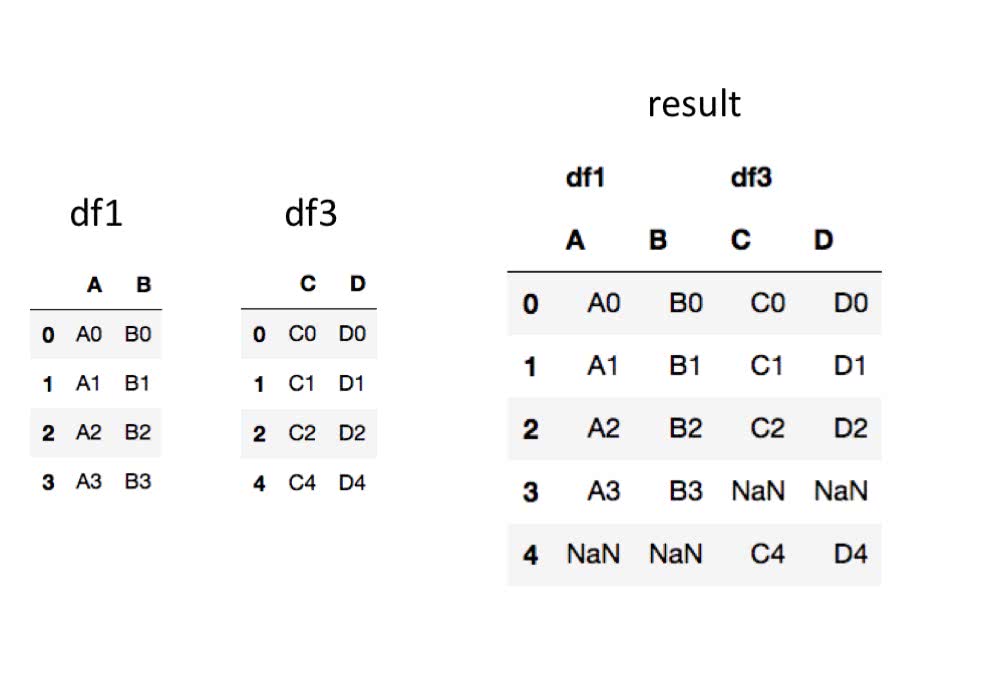
横方向でもできます。
In [17]: pd.concat([df1, df3],axis=1,keys=['df1','df3'])
Out[17]:
df1 df3
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 NaN NaN
4 NaN NaN C4 D4
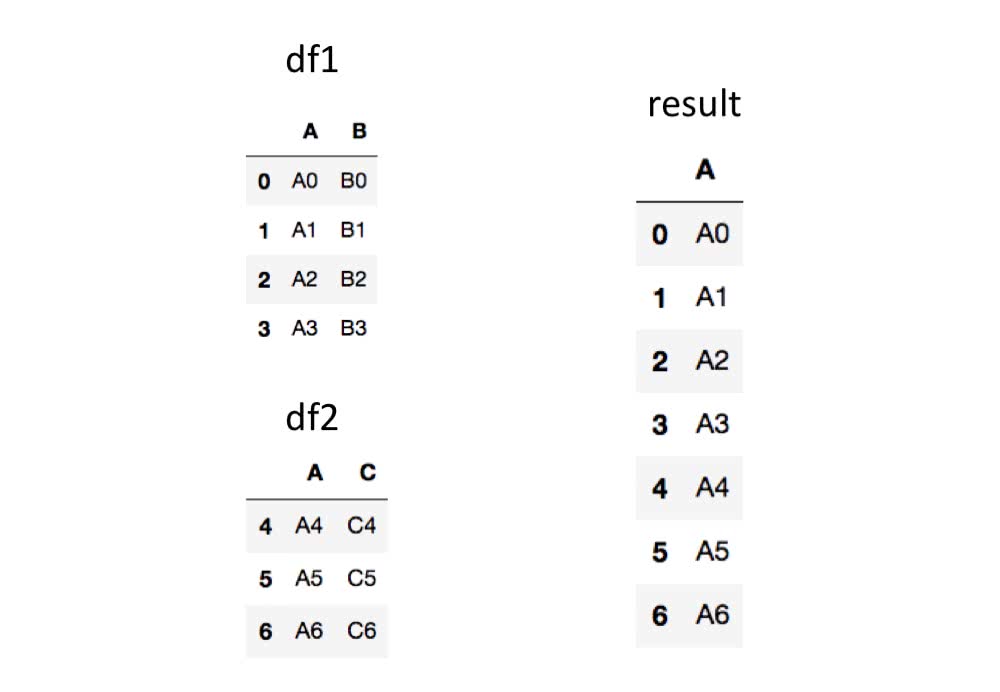
含まれるラベルの範囲を指定する
join引数で結合した結果に含まれるラベルの範囲を指定します。
デフォルトではjoin='outer'になっているため、ラベルがどれか1つでも含まれていれば結合した結果のラベルにも含まれていることになります。
join='inner'に変えることで全てのデータに含まれているラベルのみで構成することができます。
In [18]: pd.concat([df1, df2],join='inner') # A列しか被っていないのでA列だけが表示される
Out[18]:
A
0 A0
1 A1
2 A2
3 A3
4 A4
5 A5
6 A6
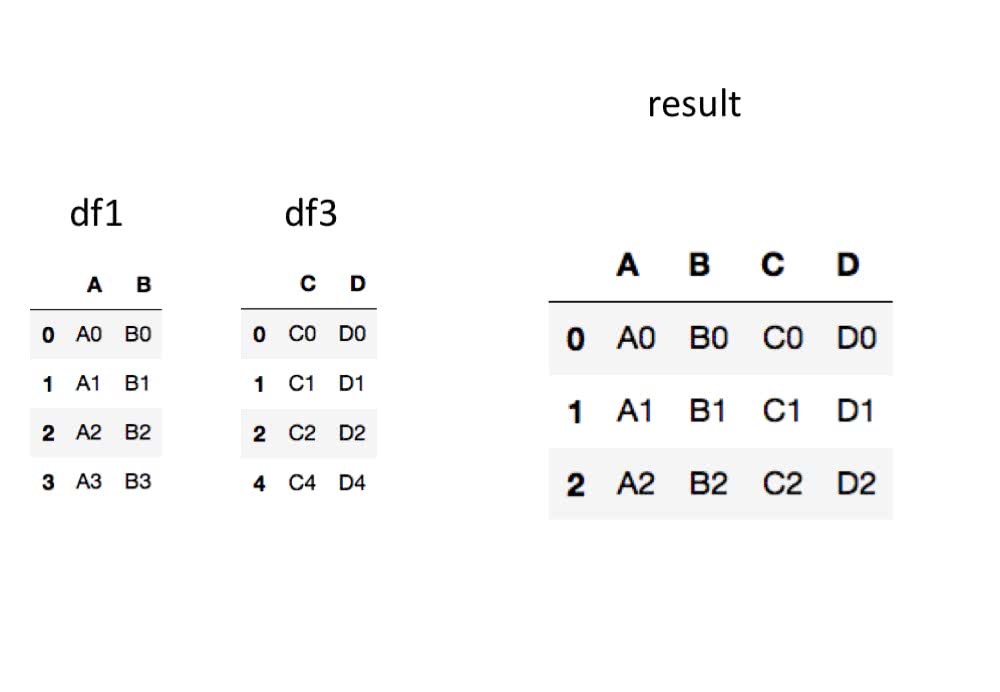
次は横方向です。
In [20]: pd.concat([df1, df3],join='inner',axis=1) # 横方向
Out[20]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
join_axesで具体的な値を指定することができます。
join_axes=[df1.index]と指定すればdf1のインデックスのラベルのみを使用することになります。
In [21]: pd.concat([df1, df2],join_axes=[df1.columns]) # df1のカラムラベルを使う
Out[21]:
A B
0 A0 B0
1 A1 B1
2 A2 B2
3 A3 B3
4 A4 NaN
5 A5 NaN
6 A6 NaN
横方向でもできます。
In [23]: pd.concat([df1, df3],axis=1, join_axes=[df3.index]) # df3のインデックスラベルのみを使用する
Out[23]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
4 NaN NaN C4 D4
まとめ
今回は柔軟な結合を実現するconcat関数の使い方について解説しました。
引数名がややこしいものがありそれらは実際に使って見て感覚を掴む方がイメージがつきやすいと思うので手を動かして覚えていけば良いかと思います。
使い方のイメージとしてはjoin関数のaxisが指定できるようになったバージョンという感じで、結合する際に使用する紐付けを個別に設定できないというところに違いがあります。
これらを使いこなして、データ結合を楽にできるようになりましょう。
参考
- Python for Data Analysis 2nd edition –Wes McKinney(書籍)
- pandas.concat - pandas 0.23.4 documentation
- Merge, join, and concatenate — pandas 0.23.4 documentation