コンピュータサイエンスにおける自然言語処理の目的は、人間が使う言葉をコンピュータに理解させることだ。
コンピュータが自然言語を理解することができるようになると、大規模な計算リソースを使って文書を読み、我々の生活をより豊かにしてくれるだろう。
以前紹介したWord2Vecは、単語をベクトル表現化することで、単語の意味的な表現をコンピュータが扱いやすい数学的表現に変換する自然言語処理でのブレイクスルーだった。
本記事では、そのWord2Vecを単語レベルではなく、文や文書といった任意の長さを扱えるように拡張したDoc2Vecを紹介し、
- 文書をベクトル表現化するDoc2Vecの仕組み
- Doc2VecをPythonのライブラリgensimから使う方法
を解説しようと思う。
Doc2Vecとは何か
Doc2Vecは、任意の長さの文書をベクトル化する技術で、文やテキストに対して分散表現(Document Embeddings)を獲得することができる。
特定のタスクに依存することがないので、以下のような様々な応用方法が考えられる。
- コンテンツベースのレコメンド
- 感情分析
- 文書分類
- スパムフィルタリング
さらに、機械学習のモデルにおける入力には固定長のベクトルが使われることが多いので、事前にDoc2Vecで前処理をして入力ベクトルにすることも多い。
これまでもBag-of-wordsやLDAといった文書を固定長の小さなベクトルにするテクニックはあったものの、Doc2Vecを使うと、これまでのテクニックを凌駕する性能を誇ることが報告されている。 [1]
Wikipediaを使ったDoc2Vecの実験
Wikipediaのデータを使った実験に、日本のレディー・ガガは誰だろうか?という面白い実験がされている。 [2]
単なるベクトルなので、文書ベクトルと単語ベクトルを使って
という演算をしてコサイン類似度で類似したコンテンツを探したところ以下の表のような結果になったそうだ。
| Wikiタイトル | コサイン類似度 |
|---|---|
| 浜崎あゆみ | 0.539 |
| 中川翔子 | 0.531 |
| 坂井泉水 | 0.512 |
| アーバンギャルド | 0.505 |
| 椎名林檎 | 0.503 |
| 春日俊彰 | 0.492 |
| 鬼束ちひろ | 0.487 |
| 安室奈美恵 | 0.485 |
類似したコンテンツのタイトルは、女性アーティストだらけとなっている。浜崎あゆみは日本のレディー・ガガらしい。
Bag-of-wordsの欠点とDoc2Vecのメリット
Bag-of-wordsは文書内の単語の出現回数をベクトルの要素とした分散表現だ。例えば、
{ I, have, a, pen, I, have, an, apple }
という単語区切りの文書があるとしよう。この文書をBag-of-wordsでベクトル化する。ベクトルの並び順をI, have, a, pen, an, appleとすると、
[2, 2, 1, 1, 1, 1]
と表現することになる。単に出現頻度を計算しているだけなので、シンプルで計算効率よく分散表現を得ることが出来る。
では、Bag-of-wordsの何が問題なのだろうか?Bag-of-wordsでは、単語の出現順序が考慮されず、同様の単語が使われていれば同じ表現になってしまう。また、意味的な表現を学習することがないため、ベクトル表現上では「プログラミング」、「Python」、「農業」の3つの単語間の差は同等である。
Doc2Vecのメリットは、教師ラベルを必要としない点である。大量の文書があったとしても、分散表現を得る上では一つ一つの文書にラベル付けしなくても良い。
さらに、Word2Vecのメリットである意味的な表現を学習することになるため、文書中の単語間の距離には差が生まれることとなる。ベクトル表現としては、「プログラミング」と「Python」は「プログラミング」と「農業」よりも近い距離となるはずだ。
Doc2Vecの仕組み
では、Doc2Vecはどのように動作しているのだろう?
Doc2Vecを理解するためには、まずはWord2Vecについて理解することをオススメする。Doc2VecはWord2Vecの単語の分散表現を獲得するテクニックの応用である。
もしあなたがWord2Vecについて聞き覚えがないのであれば、以下を参考にして欲しい。
Doc2Vecには、分散表現を得るための手法が2つ存在している。それは、dmpvとDBoWである。DBoWは単語の順序を考慮しないシンプルなモデルで計算効率が良く、dmpvはDBoWと比べると少し複雑でより多くのパラメータが必要になる。
dmpv(Distributed Memory)
Word2VecのCBoWという手法を思い出して欲しい。
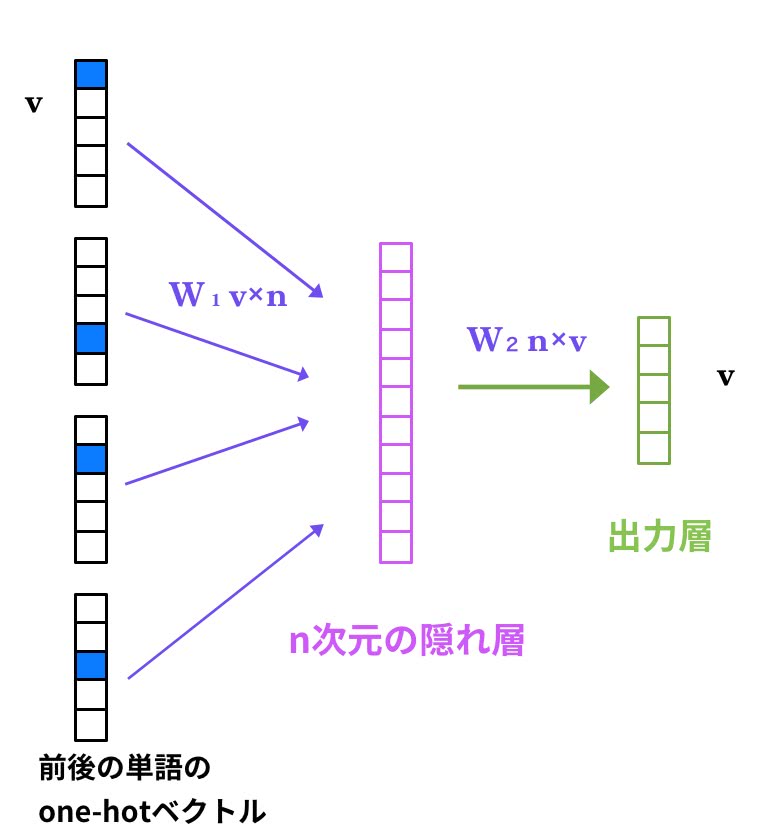
CBoWは前後の単語から対象単語を推測する3層ニューラルネットワークだ。dmpvは、このCBoWの応用で入力ベクトルに単語列だけでなく、ドキュメントIDを付加したものだ。
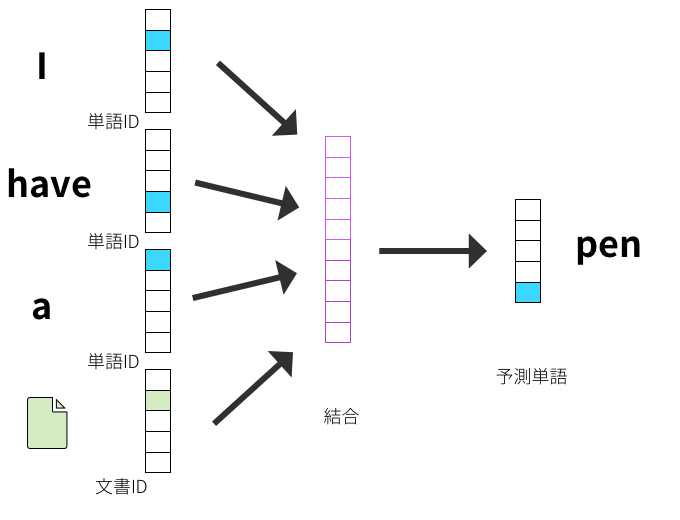
Word2VecのCBoWモデルと同様に、入力層は”コンテキスト”を表し、出力は予測単語として学習する。dmpvでは、文書IDもコンテキストとして保持する意味合いを持つ。
DBoW
一方で、DBoWはWord2VecのSkip-gramと似たようなテクニックを利用する。Skip-gramはCBoWの逆で、単語からその周辺単語を予測する。
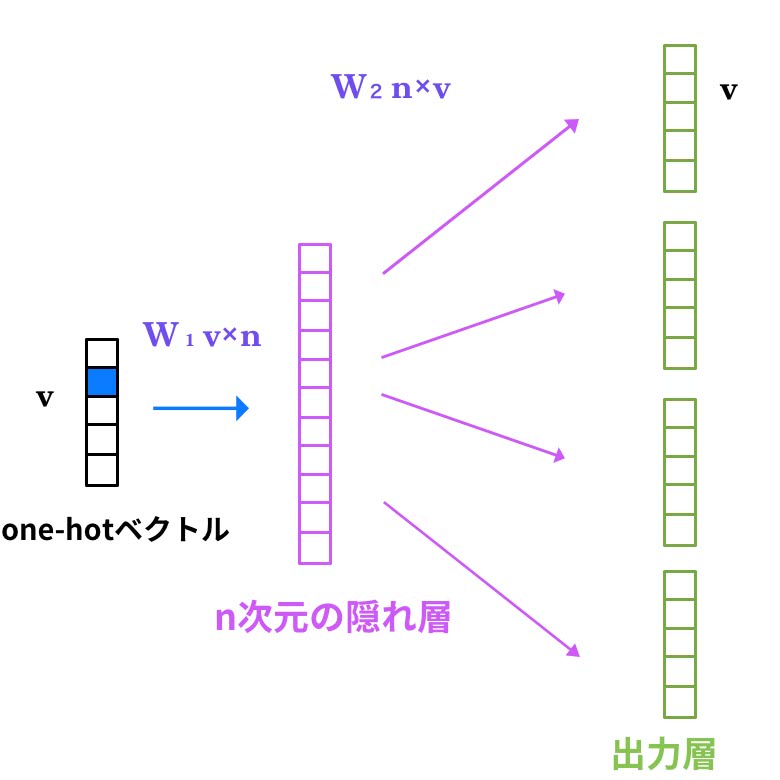
DBoWとSkip-gramの違うところは、入力が文書IDとなっているところだ。
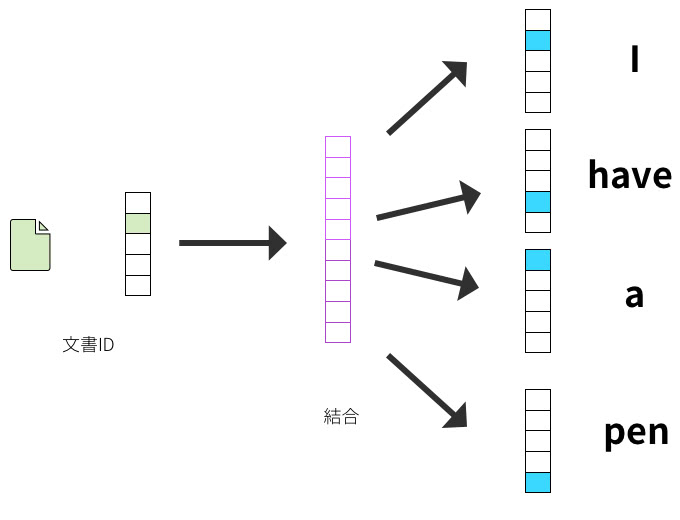
このモデルは、単語の順序が考慮されないBag-of-wordsと同じような性質のため、「Distributed Bag-of-words」と名付けられている。
こちらの方がシンプルなモデルなのでメモリをあまり使わず、効率的に計算できるが、dmpvの方が精度面では優れていると報告されている。 [2]
Doc2Vecを使う上で最適なパラメータ
特定のタスクでの最適なパラメータが割り出されている [1] ので紹介しよう。
実験では、以下の2つのタスクで最適なパラメータを検証している。
- Q-DupというStackExchange上での投稿データを使った、重複質問の検出
- Semantic Textual Similarity (STS)という文の類似度を0~5の範囲で推測するタスク
この実験で最適なパラメータは以下の表のようになった。あなたの扱う問題の複雑さとデータ数を考慮すれば、Doc2Vecのパラメータチューニングの指標になるだろう。
| 手法 | タスク | サイズ | 次元 | 窓サイズ | Min Count | Sub-Sampling | Negative Sample | Epoch |
|---|---|---|---|---|---|---|---|---|
| DBoW | Q-Dup | 4.3M | 300 | 15 | 5 | 5 | 20 | |
| DBoW | STS | 0.5M | 300 | 15 | 1 | 5 | 400 | |
| dmpv | Q-Dup | 4.3M | 300 | 5 | 5 | 5 | 600 | |
| dmpv | STS | 0.5M | 300 | 5 | 1 | 5 | 1000 |
| 次元 | 単語ベクトルの次元 |
| 窓サイズ | コンテキストの周辺単語の数 |
| Min Count | この値よりも出現回数が小さい単語を破棄する |
| Sub-Sampling | 単語の出現頻度がこの値よりも大きい場合は無視されるしきい値 |
| Negative Sample | ネガティブサンプルする単語の数 |
| Epoch | エポックの数 |
この実験では、learning rateは0.025から0.0001に線形に小さくしている。
DBoWはdmpvよりも大きな窓サイズが必要になり、サブサンプリングのしきい値は大きくなる。dmpvはDBoWに比べて複雑なモデルになっているので、より多くのエポックが必要になる。
gensimを使った文書類似度算出
実際に、Doc2Vecをgensimというライブラリから使ってみよう。
今回はライブドアのニュースコーパスを取得して、内容が近い記事をコサイン類似度を使用して取得してみよう。
ライブラリのインストール
gensim
gensimは、主にテキスト解析を対象としたスケーラブルな機械学習ライブラリで、Word2VecやDoc2VecをシンプルなAPIで利用することができる。
gensimは、以下のコマンドでインストールすることができる。
$ pip install --upgrade gensim
JUMAN++
JUMAN++は、黒橋・河原研究室から発表されたRNNを使用した形態素解析器で、テキストを単語に分割するために使用する。
Mac OSをお使いの方は、homebrewから以下のコマンドでインストールすることができる。
$ brew install jumanpp
それ以外の方は、こちらのコマンドでインストールしよう。
$ wget http://lotus.kuee.kyoto-u.ac.jp/nl-resource/jumanpp/jumanpp-1.01.tar.xz
$ tar xvfz jumanpp-1.01.tar.xz
$ cd jumanpp-1.01
$ ./configure
$ make
$ sudo make install
これでインストールできたはずだ。以下のコマンドで、インストールしたかを確かめよう。
$ jumanpp -v
JUMAN++ 1.01
もし、コマンドが見つからないと警告が出たのであれば、パスを通す必要がある。
$ echo "include /usr/local/lib" >> /etc/ld.so.conf
$ sudo ldconfig
$ jumanpp -v
JUMAN++ 1.01
続いて、KNPをインストールする。
$ wget http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/knp/knp-4.16.tar.bz2
$ tar xvfz knp-4.16.tar.bz2
$ cd knp-4.16
$ ./configure
$ make
$ sudo make install
動作確認をしてみよう。正常にインストールされていれば、以下のような出力が表示されるはずだ。
$ echo "knpとjumanを組み合わせる" | jumanpp | knp
# S-ID:1 KNP:4.16-CF1.1 DATE:2017/01/08 SCORE:-17.62124
knpと<P>─┐
jumanを<P>─PARA──┐
組み合わせる
EOS
続いて、KNPのPythonから利用するために、KNPのPythonバインディングであるPyKNPをインストールしよう。
$ wget http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/knp/pyknp-0.3.tar.gz
$ tar xvfz pyknp-0.3.tar.gz
$ cd pyknp-0.3
$ python setup.py install
Doc2Vecで文書を学習させる
それでは、ライブラリの準備ができたので、実際にDoc2Vecで記事データを学習していこう。
まずは学習に必要なデータをダウンロードする。livedoorのニュースコーパスから記事データをダウンロードしよう。
このコーパスは、「livedoor ニュース」からクレイティブ・コモンズライセンスが適用されるニュース記事を収集し、HTMLタグを取り除いて作成されたものだ。
$ wget http://www.rondhuit.com/download/ldcc-20140209.tar.gz
$ tar xvfz ldcc-20140209.tar.gz
Doc2Vecで文書を学習させるコードを書いていこう。まずは必要ライブラリをimportする。
import sys
from os import listdir, path
from pyknp import Jumanpp
from gensim import models
from gensim.models.doc2vec import LabeledSentence次に、記事ファイルをダウンロードしたディレクトリから取得する関数を定義する。
def corpus_files():
dirs = [path.join('./text', x)
for x in listdir('./text') if not x.endswith('.txt')]
docs = [path.join(x, y)
for x in dirs for y in listdir(x) if not x.startswith('LICENSE')]
return docsそして、記事コンテンツをパスから取得する関数を定義する。
def read_document(path):
with open(path, 'r') as f:
return f.read()先程インストールした、JUMAN++を使って記事を単語リストに変換する関数を定義しよう。
def split_into_words(text):
result = Jumanpp().analysis(text)
return [mrph.midasi for mrph in result.mrph_list()]次に、記事コンテンツを単語に分割して、Doc2Vecの入力に使うLabeledSentenceに変換する関数を定義しよう。
def doc_to_sentence(doc, name):
words = split_into_words(doc)
return LabeledSentence(words=words, tags=[name])これらの関数を組み合わせて、記事のパスリストから、記事コンテンツに変換し、単語分割して、センテンスのジェネレーターを返す関数を定義する。
def corpus_to_sentences(corpus):
docs = [read_document(x) for x in corpus]
for idx, (doc, name) in enumerate(zip(docs, corpus)):
sys.stdout.write('\r前処理中 {}/{}'.format(idx, len(corpus)))
yield doc_to_sentence(doc, name)最後に、Doc2Vecパラメータを渡して、学習させよう。
corpus = corpus_files()
sentences = corpus_to_sentences(corpus)
model = models.Doc2Vec(sentences, dm=0, size=300, window=15, alpha=.025,
min_alpha=.025, min_count=1, sample=1e-6)
print('\n訓練開始')
for epoch in range(20):
print('Epoch: {}'.format(epoch + 1))
model.train(sentences)
model.alpha -= (0.025 - 0.0001) / 19
model.min_alpha = model.alphaここで、デフォルトで設定されているdmに1を設定するとdmpvで学習されることになる。1以外であれば、DBoWで学習される。
モデルの保存と読み込みは以下のようにして、saveメソッドとloadメソッドにファイル名を指定する。
model.save('doc2vec.model')
model = models.Doc2Vec.load('doc2vec.model')最も似ている記事を取得する
これで、モデルの学習を終えたので、実際に似ている記事を取得してみよう。
docvecsプロパティのmost_similarメソッドを使用すると、ラベル付した記事からコサイン類似度を計算して類似した記事を取得することができる。
試しに./text/livedoor-homme/livedoor-homme-5625149.txtを引数にして、近い記事を取得してみよう。ちなみにこの記事は、Twitterを初めたばかりの人向けに、使い方を解説した記事である。
>> model.docvecs.most_similar('./text/livedoor-homme/livedoor-homme-5625149.txt', topn=1)
[('./text/kaden-channel/kaden-channel-6116967.txt', 0.19515399634838104)]すると、ラベル名と類似度のタプルが返ってくる。Windows Phoneのクレームキャンペーンの記事になったが、それほど類似度は高くないようだ。
モデルを使って類似度を算出する
類似度の算出には、docvecsプロパティのsimilarityメソッドを使う。
>> model.docvecs.similarity('./text/livedoor-homme/livedoor-homme-4700669.txt', './text/movie-enter/movie-enter-5947726.txt')
0.149050674935類似度が数値で返される。
まとめ
Doc2Vecを使うと文書や文をベクトル化することが出来るので、様々な形で応用することができる。
Doc2Vecはレコメンドや文書分類、感情分析など汎用性が高いテクニックなので、是非とも使ってみて欲しい。