
AlphaGoや自動翻訳などの劇的な精度向上を目の当たりにして、これから機械学習を学びたいという方も多いと思います。しかし大学の教科書等では難解な言葉が多用され圧倒されることでしょう。
NumPyを使って実際に実装しながらどのように機械学習が動作するのかを理解していきます。
その中でも本記事では機械学習を学ぶなかで一番基礎的な、線形回帰について実装しながら学びましょう。
線形回帰とは独立変数”X”とそれに従属する従属変数”y”との関係を求めていくものです。この関係を示したものを線形回帰モデルと呼びます。
一般的な形式としてこのモデルは以下のように表されます。
Xにp個の因子が含まれており、p個のセットのi番目における従属変数の値をとしています。このの値をの関数とその係数を使った多項式
によって予想します。(簡略化のためノイズ項は省いてあります)
今回学習していくのは以下の曲線です。
この曲線を
をモデルとして学習させていきたいと思います。
今回はXが1つの値に対してyも1つの値が対応しているので、
という組み合わせになります。
損失関数の設定
まずはこの予測モデルがどれほど目標とするものと離れているのかを指標化するための損失関数を設定します。損失関数の出力値が大きければモデルと目標の差が大きいことになります。逆に、小さければモデルが目標と近いことを表します。目標値(ここでは与えられた”X”と”y”のうち”y”の方)が予測値とどの程度離れているかを見るために二乗和誤差を使ってみましょう。
これは予測値と求める値との偏差を2乗にしたものを足し合わせていったものです。
損失関数は以下のように表すことができます。
まずはこれを損失関数として設定します。
学習の進め方
では、この損失関数を用いて機械学習を進めて行く方法をまとめていきます。この損失関数の値が出来る限り小さくなるようなパラメーター を探索することができれば学習モデルが完成します。
パラメーター で偏微分したものが0となるようなところが損失関数が極小値をとるところとなります。パラメーターで偏微分をすると以下のようになります。
これらの値が0となるようにの値をそれぞれ調整していけば求める値となります。よって上の式を変形すると、以下のようになります。
これを変形すると次のようになります。
よってについての線形方程式ができあがりました。この方程式を解けば損失関数を最小化するようなパラメータの組み合わせが求められます。
このときjは0,1,2,3,4,5のいずれかの値をとります。このように行列、ベクトルを設定すると、
の関係が成り立ちます。したがって、求めるパラメーターベクトルは
とすれば求められます。
NumPyでの実装
数式を素直に実装
最初にサンプルデータを作ります。今回はノイズを若干含めたXとyの組20個を作ってみます。
In [1]: import numpy as np
In [2]: X = np.random.rand(20)*8-4 # -4~4の範囲での一様乱数
In [3]: X
Out[3]:
array([-3.42986572, -1.87588861, 3.84385152, -3.89144083, -3.36004416,
-0.13601145, 0.08145822, 2.09009556, 1.15716818, -3.4319017 ,
3.90532335, 0.54195337, 1.92151608, -3.24690618, -2.72272102,
-0.23460238, 0.01666335, -1.98198209, -1.4053297 , 2.11672423])
In [4]: y = np.sin(X) + np.random.randn(20)*0.2 # サインカーブの値にノイズを加えた
In [5]: y
Out[5]:
array([ 0.22976285, -0.96395527, -0.75819862, 0.53248622, 0.22435082,
-0.05723606, 0.08135567, 0.80438401, 1.20464605, 0.26919954,
-0.31220958, 0.62936553, 0.96179991, 0.05992766, -0.32742464,
-0.35724024, -0.16981953, -0.55381051, -1.03000768, 0.66376274])これをグラフで表すと以下のようになります。
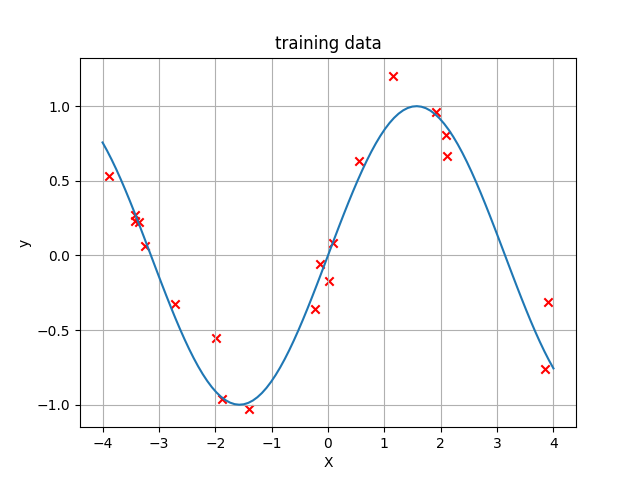
これは以下のコードで表示させることができます。
In [6]: import matplotlib.pyplot as plt
In [7]: XX = np.linspace(-4,4,100) # -4から4の間を100等分した数列を生成
In [8]: plt.xlabel('X')
pOut[8]: <matplotlib.text.Text at 0x10f8714a8>
In [9]: plt.ylabel('y')
Out[9]: <matplotlib.text.Text at 0x10f87c390>
In [10]: plt.title('training data')
Out[10]: <matplotlib.text.Text at 0x10f894cc0>
In [11]: plt.grid()
In [12]: plt.scatter(X, y, marker='x', c ='red') # markerでポイントするものの形状を指定。cで色を指定。これが散布図になる。
Out[12]: <matplotlib.collections.PathCollection at 0x10f8d4978>
In [13]: plt.plot(XX, np.sin(XX)) # サインカーブをプロットする。
Out[13]: [<matplotlib.lines.Line2D at 0x10f8dd080>]
In [14]: plt.show()トレーニングデータができたところでこれを基に行列を作っていきます。
で作ることができました。nがデータの個数に対応することに注意してこれをNumPyで再現すると、
In [41]: A = np.empty((6,6)) # 行列Aの受け皿を作る
In [42]: for i in range(6):
...: for j in range(6):
...: A[i][j] = np.sum(X**(i+j))
...:
In [43]: A
Out[43]:
array([[ 2.00000000e+01, -1.00419400e+01, 1.21634101e+02,
-1.05451173e+02, 1.33729574e+03, -9.82941108e+02],
[ -1.00419400e+01, 1.21634101e+02, -1.05451173e+02,
1.33729574e+03, -9.82941108e+02, 1.68638158e+04],
[ 1.21634101e+02, -1.05451173e+02, 1.33729574e+03,
-9.82941108e+02, 1.68638158e+04, -7.94900136e+03],
[ -1.05451173e+02, 1.33729574e+03, -9.82941108e+02,
1.68638158e+04, -7.94900136e+03, 2.25730144e+05],
[ 1.33729574e+03, -9.82941108e+02, 1.68638158e+04,
-7.94900136e+03, 2.25730144e+05, -4.36017240e+04],
[ -9.82941108e+02, 1.68638158e+04, -7.94900136e+03,
2.25730144e+05, -4.36017240e+04, 3.11930204e+06]])ベクトルbは
で求められたので、
In [44]: b = np.empty(6)
In [45]: for i in range(6):
...: b[i] = np.sum(X**i*y)
...:
In [46]: b
Out[46]:
array([ 1.13113887e+00, 3.14356290e+00, 2.92533385e+00,
-8.11722863e+01, -1.01290279e+01, -1.56797929e+03])これらより、求めるパラメーターベクトルは、
In [47]: omega = np.dot(np.linalg.inv(A), b.reshape(-1,1)) # linalg.inv()で逆行列を求める。dot関数で内積を求めてくれる。
In [48]: omega.shape
Out[48]: (6, 1)ここでnp.linalg.inv()関数は行列の逆行列を求めてくれる関数で、np.dot()は内積を求めてくれる関数です。以上で今回作成したモデルのパラメーターをすべて求めることができました。では実際にプロットして確かめてみましょう。
In [54]: f = np.poly1d(omega.flatten()[::-1]) # ωを係数とした多項式を作る
In [55]: XX = np.linspace(-4,4,100)
In [56]: plt.xlabel('X')
Out[56]: <matplotlib.text.Text at 0x10bcd3208>
In [57]: plt.ylabel('y')
Out[57]: <matplotlib.text.Text at 0x10bcd5b70>
In [58]: plt.title('trained data')
Out[58]: <matplotlib.text.Text at 0x10bcf2a90>
In [59]: plt.grid()
In [60]: plt.plot(XX, f(XX), color='green')
Out[60]: [<matplotlib.lines.Line2D at 0x10bd214e0>]
In [61]: plt.plot(XX, np.sin(XX), color='blue')
Out[61]: [<matplotlib.lines.Line2D at 0x10bcd50b8>]
In [62]: plt.show()これによる出力結果が以下のグラフとなります。
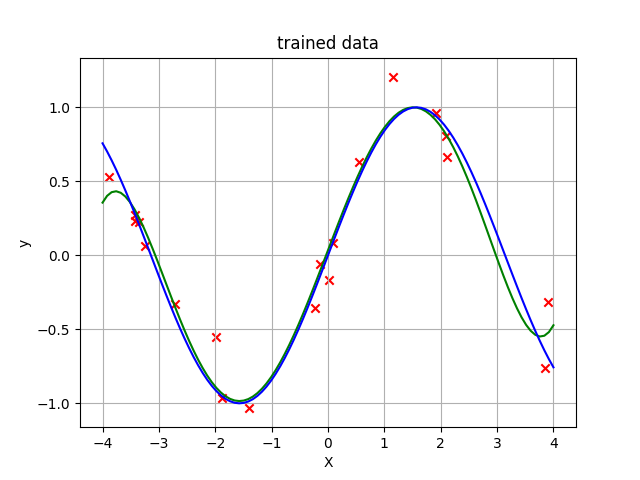
紫色の線がもともとのサインカーブで、緑色の線が今回求めたモデルから計算されたサインカーブです。赤色のバツじるしは今回使ったトレーニングデータとなっています。これを見てみるとかなりうまくフィットしていることがわかります。
多項式フィッティングを関数で
実は前の項まで説明やコードの初回をしてきましたがこれらの操作を簡単にやってくれる関数がNumPyにはあります。
最後にこの関数の紹介をして終わりにしましょう。
このフィッティングをしてくれる関数はnp.polyfit()関数となります。
In [72]: omega_2 = np.polyfit(X, y, 5)
In [73]: omega_2
Out[73]:
array([ 5.89345621e-03, 3.95891406e-04, -1.63132943e-01,
-1.21168968e-02, 9.97830851e-01, 3.43030250e-02])
In [24]: f_2 = np.poly1d(omega_2)これを同様にグラフにプロットしてみると、以下のようになります。
水色のカーブがnp.polyfit()関数によって得られた曲線です。
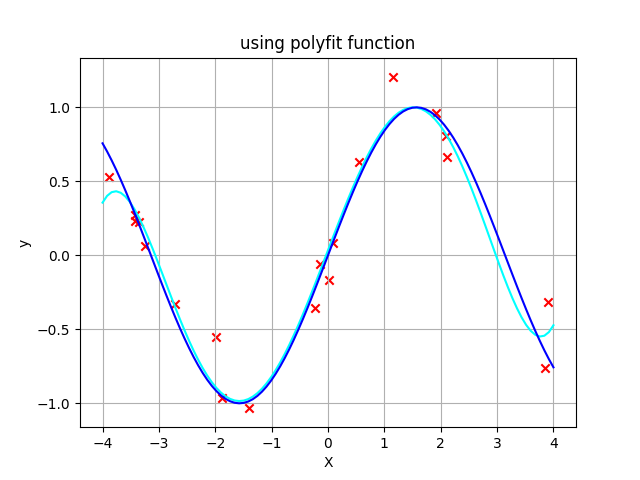
まとめ
今回は簡単な線形回帰をNumPyで実践してみました。計算式をもとにNumPyで素直にそれを再現したあと、それを自動的に行なってくれる関数を紹介しました。
使ったデータの量がある程度確保されていたため、データ数が少なくてトレーニングデータに異常にマッチしてしまう過学習は起きませんでしたが、実際使う場面では過学習が起きないように罰則項を損失関数に付け加えることがあります。
今回はNumPyを使って機械学習をしてみるという目的だったため複雑にならないようにしましたが実際利用する現場では無視できないものとなっています。
気になる方はぜひ調べてみてください。