
PandasのMultiIndexは特異的で見慣れない人も多く、初めてPandasを触る人にとってはかなり戸惑う部分の1つだと思います。
MultiIndexを使いこなせるようになることで、より高度なデータ分析をすることが可能となり、分析対象のデータを柔軟に整形することができるようになります。
本記事ではMultiIndexを使いこなせるようにするために、概要と使い方を解説します。
MultiIndexとは
公式ドキュメントでは階層的インデックス(Hierarchical indexing)という表現のされかたをしており、恐らくこちらの表現の方がわかりやすく、Indexオブジェクトを階層的にしたものとなります。なので、ただ単にIndexオブジェクトが重なっているというよりは、その重なっている順番にも意味があります。
MultiIndexという名前がついているように、1つの列(もしくは行)に対して1つではなく複数のラベルがつけらているようなIndexオブジェクトとなっています。
- 1つの列(行)に対して複数のラベル
- 階層構造になっており重なっている順番にも意味がある
の2点がMultiIndexの重要な点になります。
また、複数のラベルを用いることによってデータを特定しやすくするというメリットもあります。
例えば、以下のようなデータがあったとします。筆者がでたらめに作ったニュースの一覧です。左からジャンル、年、月、日、タイトルとなっています。
genre,year,month,day,title
music,2017,2,12,The singer sold 1 million CDs.
sports,2017,3,12,Team A won the first game of the season.
sports,2017,4,14,The athlete will retire by next month.
sports,2016,12,13,Team B lose for the first time in the season.
politics,2016,8,21,C on Trump tweet calling D a 'dog'.
politics,2017,5,29,E won the election.
health,2016,5,30,Running effectives.
health,2017,2,21,Best foods for health.
ではこれらのニュースを特定するためにはどのキーを使えばよいでしょうか。どれか1つのキーを使って特定のニュースを指定するのはできません。こういう時、複数のキーを組み合わせることでデータの指定をしやすくすることができます。
試しにこのデータからMultiIndexを作成してみます。
上のデータをsample_news.csvの名前で保存してください。以下のリンクからもダウンロード可能です。
In [1]: import pandas as pd
In [2]: df = pd.read_csv("sample_news.csv", index_col=[0,1,2,3]) # インデックスラベルとして0,1,2,3列目のデータを使う
上記を表示させると以下のようになります。
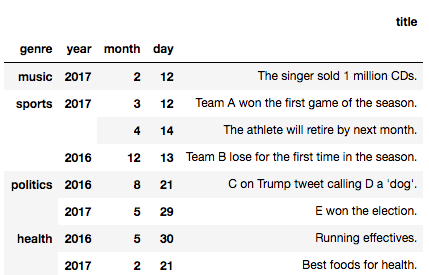
このデータの場合、ラベルがgenre, year, month, dayの4つとなっており、
genre > year > month > dayの順にグループ分けがされています。
グループ分け自体はsort_index関数を使えばその優先度を変えることができるのですが、このように階層状にラベル付けがされています。
これがMultiIndexの1つの例となります。
MultiIndexでの階層
MultiIndexを扱う関数でよく使われるものがlevel引数となります。
このlevel引数はMultiIndexの中でどの階層のものかを指定する用途でよく使われます。
このlevel引数の指定の仕方として 階層名(namesで定義されている) を指定する方法と 階層の数 を指定する方法とがあります。
階層名を指定する
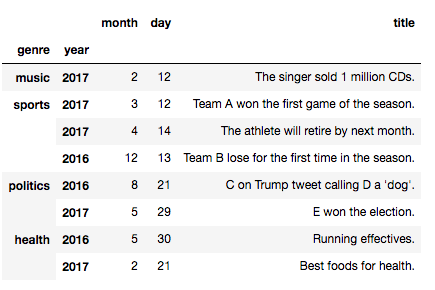
階層名を指定する方法は以下のデータを使うと、"genre"と"year"となります。
In [1]: df = pd.read_csv("sample_news.csv", index_col=[0,1])
階層の数を指定する
階層の数を指定する方法ですが、これは階層が外側にある階層ほど番号が若く、
最も内側が-1 であり、 最も外側が0 となっています。
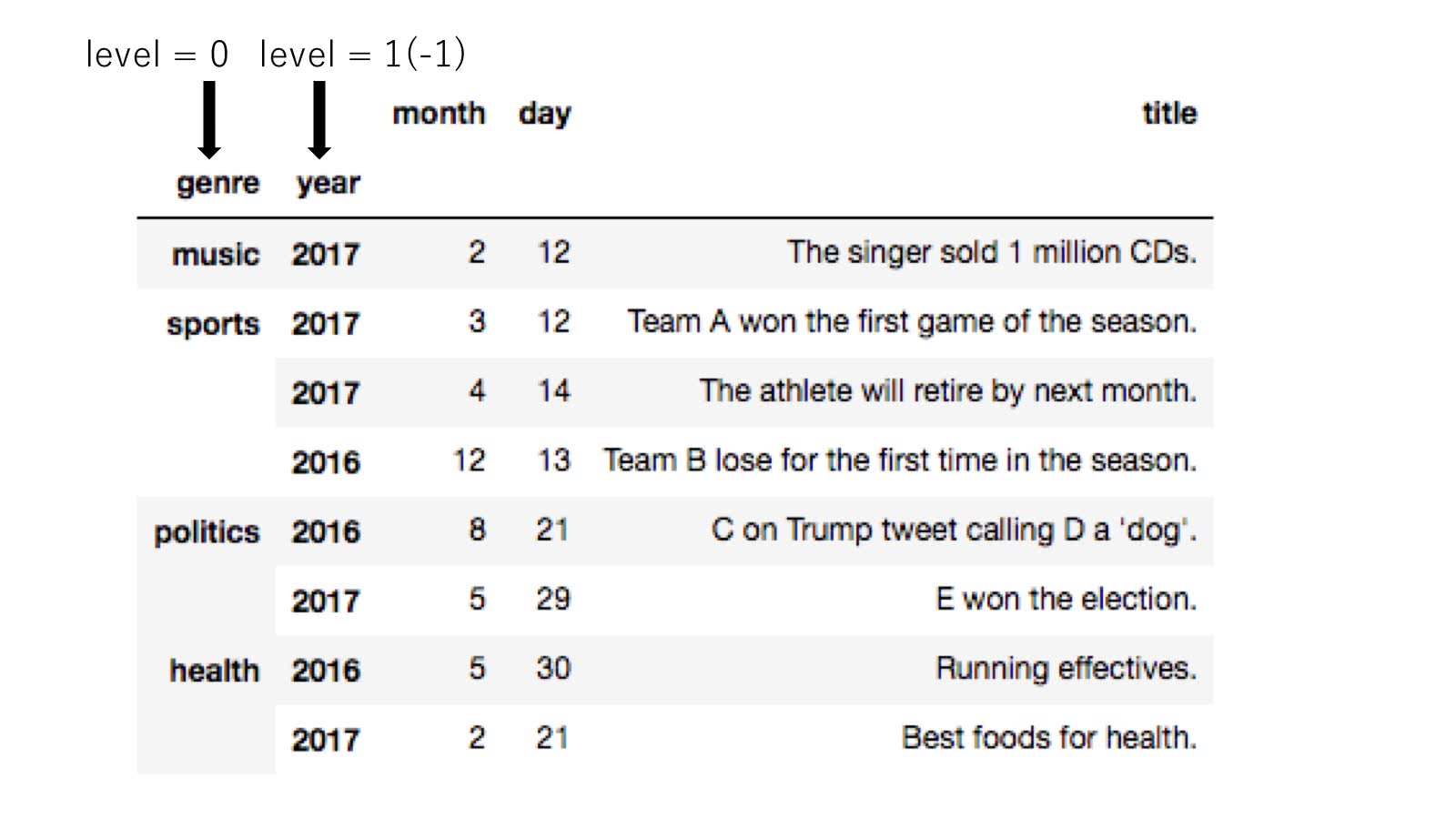
これはカラムラベルになると上側(外側)の方が番号が若く、 下側へいくにつれて番号が大きくなります。
最も下側が-1 であり、 最も上側が0 となります。
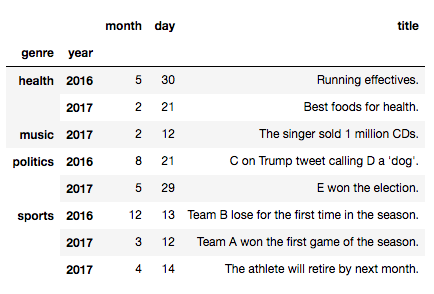
sort_index関数を例にとってlevel引数を扱ってみます。
In [59]: news_list = news_list.sort_index(level=0) # 最も外側 level="genre"
次は1つ内側の層(year)をソートしてみます。
In [62]: news_list = news_list.sort_index(level=1) # level=-1でも可
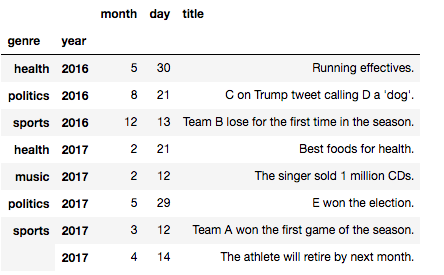
今度はyearを元に並べ替えが行われたことがわかります。
このように、階層は数値でも指定することが可能です。
ただ、可能ならば階層ごとに名称をつけて階層名で指定した方がコードの見通しもよくなりますのでlevel引数を使う時はできるだけ階層名を使用することをオススメします。
MultiIndexの使い方
MultiIndexの概要がわかったところで実際に使い方を学んでいきます。
MultiIndexを作成する
MultiIndexを複数のラベルを繋げたタプルをリストにしたものと捉えると、以下のようにタプルからMultiIndexを作成することができます。
In [1]: import pandas as pd
In [2]: arrays = [['foo','foo','bar','bar','baz','baz'],
...: ['A','B','A','B','A','B']]
...:
In [3]: tuples = list(zip(*arrays))
In [4]: tuples
Out[4]:
[('foo', 'A'),
('foo', 'B'),
('bar', 'A'),
('bar', 'B'),
('baz', 'A'),
('baz', 'B')]
In [5]: index = pd.MultiIndex.from_tuples(tuples, names=['grade','class']) # タプルからMultiIndexを作成。階層の名前を'names'で設定できる。
In [6]: index
Out[6]:
MultiIndex(levels=[['bar', 'baz', 'foo'], ['A', 'B']],
labels=[[2, 2, 0, 0, 1, 1], [0, 1, 0, 1, 0, 1]],
names=['grade', 'class'])
In [8]: import numpy as np
In [9]: series = pd.Series(np.random.randn(6), index=index) # MultiIndexを使ってSeriesを作成する
In [10]: series
Out[10]:
grade class
foo A 0.621237
B 0.018139
bar A -0.550840
B -1.371854
baz A 0.390944
B -0.063280
dtype: float64
組み合わせの全てを作りたい時は以下のようなfrom_product関数を使うことで作ることができます。
In [12]: pd.MultiIndex.from_product(iterables, names=['grade','class'])
Out[12]:
MultiIndex(levels=[['bar', 'baz', 'foo'], ['A', 'B']],
labels=[[2, 2, 0, 0, 1, 1], [0, 1, 0, 1, 0, 1]],
names=['grade', 'class'])
配列から直接作ることも可能です。
pd.MultiIndex.from_arrays()関数を使うことも可能です。
In [13]: arrays
Out[13]: [['foo', 'foo', 'bar', 'bar', 'baz', 'baz'], ['A', 'B', 'A', 'B', 'A', 'B']]
In [14]: series2 = pd.Series(np.random.randn(6), index=arrays) # indexに直接指定する。
In [15]: series2
Out[15]:
foo A -0.115075
B 0.804486
bar A -0.309939
B 0.627646
baz A 0.390036
B 1.880562
dtype: float64
それぞれの階層の名称をつけるにはrename関数を使うことができます。
In [17]: series2.index = series2.index.rename(["grade","class"]) # インデックスの階層ごとに名称をつける
In [18]: series2
Out[18]:
grade class
foo A -0.115075
B 0.804486
bar A -0.309939
B 0.627646
baz A 0.390036
B 1.880562
dtype: float64
In [22]: series2.index.names = ["grade2","class2"] # 直接指定することも可能
In [23]: series2
Out[23]:
grade2 class2
foo A -0.115075
B 0.804486
bar A -0.309939
B 0.627646
baz A 0.390036
B 1.880562
dtype: float64
次は列データから直接作ってみます。この方法が一番一般的でしょう。 先ほどのニュースのデータを使います。
デモのため、インデックスとして読み込む列を指定せずに読み込みます。
In [24]: news_list = pd.read_csv("sample_news.csv")
中身は以下のようになっています。
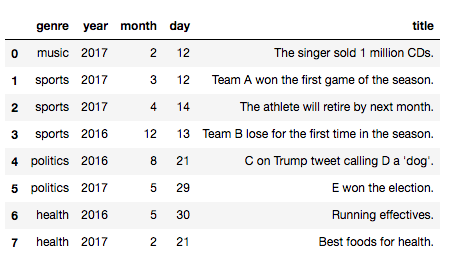
このデータから複数の列データを指定してMultiIndexを作成します。
set_index関数を使います。
"genre","year"の列データをインデックスラベルに移動させます。
指定する順番で階層が変わってくるので注意してください。
In [30]: news_list = news_list.set_index(["genre", "year"])
これの中身は以下のようになります。
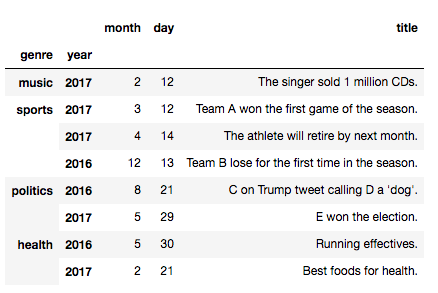
set_index関数の詳しい使い方はこちら。
PandasでIndexオブジェクトを設定するset_index関数の使い方 /features/pandas-setindex.html
転置させればカラムラベルをMultiIndexにすることもできます。
In [35]: news_list = news_list.T
中身は以下のようになります。
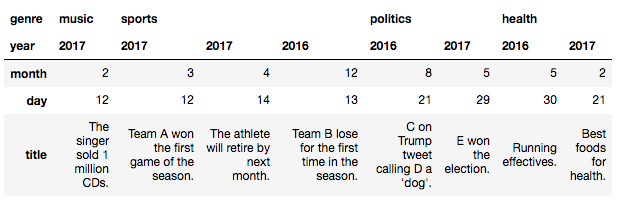
MultiIndexのあるDataFrameの要素指定
直前のデータをそのまま使います。列データを抜き出す時はDataFrame[列名]で指定できます。sportsジャンルのデータを抜き出してみます。
In [41]: news_list["sports"] # sportsジャンルのものを抜き出す
Out[41]:
year 2017 ... 2016
month 3 ... 12
day 12 ... 13
title Team A won the first game of the season. ... Team B lose for the first time in the season.
[3 rows x 3 columns]
見にくかったのでまた表に直します。
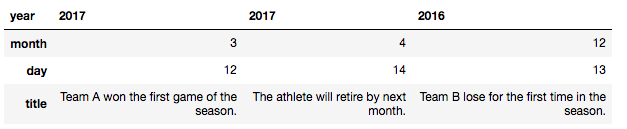
sportsジャンルの3つのニュースを取り出すことができました。次はyearも一緒に指定します。sportsジャンルで2016年のものを取り出します。
In [44]: news_list["sports", 2016]
Out[44]:
genre sports
year 2016
month 12
day 13
title Team B lose for the first time in the season.
In [45]: news_list["sports"][2016]
Out[45]:
month 12
day 13
title Team B lose for the first time in the season.
Name: 2016, dtype: object
行の指定などはlocを使います。
MultiIndexでのlocを使った要素指定
locを使って要素指定するにはタプルを使って要素指定することが可能です。locやilocの基本的な使い方以下の記事にまとめています。
Pandasで要素を抽出する方法(loc、iloc、iat、atの使い方) /features/pandas-location.html
以下のデータを使います。
In [46]: news_list = news_list.T # 元に戻す
ではタプルを使って指定します。ジャンルが"sports"で年が2016のものの"title"を抜き出します。
In [48]: news_list.loc[("sports", 2016), 'title']
genre year
sports 2016 Team B lose for the first time in the season.
Name: title, dtype: object
タプルを使わずに一番外側のラベルを指定することも可能です。
In [50]: news_list.loc["music", "title"]
Out[50]:
year
2017 The singer sold 1 million CDs.
Name: title, dtype: object
In [51]: news_list.loc["politics", "title"]
Out[51]:
year
2016 C on Trump tweet calling D a 'dog'.
2017 E won the election.
Name: title, dtype: object
xs関数を使った途中の階層までの指定
xs関数を使えば特定の階層における値を指定することが可能です。level引数で階層を指定します。
In [52]: news_list.xs('music',level="genre") # genre階層の"music"ラベルを探す
...:
Out[52]:
month ... title
year ...
2017 2 ... The singer sold 1 million CDs.
[1 rows x 3 columns]
In [53]: news_list.xs(2016,level="year")["title"] # 2016年の記事のタイトル部分だけ抜き出す
Out[53]:
genre
sports Team B lose for the first time in the season.
politics C on Trump tweet calling D a 'dog'.
health Running effectives.
Name: title, dtype: object
まとめ
今回はMultiIndexの概要とその使い方について解説しました。 使い道は色々ありますが、データを整形するための便利なツールとして使えるようにしてください。