TensorFlowの優れた機能として、TensorBoardによる充実した可視化環境が挙げられます。TensorBoardがあれば、ニューラルネットワークの学習が上手くいかないときに、俯瞰してネットワークを表示したり、様々なデータのログを簡単に可視化して問題を発見することができます。
つまり、TensorBoardを使いこなすことは、ディープラーニングのモデルを開発をする上で、重要な役割を果たすのです。
本記事では、そんなTensorBoardを使いこなすために必要な知識を余すこと無く解説していきます。
TensorBoardの主要機能
TensorBoardは、TensorFlowをインストールすると一緒に付属する可視化ツールです。TensorFlowのインストール方法は以下の記事を参考にしてください。
機械学習初心者でもすぐに出来るTensorFlowのインストール方法 /tensorflow/2017/01/17/how-to-install-tensorflow.html
TensorBoardは、TensorFlowの可視化を補完するツールで以下のデータの可視化をサポートしています。
- スカラー値の折れ線グラフ
- 画像の可視化
- 音声の再生
- ヒストグラム
- 計算グラフの描画
- 次元削減のプロット
折れ線グラフ
折れ線グラフは、モデルのaccuracyやloss、学習速度などのスカラー値を可視化するためによく使われます。以下の画像は、MNIST文字認識のモデルの学習時にlossをログに残した例です。
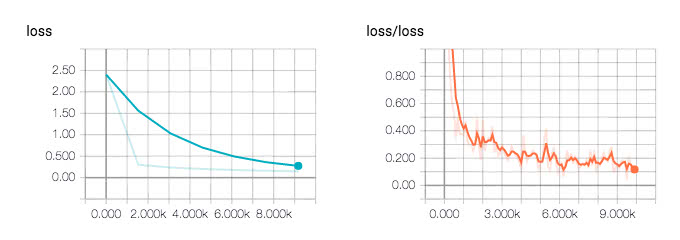
左側がテストデータセットのlossで、右側が訓練データセットのlossです。最初大きかったlossが徐々に小さくなっているので、正しく学習されていることが分かります。
画像
スカラー値と同様に、画像も可視化することができます。以下の画像は、MNISTの訓練データを可視化した例です。
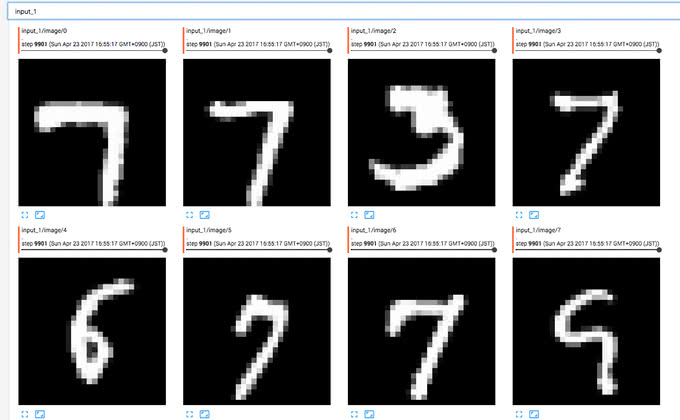
画像の可視化は、Data Augmentationなどで前処理で正しく画像処理がなされているかを検証するために利用すると便利です。
音声
TensorBoardは、音声の再生もサポートしています。画像の時と同様に、前処理で音声を処理した後に、正しく処理されたかどうかを確かめることができます。
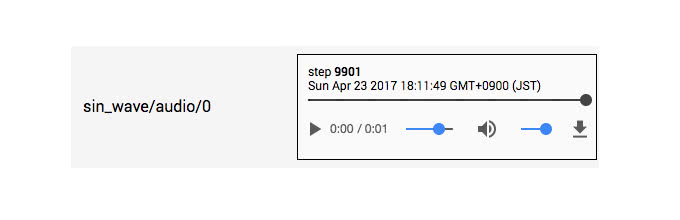
音量の調節やダウンロードもサポートされています。
ヒストグラム
ヒストグラムの可視化にも対応しています。ニューラルネットワークの各層での重みやバイアスが初期値からどのように変化したのかを可視化すると便利です。可視化することで、各層で勾配消失していないかどうかを確認することができます。
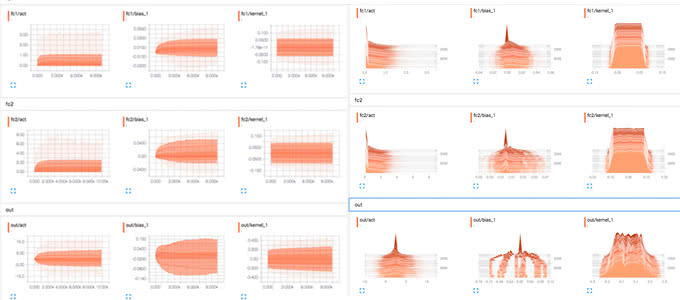
計算グラフ
計算グラフの可視化もできます。モデルが設計通り正しく実装されているか、ひと目で確認することができます。
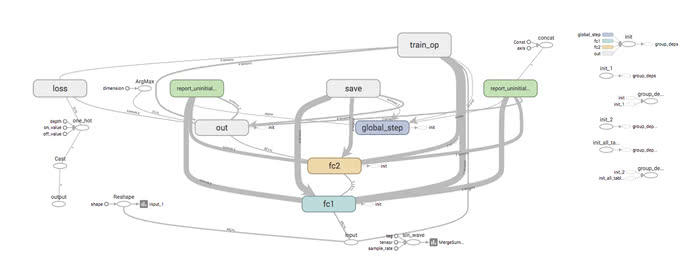
次元削減のプロット
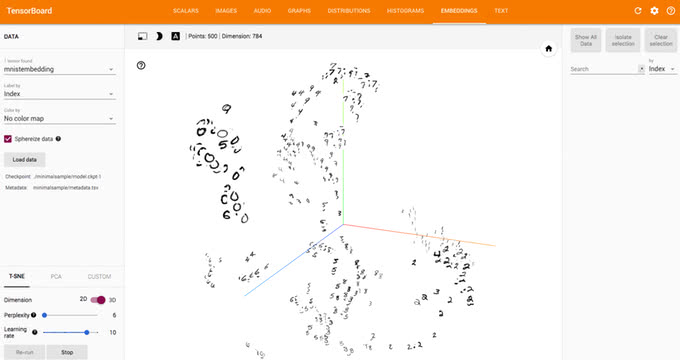
次元削減のプロットは、TensorFlowの0.12から導入された機能です。単語の分散表現などを可視化してみたいときに便利です。
以下の図は、TensorBoardでMNISTの画像をt-SNEで可視化した例です。
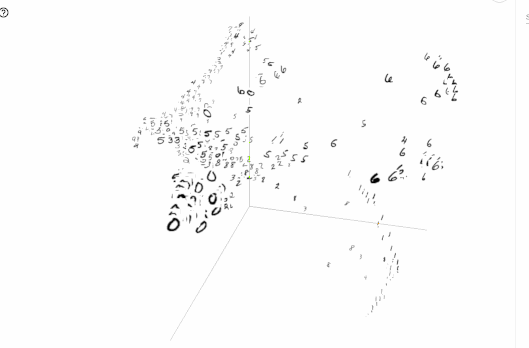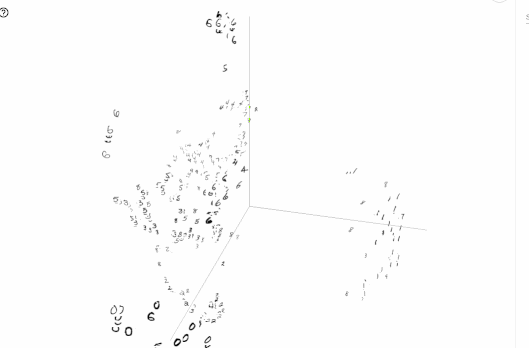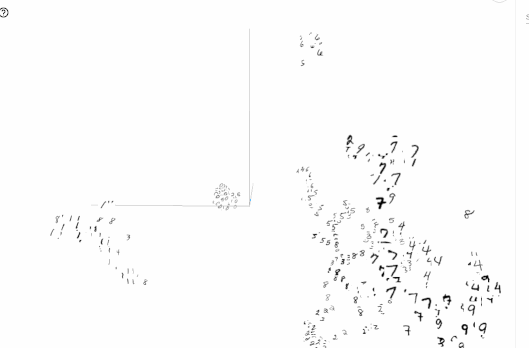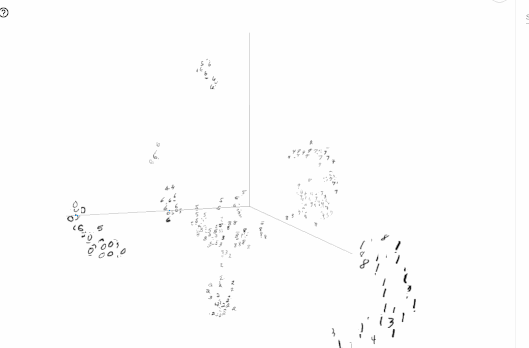
TensorBoardの読み方
TensorBoardのグラフは、意味を理解していないと、謎の記号が描画されているようにしか見えません。一つ一つ記号の意味を理解していくことで、価値を発揮します。
シンボルの意味
まずは、シンボルの意味を紹介します。以下の表は、シンボルと対応する意味まとめたものです。
| シンボル | 意味 |
|---|---|
 |
name scopeでまとめたノードです。ダブルクリックするとさらに中身が見れます。 |
 |
各ノードが接続されていない一連のノード列 |
 |
1つの独立したノード |
 |
定数値のノード |
 |
summaryノード |
 |
オペレーション間のデータフロー |
 |
オペレーション間の制御フロー |
 |
入力テンソルを変更することができるノードへの参照 |
参考:TensorBoard: Graph Visualization
name scopeとnode
TensorFlowのグラフは、name scopeでまとめることができます。計算グラフのノードは複雑なノードになればなるほど爆発的に増えてしまうので、name scopeで高レベルのオペレーションにまとめるテクニックは、モデルを開発・デバッグする上でも大切になってきます。
以下の画像のように、name scopeでまとめておくと、上位の名前空間だけで管理することができ、簡単に把握することができるようになります。
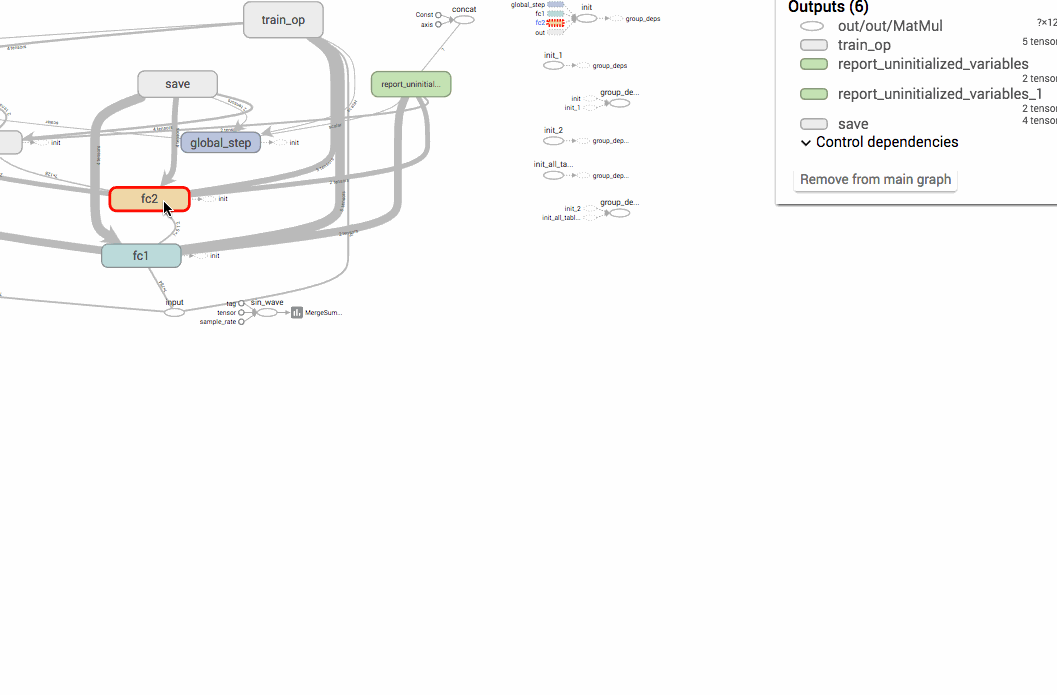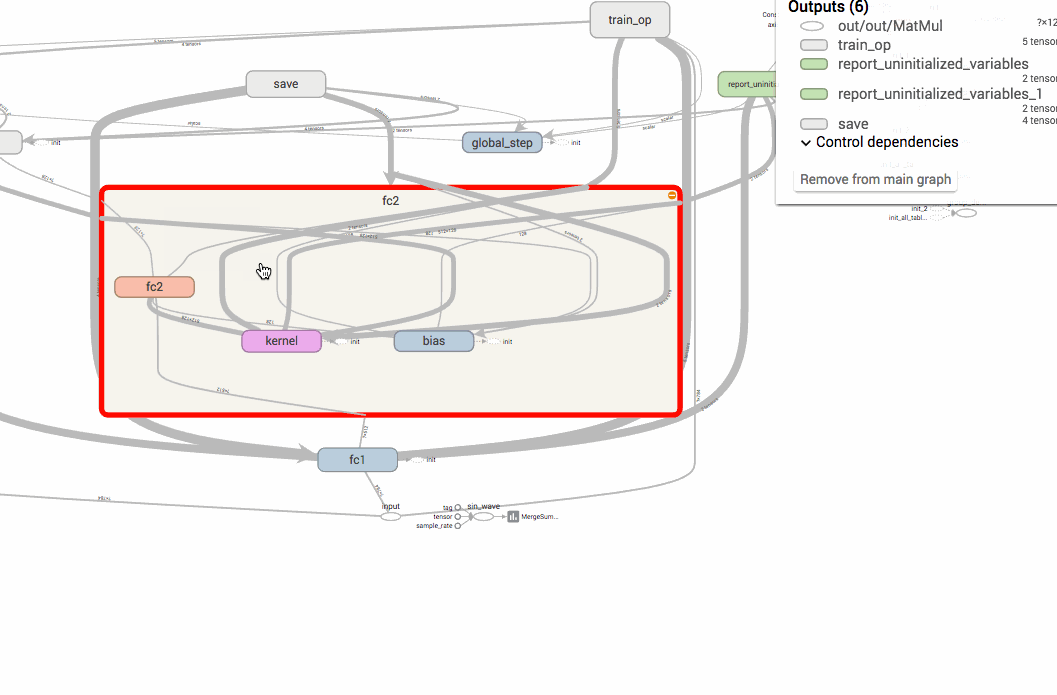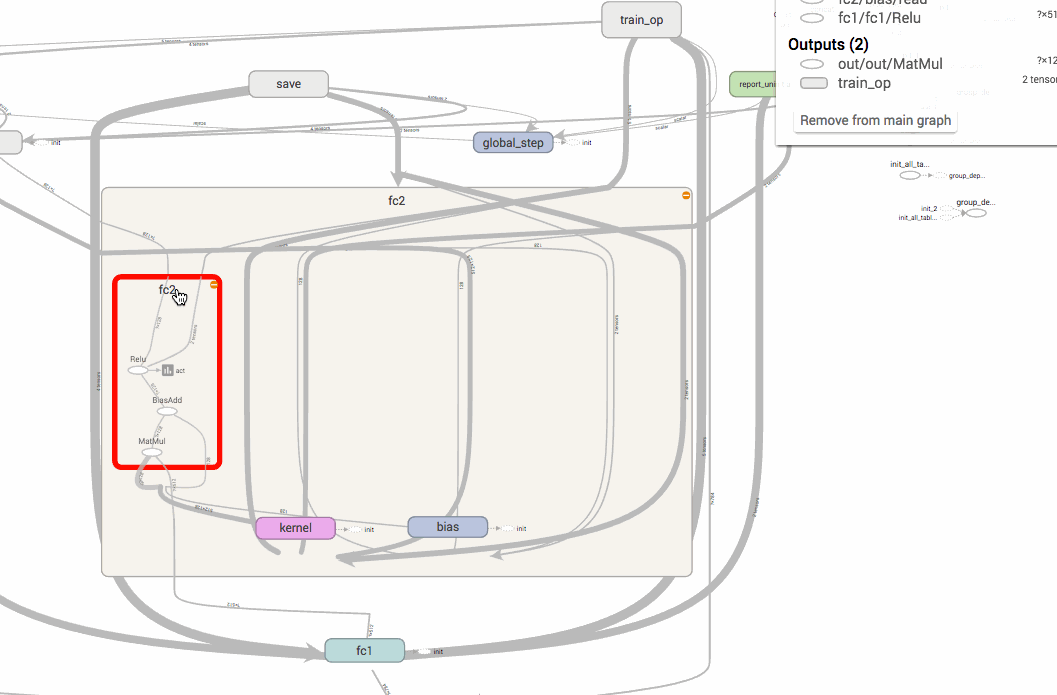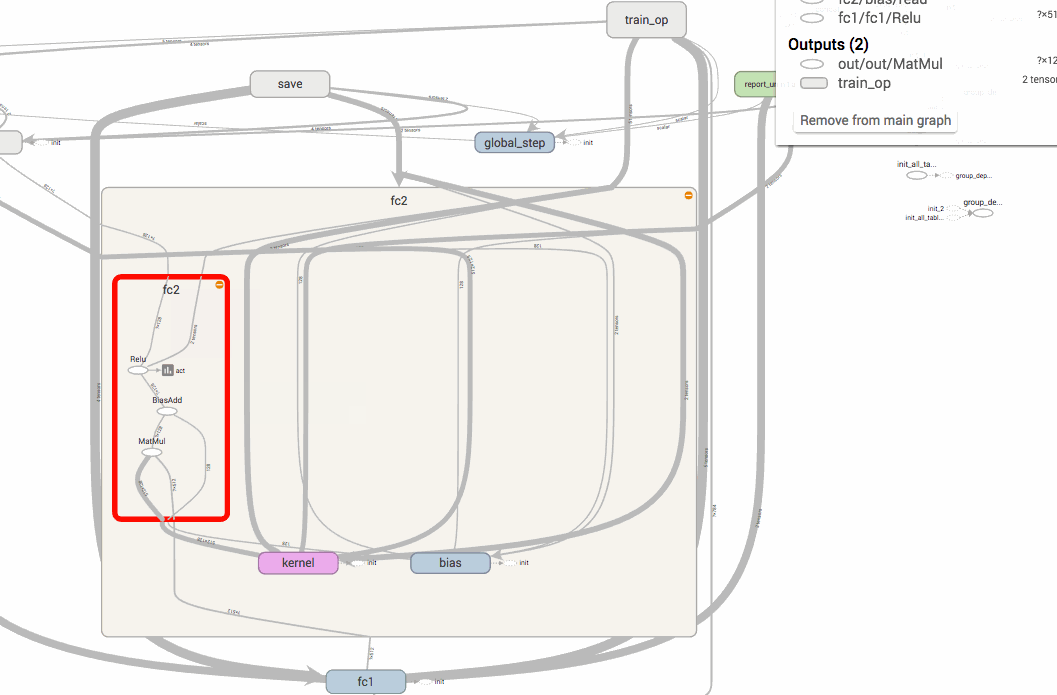
オペレーションの名前は、name scope/op nameのようにスラッシュで区切られるようになります。例えば、以下のコードはTensorFlowのtf.name_scopeを使った名前空間の構築ですが、最終的に出力されるlossの名前はloss/lossとなります。
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
tf.summary.scalar('loss', loss)グラフの色
TensorBoardでは、計算グラフの色を、目的に応じて変更することができます。
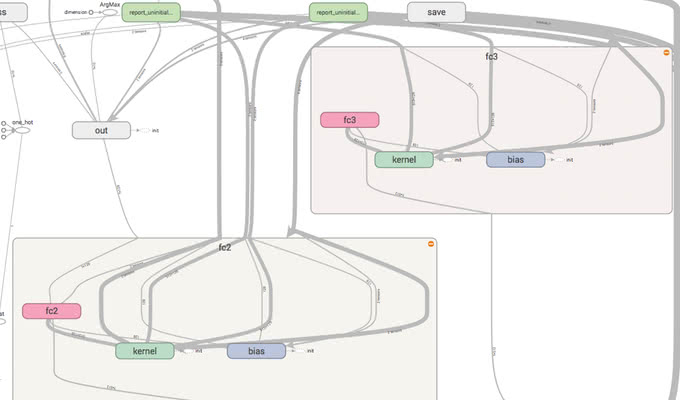
Structure View
Structure Viewは、同じ要素で構成されている名前空間を同じ色で表示する形式です。以下の画像では、2つの全結合層の中身がfcとkernelとbiasで同じ構成の名前空間であることがひと目で分かります。
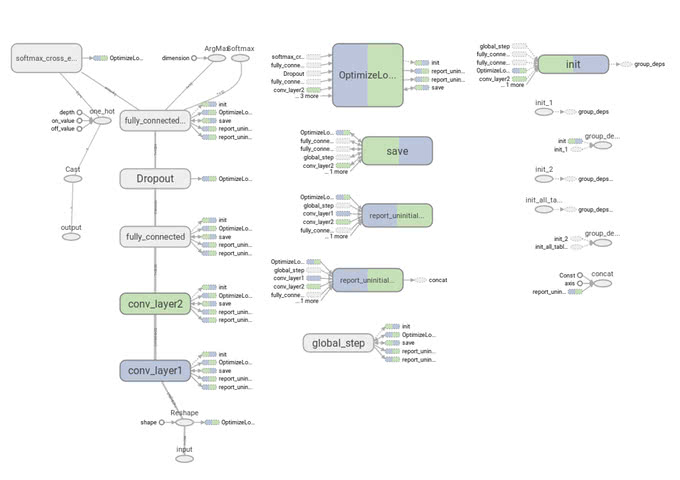
Device View
Device Viewは、GPUやCPUなどの各デバイスがどのような比率で実行されているかを色で表します。以下の画像では、GPUを緑、CPUを青で表示されていることが分かります。
計算時間・メモリ
計算時間やメモリの使用率を表示することもできます。使用率の高いところは、色濃く赤色になります。左側がメモリの使用率の可視化で、右側が計算時間の可視化になります。以下の画像の例では、cross_entropyはメモリの使用率は少ないものの、計算時間が掛かっていることがひと目で把握することができます。
TensorBoardでは、以下のようにtf.FileWriterに対してtf.RunMetadataを追加することで使用率を見ることができるようになります。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict={x: ..., y: ...},
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)テンソルの次元数
計算グラフのノード間のエッジには、テンソルの次元情報が描画されています。以下の図は、Convolutional Neural NetworkのConvolution層とPooling層の間のパスを拡大表示したものですが、正しくコードが実装されているかどうかを確認することが容易にできます。
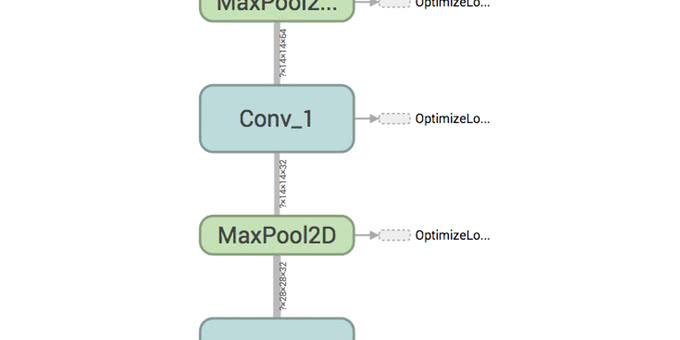
Convolutional Neural Networkについては以下の記事を参考にしてください。
定番のConvolutional Neural Networkをゼロから理解する /deep_learning/2016/11/07/convolutional_neural_network.html
Summary Operation
TensorBoardに可視化するためには、tf.summaryモジュールの関数を使います。
scalar
スカラー値の可視化には、tf.summary.scalarを使います。
tf.summary.scalar('loss', loss)のように、第一引数に名前をつけて、第二引数にスカラー値を記述します。
histogram
ヒストグラムの可視化は、tf.summary.histogram関数を使います。こちらもscalar同様に、第一引数に名前を、第二引数にヒストグラムを表示させたいテンソルを指定します。
tf.summary.histogram('bias', bias)image
TensorBoardに画像を表示するには、tf.summary.image関数を使用してください。
tf.summary.image('preprocess', tf.reshape(images, [-1, 28, 28, 1]), 10)第一引数はこれまでと同様に名前を付けます。第二引数にテンソルを指定しますが、4次元であることに注意してください。4次元の中身は[バッチサイズ, 高さ, 幅, チャネル数]となります。第三引数は画像を表示する最大の数です。指定しない場合は3になります。
チャネル数に応じて、画像のデコードをします。チャネル数に応じて以下のように自動で解釈します。
- 1: グレースケール画像
- 3: RGBのカラー画像
- 4: RGBAのアルファチャネル付き画像
また、数値は自動で0~255に正規化されます。
audio
音声をTensorBoardに表示する場合は、tf.summary.audioを使います。これまでと同様に第一引数には名前を付けて、第二引数に3次元のテンソルの音声を指定します。テンソルは[バッチサイズ, フレームサイズ, チャネル数]または、[バッチサイズ, フレームサイズ]となります。
tf.summary.audio('audio', audio, sampling_frequency)こちらも第4引数に最大の音声ファイルの生成数を指定することができます。
可視化してみる
実際に簡単な例で可視化してみましょう。MNIST文字認識をCNNで実装します。
まずは必要なモジュールをimportします。
import tensorflow as tf
from tensorflow.contrib import slim
from tensorflow.examples.tutorials.mnist import input_data次に、MNISTの入力画像と、ラベルのプレースホルダを定義してCNNのモデルを実装していきます。slimを使ってコンパクトに記述しています。
with tf.Graph().as_default() as graph:
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
x_train = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', x_train, 10)
with slim.arg_scope([slim.conv2d, slim.fully_connected],
normalizer_fn=slim.batch_norm,
activation_fn=tf.nn.relu):
with slim.arg_scope([slim.max_pool2d], padding='SAME'):
conv1 = slim.conv2d(x_train, 32, [5, 5], name='conv1')
conv_vars = tf.get_collection(tf.GraphKeys.MODEL_VARIABLES, 'Conv')
tf.summary.histogram('conv_weights', conv_vars[0])
pool1 = slim.max_pool2d(conv1, [2, 2])
conv2 = slim.conv2d(pool1, 64, [5, 5])
pool2 = slim.max_pool2d(conv2, [2, 2])
flatten = slim.flatten(pool2)
fc = slim.fully_connected(flatten, 1024)
logits = slim.fully_connected(fc, 10, activation_fn=None)
softmax = tf.nn.softmax(logits, name='output')
with tf.name_scope('loss'):
loss = slim.losses.softmax_cross_entropy(logits, y)
tf.summary.scalar('loss', loss)
train_op = slim.optimize_loss(loss, slim.get_or_create_global_step(),
learning_rate=0.01,
optimizer='Adam')
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
summary = tf.summary.merge_all()入力画像をinputという名前を付けてtf.summary.imageを使ってTensorBoardで表示させます。MNISTのデータセットは28 × 28のグレースケール画像なので、テンソルのshapeは[-1, 28, 28, 1]となっています。
slim内部で定義された変数も、tf.get_collectionやslim.all_variables等で取得することができます。今回は、Convolution層の重みをヒストグラムに表示してみます。
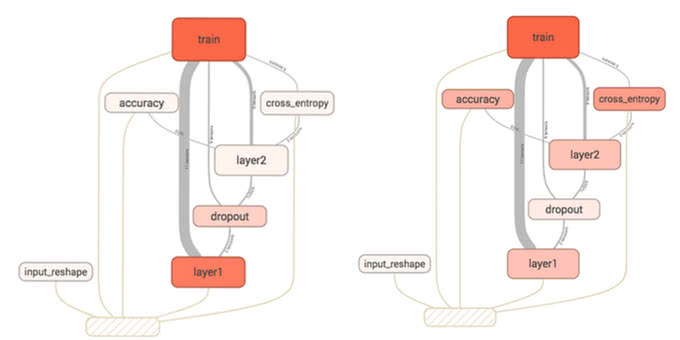
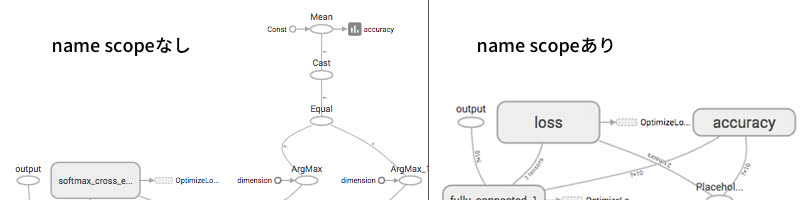
lossとaccuracyをtf.summary.scalarで可視化します。scalar関数でログを残す前に、名前空間を作っているところに注目してください。名前空間がないと、以下の画像のように計算グラフが醜くなってしまいます。
学習させるコードを書いていきます。グラフ定義の最後でサマリをmergeしたものを、Sessionで評価し、FileWriterに追加することで、TensorBoardに書き出されるようになります。
with tf.Session() as sess:
writer = tf.summary.FileWriter('cnn', sess.graph)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for i in range(500):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y:batch[1]})
print("step %d, training accuracy %g"%(i, train_accuracy))
_, w_summary = sess.run([train_op, summary], feed_dict={x:batch[0], y:batch[1]})
writer.add_summary(w_summary, i)最後に、TensorBoardを起動します。TensorBoardはtensorboardコマンドでログに残したディレクトリを指定することで可視化することができます。以下のコマンドを実行してください。
$ tensorboard --logdir=./cnnブラウザからlocalhost:6006にアクセスすると、TensorBoardのインターフェースが表示されるはずです。
まとめると、TensorBoardには以下の手順を踏めば可視化されます。
(1) Graphを定義してモデルを作成する
(2) tf.summaryモジュールの関数でログを記録する
(3) Graph定義の最後にサマリをmergeする
(4) tf.FileWriterを定義する
(5) Sessionで(3)でマージしたサマリを評価する
(6) FileWriterにサマリを追加する
ハイパーパラメータの探索
ハイパーパラメータをチューニングするには、FileWriterのディレクトリを小ディレクトリに分割すると便利になります。
例えば、どの学習係数が最適かをあなたが探索していたとしましょう。その場合、複数の学習係数を用意して、サブディレクトリにFileWriterのログを書き出すことで、同じプロット上に表示させることができるようになります。
今回は、学習係数を0.1と0.001、0.0001の3つのパターンでどれが良いか試してみることにします。先程のコードを以下のように修正します。
import os
import tensorflow as tf
from tensorflow.contrib import slim
from tensorflow.examples.tutorials.mnist import input_data
def cnn_model(learning_rate):
with tf.Graph().as_default() as graph:
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
x_train = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', x_train, 10)
with slim.arg_scope([slim.conv2d, slim.fully_connected],
normalizer_fn=slim.batch_norm,
activation_fn=tf.nn.relu):
with slim.arg_scope([slim.max_pool2d], padding='SAME'):
conv1 = slim.conv2d(x_train, 32, [5, 5])
conv_vars = tf.get_collection(tf.GraphKeys.MODEL_VARIABLES, 'Conv')
tf.summary.histogram('conv_weights', conv_vars[0])
pool1 = slim.max_pool2d(conv1, [2, 2])
conv2 = slim.conv2d(pool1, 64, [5, 5])
pool2 = slim.max_pool2d(conv2, [2, 2])
flatten = slim.flatten(pool2)
fc = slim.fully_connected(flatten, 1024)
logits = slim.fully_connected(fc, 10, activation_fn=None)
softmax = tf.nn.softmax(logits, name='output')
with tf.name_scope('loss'):
loss = slim.losses.softmax_cross_entropy(logits, y)
tf.summary.scalar('loss', loss)
train_op = slim.optimize_loss(loss, slim.get_or_create_global_step(),
learning_rate=learning_rate,
optimizer='Adam')
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
summary = tf.summary.merge_all()
return {'x': x, 'y': y, 'accuracy': accuracy, 'summary': summary, 'mnist': mnist}, train_op, graph
for learning_rate in [0.1, 0.01, 0.001]:
vars, train_op, graph = cnn_model(learning_rate)
with tf.Session(graph=graph) as sess:
log_dir = os.path.join('cnn', 'cnn-lr-{}'.format(learning_rate))
writer = tf.summary.FileWriter(log_dir, sess.graph)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for i in range(500):
batch = vars['mnist'].train.next_batch(50)
if i % 100 == 0:
train_accuracy = vars['accuracy'].eval(feed_dict={vars['x']:batch[0],
vars['y']:batch[1]})
print("step %d, training accuracy %g"%(i, train_accuracy))
_, w_summary = sess.run([train_op, vars['summary']],
feed_dict={vars['x']:batch[0], vars['y']:batch[1]})
writer.add_summary(w_summary, i)上記のコードでは、パラメータ毎にSessionをつくって学習させているだけですが、cnnのログディレクトリ配下にサブディレクトリとして各パラメータのログを残すようにします。
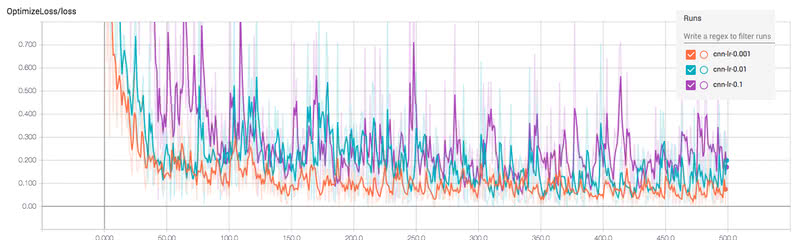
このようにすることで、先ほどと同様にTensorBoardをcnnをログディレクトリとして指定して起動することで、サブディレクトリの名前を付けて可視化できるようになります。以下の画像は、上記のコードを実行して可視化したものです。
可視化してみると、lossはオレンジ色の0.001のときが一番速く収束し、小さくなっていることがひと目で分かります。
Embedding Visualization
分散表現は、Word2VecやDoc2Vecなどの自然言語処理やレコメンドシステムでよく利用されます。TensorBoardでは、分散表現を可視化してインタラクティブに操作できるEmbedding Projectorという機能を備えています。
分散表現について詳しく知りたい方は、以下の記事を参考にしてください。
EmbeddingをTensorBoardで表示させる方法は、以下の手順で実装します。
(1) 2次元のテンソルの変数をつくる
(2) TensorBoardのログディレクトリにモデルを保存する
(3) 必要であれば、メタデータや画像ファイルを書き出す
import tensorflow as tf
import numpy as np
import os
from tensorflow.contrib.tensorboard.plugins import projector
from tensorflow.examples.tutorials.mnist import input_data
LOG_DIR = ...
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
xs = ... # 可視化したい対象
embedding_var = tf.Variable(xs, name='embedding')
summary_writer = tf.summary.FileWriter(LOG_DIR)
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
embedding.sprite.image_path = os.path.join(LOG_DIR, 'sprite_image.png')
embedding.sprite.single_image_dim.extend([28,28])
projector.visualize_embeddings(summary_writer, config)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"), 1)メタデータファイルの作り方
メタデータファイルは、最初の行にカラム名を指定して、メタ情報を2行目以降に書き込みます。例えば、MNISTの画像のメタデータを作る場合は、以下のように最初のカラムにインデックス、次のカラムにラベル名(数字)を指定します。
コードでメタデータファイルを作る場合は以下のように作成します。
with open('metadata.tsv','w') as f:
f.write("Index\tLabel\n")
for index, label in enumerate(xs):
f.write("%d\t%d\n" % (index, label))スプライト画像の作り方
スプライト画像を指定する場合は、以下の画像のように左上から順番に画像を構成します。
![]()
列数や行数は任意となっており、single_image_dim.extendで画像の幅と高さを指定します。
embedding.sprite.single_image_dim.extend([28,28])ラベルによる色分け
メタデータを指定することで、ラベルによる色分けをすることができるようになります。以下の図ように、左上のメニューから「Color by」の指定をメタデータのカラムします。
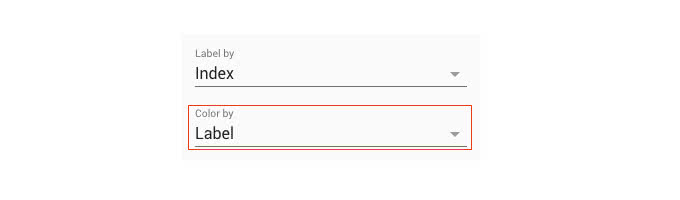
カラムを指定することで、マッピングされた画像に色が付きます。
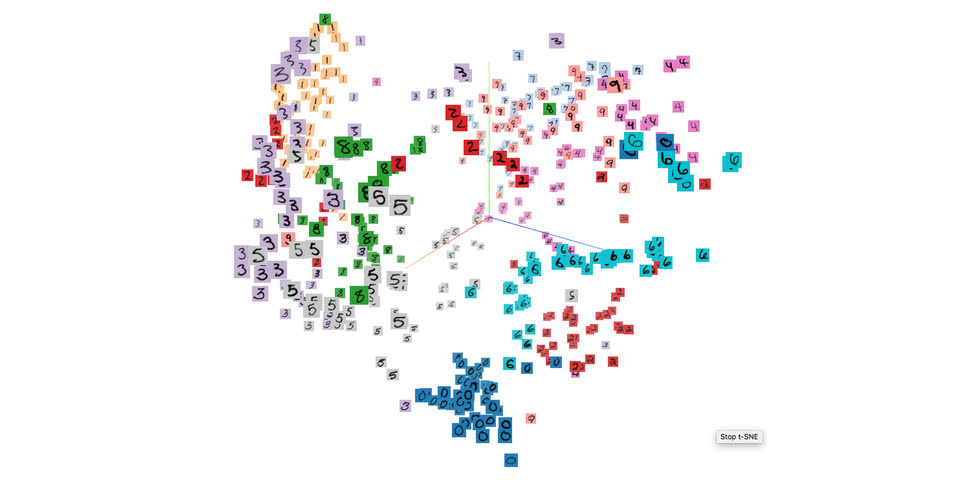
t-SNEとPCA
次元削減方法は、PCAとt-SNEを選択することができます。t-SNEを効果的に使う方法は以前解説しているので、以下の記事を参考にしてください。
高次元のデータを可視化するt-SNEの効果的な使い方 /machine_learning/2017/03/08/tsne.html
まとめ
本記事では、あらゆるデータを可視化する、TensorFlowの可視化ツールであるTensorBoardを解説しました。TensorBoardを使いこなすことで、機械学習モデルの設計やデバッグに大いに役立つことでしょう。
開発は活発なので、今後もさらにTensorBoardの機能は強化されそうです。