人間は、目の前で起きた出来事から、次に起こりそうな出来事を予測しながら文脈を読んで判断を下すことができます。例えば、車を運転している際に歩行者が飛び出しそうだと思えば、十分な間隔を置いて走行することが出来るでしょう。
また、現実世界は時間の制約を受ける事象はたくさんあります。アニメーションなどのストーリーでは、前回の文脈を前提として次の展開が進んでいきます。
Recurrent Neural Networksは、このような文脈を考慮することのできるニューラルネットワークのモデルの1つです。本記事では、
- Recurrent Neural Networkとは何か
- RNNの応用事例
- RNNの種類
- 仕組みと実装方法
を解説していきます。おそらく、RNNについて詳しく知りたい方の参考になるはずです。
Recurrent Neural Networksとは何か
Recurrent Neural Networks(RNN)は日本語では再帰型ニューラルネットワークと呼ばれ、数値の時系列データなどのシーケンシャルデータのパターンを認識するように設計されたニューラルネットワークのモデルです。
まずは、RNNについて詳細を知るために、一般的な順伝播型ニューラルネットワークについて考えてみましょう。以下の図を見てください。
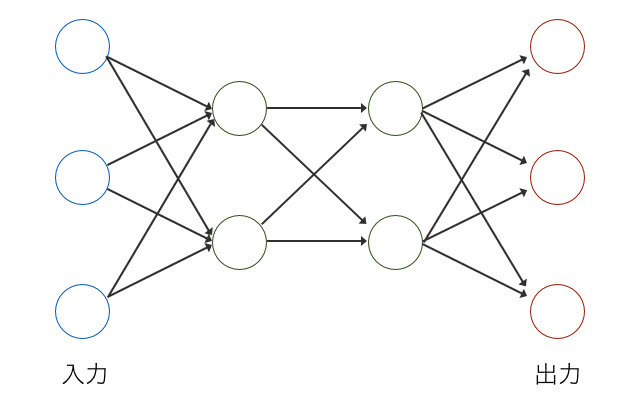
左側の青いノードが入力値で、右側の赤いノードが出力です。画像分類などでは、入力が画素値で出力が分類対象のカテゴリになります。このようにすることで、固定長の入力値に対して、固定長の分類対象を出力するニューラルネットワークを設計することができます。
しかし、現実世界のデータは固定長で定まらない場合がよくあります。例えば、ユーザが入力するツイートデータやブログの単語数は固定されていません。また、可変のサイズを持つ画像を入力や出力値として扱うことができません。入力と出力に可変長のデータを扱うことができるようにしているのがRNNです。RNNは、入力値と出力値に可変長のシーケンシャルデータを扱うことができるネットワーク構造をしています。
感情解析の例を考えてみましょう。任意の長さの文章列から、ポジティブかネガティブかを判定します。
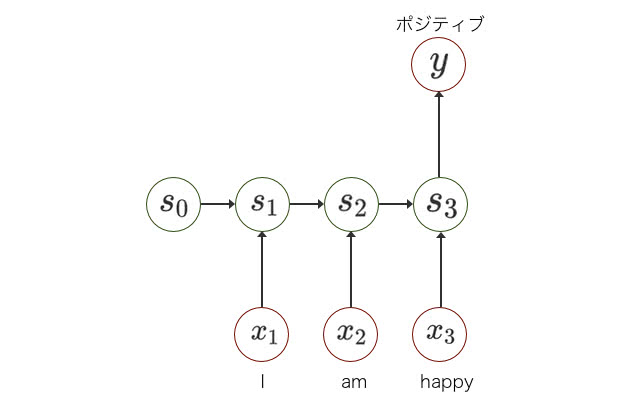
上図のように、RNNには状態があり、各時点 において入力値と状態に基いて次の状態に遷移させることができます。
入力は可変長の長さの単語列です。RNNは内部に状態を持ち、入力から次の状態へと遷移させることで状態を保持します。最後の単語が終わった時に、出力を予測させることができます。
RNNの応用事例
RNNは柔軟にデータを扱うことの出来るパワフルなモデルということもあって、応用範囲も広いです。
機械翻訳
近年、Google翻訳の精度が劇的に向上したのは、RNNのNeural Machine Translationが適用されたからです。機械翻訳は、英語から日本語に訳す際、入力サイズと出力サイズが固定されず、可変になります。
ニューラル翻訳は、Encoder Decoderモデルを基本としています。Encoder Decoderモデルは2種類のRNNで構成されています。以下の図を見てください。
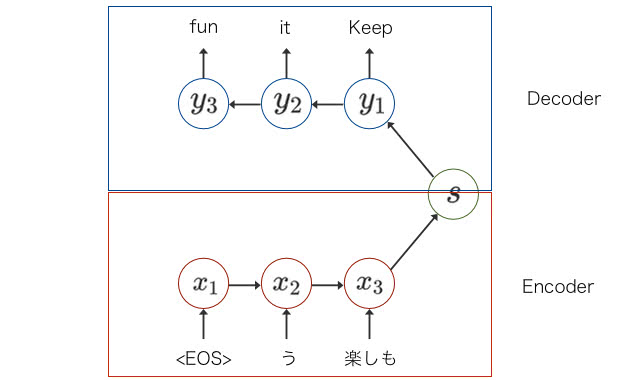
下部のEncoder部分のRNNで可変長の翻訳元文から状態に出力し、上部のDecoder部分で可変長の翻訳後の文を生成しています。
GoogleのNeural Machine Translationは、さらにAttentionと8層のResidual Connectionを導入したLSTMを使った強力なモデルになっていますが、RNNの拡張です。以下の図は、論文中のEncoderとDecoderの部分に利用されているLSTMの図です。
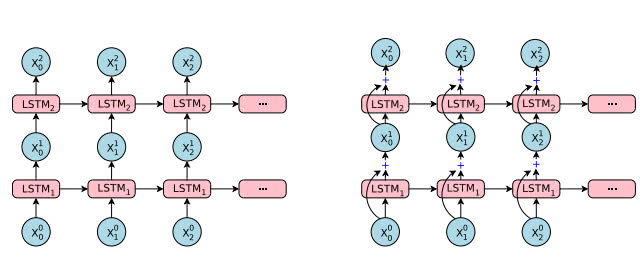
先程解説した、RNNの図とそっくりです。入力と出力が可変のLSTMが多層になっていて、Residual Connectionがありますが、基本は同様のモデルだということが分かります。
音声認識
音声認識も同様に、入力が可変長の音声で、出力が可変長の認識後のテキストになります。以下の画像は、スタンフォード大のDeep Neural Networkを使った音声認識の研究です。
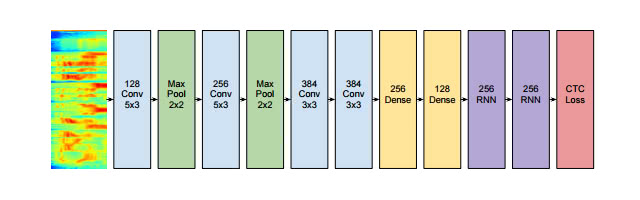
[3] End-to-End Deep Neural Network for Automatic Speech Recognition
音声を画像と見立てて、入力にConvolution層を使って、出力がRNNになっています。Convolution層とCNNについての詳細は、以下の記事を参考にしてください。
定番のConvolutional Neural Networkをゼロから理解する /deep_learning/2016/11/07/convolutional_neural_network.html
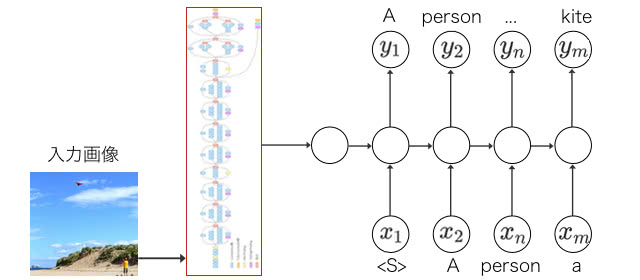
画像の概要生成
入力を画像にして、ニューラルネットワークに画像の説明をさせることができます。

こちらは、入力の画像をCNNで処理して、出力にRNNを使っています。
説明文からの画像生成
画像から説明文が出力できるなら、説明文から画像も出力することができます。以下の画像は、RNNで画像を生成した例です。

[6] [GENERATING IMAGES FROM CAPTIONS WITH ATTENTION]
知っておくと便利なRNNの種類と進化
RNNも他のネットワーク同様に、歴史が古く1980年代から提案されている手法です。本章では、知っておくと役に立つRNNの種類を紹介します。
Simple RNN
Simple Recurrent Network(単純再帰型ネットワーク)は、提案者の名前から通称Elman/Jordan netと呼ばれるRNNの一種です。
RNNは、状態を扱う有効閉路を持つニューラルネットワークです。Simple RNNは閉路上にコンテキスト(文脈)を持つ構造をしています。隠れ層が隠れ層自身に接続して、ある時点での状態を次の状態の入力値として使うことができます。つまり、適切に訓練さえされていれば、時間的な情報を受け渡すことができます。
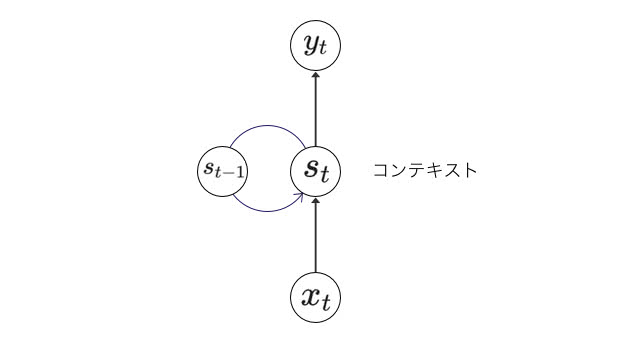
図中では、ある時点 での入力値 と 前回時点での状態 から新しい に状態が遷移します。そして、状態 から出力値の が出力されます。Simple RNNは以下のように定義することができます。
有効閉路が少し複雑に感じますが、下図のように、ループ構造を広げると考えやすいかもしれません。柔軟に入力や出力数に応じて展開される長いニューラルネットワークのように見立てることができます。
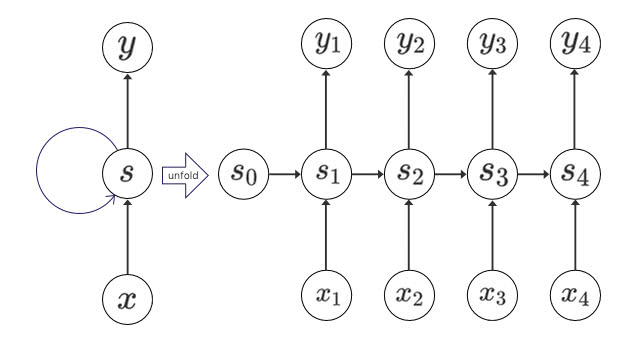
LSTM
Simple RNNでも理論上は上手くいきますが、現実的にはかなり前の古い情報を考慮するようには学習されませんでした。他のDeep Neural Networksと同様に、勾配消失の問題に直面したからです。
LSTMは、従来のRNNセルでは長期依存が必要なタスクを学習することができなかった問題を解決したモデルです。
LSTMの画期的な特徴は、「ゲート」と呼ばれる情報の取捨選択機構を持った点です。
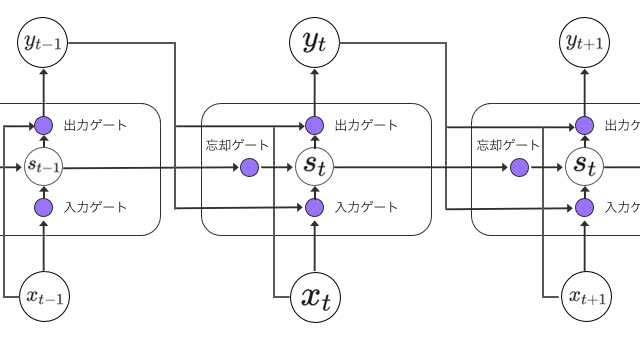
各ゲートでの情報の取捨選択は、シグモイド関数で行われます。出力が0であれば、ゲートを通さず、1であれば全て通します。仮に忘却ゲートを1にして、入力ゲートを0にすると、状態は永久に保持され続けます。実際の問題の文脈に応じて変更していく必要があります。
忘却ゲートのおかげで、言語モデルの例では、「彼は…」と続く文が終わったときに、主語が彼であるという状態を忘れるといったことができるようになります。時系列データでは季節の変わり目や日付の変更に対応できることもあるでしょう。
GRU
Gated Recurrent Unit(GRU)は、LSTMをもう少しシンプルにしたモデルです。入力ゲートと忘却ゲートを「更新ゲート」として1つのゲートに統合しています。
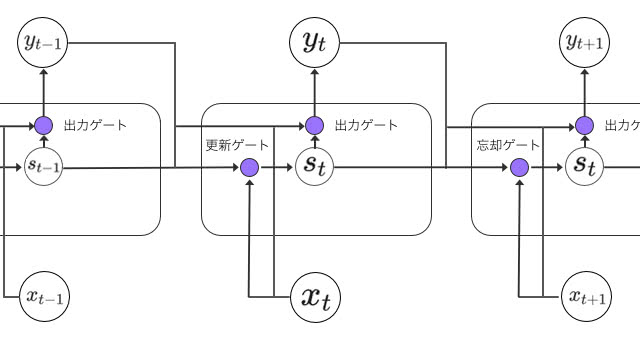
LSTMと同様に、このような忘却・更新ゲートを導入することで、長いステップ前の出来事の特徴の記憶を維持しやすくなります。なぜなら、各時間ステップ間を迂回するショートカットパスが効率的に生成されると言えるからです。そのおかげで、学習中に誤差を容易に逆伝播することができ、勾配消失の問題を軽減することになります。
Bi-directional RNN
Bi-directional RNNは、過去の情報だけでなく、未来の情報を加味することで精度を向上させるためのモデルです。一般的なRNNでは、過去から未来のみの情報で学習しますが、Bidirectional RNNは未来から過去の方向でも同時に学習します。
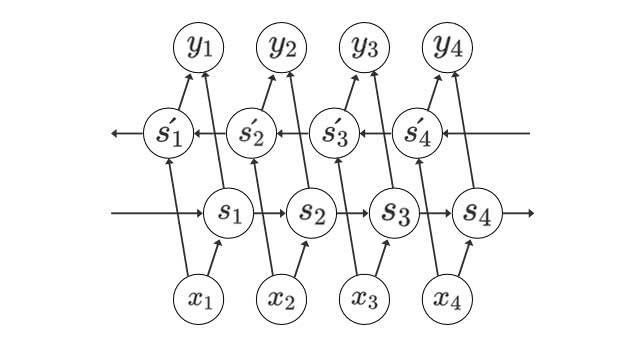
また、過去からの一方向での学習は、どのくらい前から予測すると誤差を最小化できるのかを決定するための「遅延パラメータ」を調節する必要がありますが、Bidirectional RNNではそのようなパラメータに学習が依存することはないので、チューニングの手間が減ります。
Bidirectional RNNの注意点は、未来の情報が分かっていなければ使えないということです。文章の推敲や、機械翻訳、フレーム間の補完などのタスクに向いています。
Attention RNN
Attention RNNは、その名の通り人間の「注意」を参考に設計されたモデルです。人間の視界は、集中している部分だけが高解像度となり、それ以外の部分の周辺視力は0.1程度になると言われています。文章であれば、翻訳する単語周辺に注意を払うはずです。
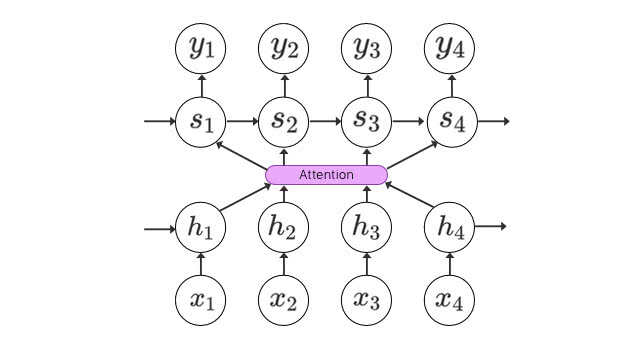
Attention RNNの応用範囲は広く、想像以上に面白い分野になると思われます。Attentionについての詳細は以下の記事を参考にしてください。
Quasi-Recurrent Neural Network
Quasi-Recurrent Neural Networkは、通称QRNNと呼ばれ、従来のRNNの学習の非効率さを解決するために提案されました。 一般的なRNNでは、一方向に過去の状態から遷移しないと、状態が計算できないために、並列化しにくく学習に時間がかかります。
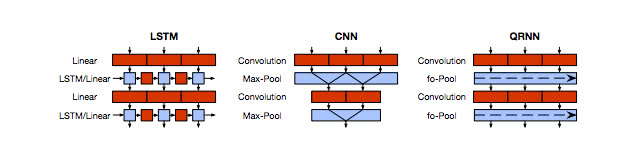
[9] [Quasi-Recurrent Neural Networks]
Quasi-Recurrent Neural Networkでは、CNNの仕組みを活かして、並列性を確保することで、高速かつ高精度のアーキテクチャになっています。
TensorFlowによるRNNの実装
それでは、RNNをTensorFlowで実装してみます。TensorFlowのインストールは以下の記事を参考にしてください。
機械学習初心者でもすぐに出来るTensorFlowのインストール方法 /tensorflow/2017/01/17/how-to-install-tensorflow.html
今回は、実装方法を知るためにシンプルなMNIST文字認識をRNNで実装してみます。MNISTのデータセットは、以下の図のような0~9の文字が入った28 × 28のグレースケール画像です。

この画像を上部から下部に向けて遷移させながらLSTMで学習します。以下のGIFアニメのように画像上部からタイムステップ毎に遷移させてどの数字になりそうかの情報を状態として保持するイメージです。

まずは、必要なライブラリをインポートして、MNISTのデータセットを読み込みます。
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)バッチ毎に28 × 28の画像を上から1ピクセルごとに読みこむための、xとyのプレースホルダを定義します。Noneの部分はバッチサイズに対応します。文字は0~9の10個に分類します。
x = tf.placeholder("float", [None, 28, 28])
y = tf.placeholder("float", [None, 10])RNNのモデルを定義していきます。128個の隠れ層のユニットを持つLSTMモデルです。最初に、各ステップ毎に分割されたテンソルに変換します。tf.unstack で [バッチサイズ × 28 ] の28個のテンソルを持つPythonのlistに変換されます。
def RNN(x):
x = tf.unstack(x, 28, 1)
# LSTMセルを定義する
lstm_cell = rnn.BasicLSTMCell(128, forget_bias=1.0)
# モデルの定義。各タイムステップの出力値と状態が返される
outputs, states = rnn.static_rnn(lstm_cell, x, dtype=tf.float32)
# 変数定義
weight = tf.Variable(tf.random_normal([128, 10]))
bias = tf.Variable(tf.random_normal([10]))
return tf.matmul(outputs[-1], weight) + bias
preds = RNN(x)コスト関数を定義します。今回は、学習させるためにクロスエントロピー誤差関数とAdam Optimizerを使います。
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=preds, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
# 評価用
correct_pred = tf.equal(tf.argmax(preds, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))最後にプレースホルダにイテレーション毎に教師データを定義したモデルに入れて学習していきます。
batch_size = 128
n_training_iters = 100000
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 1
# Keep training until reach max iterations
while step * batch_size < n_training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
# next_batchで返されるbatch_xは[batch_size, 784]のテンソルなので、batch_size×28×28に変換します。
batch_x = batch_x.reshape((batch_size, 28, 28))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % 10 == 0:
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print('step: {} / loss: {:.6f} / acc: {:.5f}'.format(step, loss, acc))
step += 1
# テスト
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, 28, 28))
test_label = mnist.test.labels[:test_len]
test_acc = sess.run(accuracy, feed_dict={x: test_data, y: test_label})
print("Test Accuracy: {}".format(test_acc))このコードを実行してみると、以下のようなログが出力されます。
step: 730 / loss: 0.156155 / acc: 0.95312
step: 740 / loss: 0.055120 / acc: 0.98438
step: 750 / loss: 0.240397 / acc: 0.92188
step: 760 / loss: 0.106830 / acc: 0.97656
step: 770 / loss: 0.053045 / acc: 0.99219
step: 780 / loss: 0.152972 / acc: 0.95312
Test Accuracy: 0.992187599.2%以上の精度で分類することができました。
まとめ
本記事では、ディープラーニングでも時系列データや可変長データを扱うことのできるRNNを紹介しました。CNNとRNNを理解するだけでも、実際にやれることの幅は大きく広がると感じます。
さらに勉強したい方は、本記事でも紹介したAttentionやBidirectional RNNに挑戦してみてください。
参考文献
[1] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
[2] Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
[3] End-to-End Deep Neural Network for Automatic Speech Recognition
[4] Deep Visual-Semantic Alignments for Generating Image Descriptions
[5] Show and Tell: A Neural Image Caption Generator
[6] GENERATING IMAGES FROM CAPTIONS WITH ATTENTION
[7] Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
[8] Bidirectional Recurrent Neural Networks
[9] Quasi-Recurrent Neural Networks
[10] Recurrent Neural Networks