ディープラーニングが盛んに研究され、実用化されはじめている。Googleの猫認識やAlphaGoがプロの囲碁棋士イ・セドル氏を打ち負かしたことは大きな話題を呼んだ。GoogleのプロダクトでもレコメンドやGoogle Photoの画像認識など、その役割は凄まじいものがある。
ディープラーニングの幕開けは2006年にHinton氏がDeep AutoEncoderやDeep Belief Networkを提案してからだと言われている。
また、ディープラーニングの紹介のされ方でよくあるのが
ディープラーニングを使うことで、コンピュータは自ら「猫」や「人の顔」といった特徴量を自己学習できる
というGoogleの猫認識の例がよく持ち出される。特に正解を与えることなく、コンピュータが自分で特徴をつかむようになったというのはキャッチーだし、ポテンシャルの高さを感じる。
この記事では、そんな訓練データなしで特徴を自己学習してしまうオートエンコーダを紹介しよう。
オートエンコーダ(自己符号化器)とは何か
オートエンコーダ(AutoEncoder)
オートエンコーダの核は次元削減である。オートエンコーダはニューラルネットワークの一種で、情報量を小さくした特徴表現を獲得するためにある。
入力と出力を同じデータにして学習することを考えてみよう。もし、各層の入力データが同じ次元になるとしたら、データはただ単に出力層に向かってコピーされればいい。
でも、隠れ層の次元が小さくなっていたらどうだろう?同様のデータを小さな情報量に圧縮する何らかの方法をニューラルネットワークは学習しないといけない。これこそがオートエンコーダのやっていることだ。
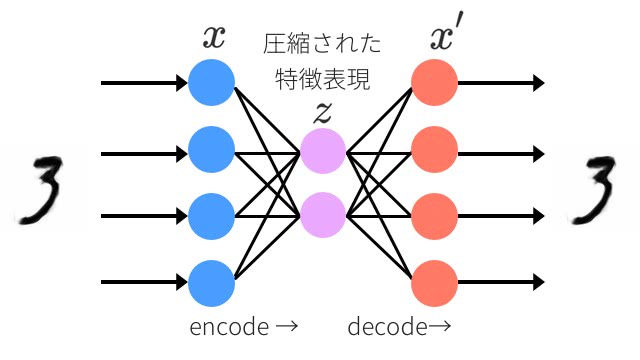
上図のように、入力データはニューラルネットワークを通してへ圧縮してから、出力時には元のサイズに戻ることが分かるだろう。もし、顔画像を入力したとしたら、目・鼻・表情…といった抽象的な概念としてニューラルネットワークは特徴を掴み始めているのかもしれない。
圧縮していく過程をエンコーダと呼び、復元する過程をデコーダと呼ぶ。エンコーダは入力を低次元に表現することができ、デコーダは低次元から復元する能力を持つ。
ニューラルネットワークの歴史
オートエンコーダの必要性を理解するために、ニューラルネットワークの歴史を簡単に振り返ろう。
Deep Learningはその名の通り、ニューラルネットワークの層を深くしたものだ。
でも、なぜこれまではニューラルネットワークを多層化することができなかったのだろう? そして、なぜ多層化したかったのだろう?
ニューラルネットワークの初期は神経細胞を模倣した形式ニューロンというものが提案された後に、パーセプトロンというモデルに発展した。 図にすると以下のような形で、入力ノードと出力の重み付けを学習することになる。
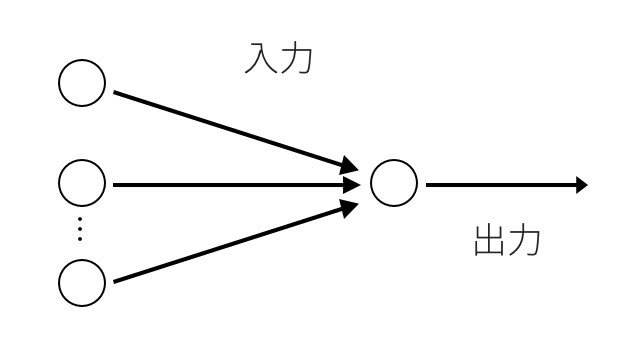
ただ、これではXORのような非線形の問題は解けないことが分かった。中間層の結合荷重が変わらないからだ。ここがパーセプトロンの弱点として残ることになった。
次にニューラルネットワークの研究で大きく進歩したのは、1986年にバックプロパゲーション(逆誤差伝搬法)が提案されたときで、パーセプトロンの弱点を克服したものだった。中間層の結合荷重も学習によって変えられるようになったのだ。
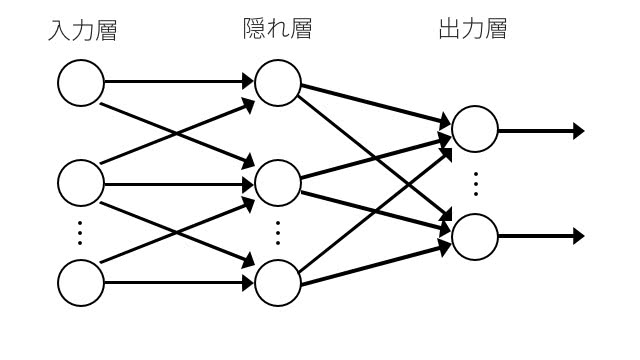
こうすることで、3層構造をもつニューラルネットワークを構築することができるようになったのだ。 実際に単純パーセプトロンと変わった点は2層を3層にしただけ。これだけで非線形な問題にも応用できるようになる。
ということは、さらに4層、5層と層を重ねていけばもっと高度な表現能力を獲得できるのではないだろうか?
という疑問が湧いてきてもおかしくない。そして実際どうもそうなりそうだということが分かってきた。
しかし、いざニューラルネットワークの層を深くして訓練してみると、残念ながら性能が下がってしまった。
なぜかというと、2つの問題点があったのだ。
- 勾配消失(Vanishing gradients):層を増やすにつれて、バックプロパゲーションでは徐々に最初の層に近づくにつれて情報を伝達出来なくなり、学習速度が遅くなっていった。
- 過学習(Overfitting):機械学習でよくあることだが、訓練データは正しく予測できるが、未知のデータがまったくダメになる。汎化性能が悪く、1つ1つ訓練データの答えを覚えるようになってしまった。層を深くすると、表現能力が高くなったものの、問題を複雑に捉えてしまった。
誤差逆伝播での勾配消失を防ぐ
ニューラルネットワークのパラメータの初期値をランダムではなく、オートエンコーダで訓練したものを用いるというアイデアが試された。
Greedy Layer-wise Trainingの場合は、まず教師なしデータで層のパラメータを1層1層順番に調整していく。
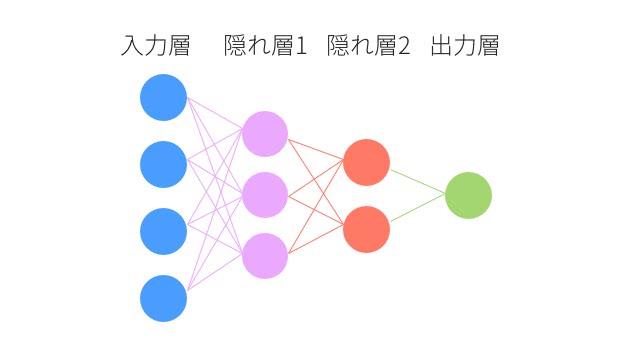
Stacked AutoEncoderでこのようなネットワークのパラメータを事前学習する時は、まず入力層と隠れ層1のパラメータをオートエンコーダで学習する。
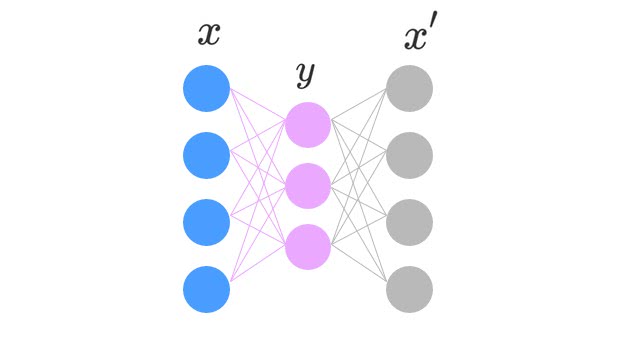
図のように、隠れ層1と同じサイズの次元を1つだけ隠れ層にしてオートエンコーダで訓練する。
次は、隠れ層2と出力層のパラメータを得るために、先程のを復元するようにオートエンコーダで学習する。
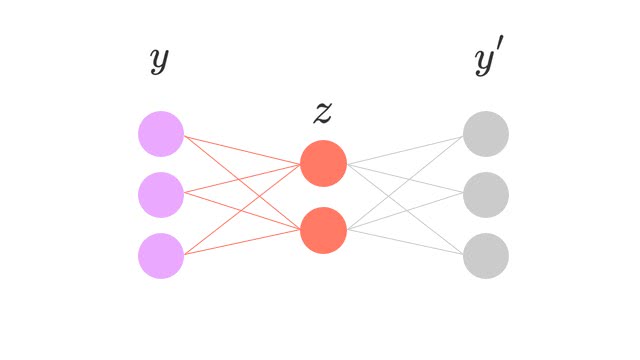
ここで得られたパラメータをニューラルネットワークの初期値に使う。
このようにオートエンコーダを用いてパーセプトロンの重みの初期値を予め推定しておくことを事前学習(pre-training)という。
こうすると、完全なランダム値と比べて、勾配消失問題が起こる可能性が小さくなり、層を深くしても学習がうまく進むことが分かった。
オートエンコーダは大成功だったか
では、オートエンコーダが今のディープラーニングを支えているのかというと、そうでもなさそうだ。深層学習ライブラリKerasのオートエンコーダのチュートリアルには、もう今では実用的な用途としてはめったに使われてないと書かれている。オートエンコーダは画像のノイズ除去や可視化程度でしか利用目的がないとされている。
実は、その後ディープラーニングのアルゴリズムは改良を重ね、事前学習をせずにランダム値を採用しても十分な精度が出るようになったのだ。
生成モデルとオートエンコーダ
一度オートエンコーダを訓練してしまえば、エンコーダとデコーダを別々に使うことができる。つまり、エンコーダをもっと意味のある小さな表現に圧縮するために使うこともできるし、デコーダをまだ見ぬ新しいデータを生成することだってできる。
よく考えてみると、人間もスポーツやクリエイティブな動画や画像・音楽を創作するときでも重要な「要素」や「原則」を頭の中でまとめていて、それを再現していると考えれば近いことをしているのかもしれない。
Variational Autoencoder
オートエンコーダの研究は進み、生成モデルで活用されはじめた。
Variational Autoencoderはこれまでの入力を受けて出力が決定論的に決まるAutoEncoderと違って確率的である。
Variational Autoencoderのエンコード部分は、MNIST画像を例にすると、784ピクセルの画像データから潜在変数を推論し、重みとバイアス を持つ確率分布
となる。
そして、デコーダ部分では、潜在変数 から画像 を生成し、重みとバイアス を持つ確率分布
である。
こうすると、任意の潜在変数を設定するとが生成できるようになる。下の写真のような、訓練データにないセレブ顔を生成することができる。

すごい!
下の動画も見て欲しい。パラメータをいじることで、色々な数字の画像が生成できる。
他にも、アルバムのジャケット画像や本物の写真のようなものを生成できたりするので、調べてみると面白い。
まとめ
よくディープラーニングと一緒に紹介されるオートエンコーダを紹介しました。
オートエンコーダは次元圧縮することを目的としているが、入力と出力を同じにする半教師あり学習で対象の特徴表現を自己学習してしまうところがポテンシャルを感じさせる。
そして、今は生成モデルでも効果を発揮しはじめている。
また、次のステップとしてGANやAdversarial Autoencodersも調べてみると面白いでしょう。
まだまだオートエンコーダの研究は進みそうですね。