
- NumPyでニューラルネットワークを実装してみる 基本編
- NumPyでニューラルネットワークを実装してみる 理論編
- NumPyでニューラルネットワークを実装してみる 実装編
- NumPyでニューラルネットワークを実装してみる 多層化と誤差逆伝播法編
- NumPyでニューラルネットワークを実装してみる 文字認識編
本シリーズの記事
今回の記事では、前回まで扱った内容を実際にNumPyで実装してみます。 最もシンプルな構造を実装してみることでニューラルネットワークに対する理解を深めていきましょう。
NumPyでの実装
今回は、NumPyを使ってニューラルネットワークで3種類のアヤメ(Iris)の品種を分類してみます。このデータセットは機械学習の基本としてはよく使われるもので、がく片の長さとその幅、花びらの長さをその幅をアヤメの3種類の花(「Iris setona」, 「Iris virginica」,「Iris versicolor」)についてそれぞれ50サンプルずつ単位をcmで計測したものとなっています。
今回はそのうちの2つ「Iris setona」と「Iris virginica」を4つのデータから分類してみましょう。
データセットの用意
まず、以下のリンクからアイリス花データをダウンロードしてください。
コマンドラインからは以下のコマンドでダウンロードすることができます。
$ wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
このデータを保存したディレクトリまで移動して、Pythonを起動します。今回は、データ読み込みのためにPandasを利用します。
まずはデータを読み込みます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv('iris.data', header=None) # 先程ダウンロードした'iris.data'を読み込む
print(df) # これで中身を表示させることができる。
y = df.iloc[0:100,4].values # 中身を見ると最初の100個分のデータがIris setonaとIris virginicaのものとなっているのでそこのラベルデータだけ抜き出す。
y = np.where(y=='Iris-setona',-1, 1) # ラベルがIris setonaなら-1、Iris virginicaだったら1として数値変換する。
X = df.iloc[0:100,[0,1,2,3]].values # 1~4番目のデータが今回学習に使うものなのでそれを抜き取る。この実行結果は以下のようになります。
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa
20 5.4 3.4 1.7 0.2 Iris-setosa
21 5.1 3.7 1.5 0.4 Iris-setosa
22 4.6 3.6 1.0 0.2 Iris-setosa
23 5.1 3.3 1.7 0.5 Iris-setosa
24 4.8 3.4 1.9 0.2 Iris-setosa
25 5.0 3.0 1.6 0.2 Iris-setosa
26 5.0 3.4 1.6 0.4 Iris-setosa
27 5.2 3.5 1.5 0.2 Iris-setosa
28 5.2 3.4 1.4 0.2 Iris-setosa
29 4.7 3.2 1.6 0.2 Iris-setosa
.. ... ... ... ... ...
120 6.9 3.2 5.7 2.3 Iris-virginica
121 5.6 2.8 4.9 2.0 Iris-virginica
122 7.7 2.8 6.7 2.0 Iris-virginica
123 6.3 2.7 4.9 1.8 Iris-virginica
124 6.7 3.3 5.7 2.1 Iris-virginica
125 7.2 3.2 6.0 1.8 Iris-virginica
126 6.2 2.8 4.8 1.8 Iris-virginica
127 6.1 3.0 4.9 1.8 Iris-virginica
128 6.4 2.8 5.6 2.1 Iris-virginica
129 7.2 3.0 5.8 1.6 Iris-virginica
130 7.4 2.8 6.1 1.9 Iris-virginica
131 7.9 3.8 6.4 2.0 Iris-virginica
132 6.4 2.8 5.6 2.2 Iris-virginica
133 6.3 2.8 5.1 1.5 Iris-virginica
134 6.1 2.6 5.6 1.4 Iris-virginica
135 7.7 3.0 6.1 2.3 Iris-virginica
136 6.3 3.4 5.6 2.4 Iris-virginica
137 6.4 3.1 5.5 1.8 Iris-virginica
138 6.0 3.0 4.8 1.8 Iris-virginica
139 6.9 3.1 5.4 2.1 Iris-virginica
140 6.7 3.1 5.6 2.4 Iris-virginica
141 6.9 3.1 5.1 2.3 Iris-virginica
142 5.8 2.7 5.1 1.9 Iris-virginica
143 6.8 3.2 5.9 2.3 Iris-virginica
144 6.7 3.3 5.7 2.5 Iris-virginica
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
[150 rows x 5 columns]| データの番号 | がく片の長さ | がく片の幅 | 花びらの長さ | 花びらの幅 | 種類名 |
の順番でデータが並んでいます。
次にこれらを訓練用のデータとうまく学習できたかを確かめるテスト用のデータとに分けます。今回はそれぞれサンプルが50ずつあるので、40組を訓練用データに、10組をテスト用データとして使います。うまく学習できたかどうかを確かめるためには10組のデータをどれだけ精度良く分類できたか評価します。
このように教師あり学習においては訓練用の集合とテスト用の集合を分けることで、訓練用の集合のみに過剰に学習してしまう過学習が起こっていないのかを確認することができます。
過学習すると、訓練用の集合に対しては良い結果を残すのに、テスト用の集合に対しては、学習モデルを使用すると著しく悪い結果となってしまうことがあります。
X_train = np.empty((80, 4)) # データを入れるための空の配列を作る
X_test = np.empty((20, 4))
y_train = np.empty(80)
y_test = np.empty(20)
X_train[:40],X_train[40:] = X[:40],X[50:90]
X_test[:10],X_test[10:] = X[40:50],X[90:100]
y_train[:40],y_train[40:] = y[:40],y[50:90]
y_test[:10],y_test[10:] = y[40:50],y[90:100]それではこれらのデータの中身を確認してみましょう。4つデータがありますが4次元空間にプロットすることはできないのでがく片と花びらの大きさで分けてプロットしてみましょう。
plt.title('Sepal') # がく片
plt.xlabel('length[cm]')
plt.ylabel('width[cm]')
plt.scatter(X_train[:40,0],X_train[:40,1],marker='x',color='blue', label='Iris setosa')
plt.scatter(X_train[40:,0],X_train[40:,1],marker='o', color='red',label='Iris virginica')
plt.legend()
plt.show()
# 次は花びら
plt.title('Petal') # 花びら
plt.xlabel('length[cm]')
plt.ylabel('width[cm]')
plt.scatter(X_train[:40,2],X_train[:40,3],marker='x',color='blue', label='Iris setosa')
plt.scatter(X_train[40:,2],X_train[40:,3],marker='o', color='red',label='Iris virginica')
plt.legend()
plt.show()これを行うと、以下のグラフがプロットされます。
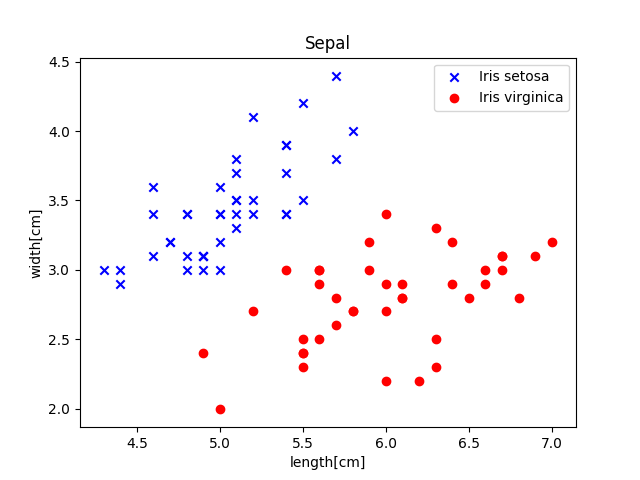
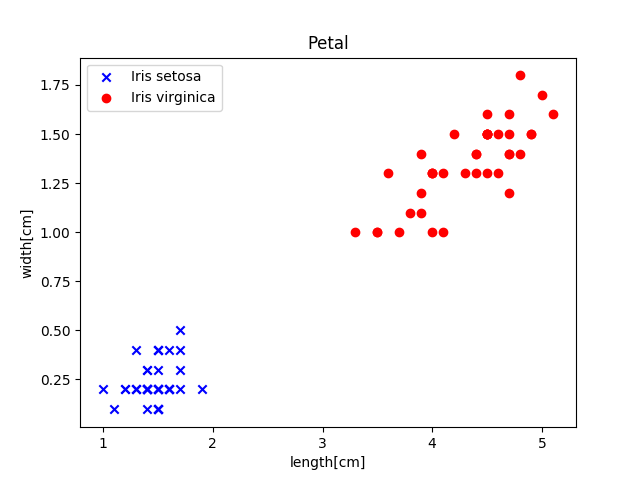
これを見るとグラフを見た感じ2つのデータだけでも十分線形分類することが可能そうですね。ですが、今回はニューラルネットワークを使ってみるという意味でこれら4種類のデータを元に分類していきたいと思います。
ニューラルネットワークの構築
では2章で扱ったニューラルネットワークを入力数だけ1つ増やした状態で再現してみたいと思います。これを模式図にすると以下のようになります。
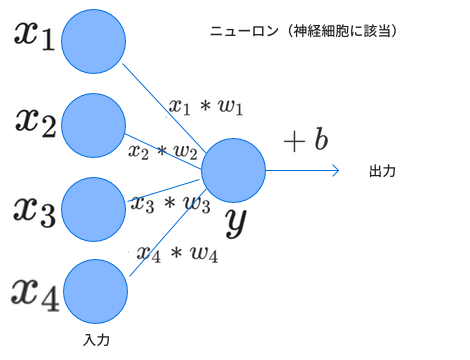
ではこれらを実装していきましょう。
def sigmoid(x):
return 1/(1+np.exp(-x))
def activation(X, w, b):
return sigmoid(np.dot(X,w)+b)
def loss(X, y, w, b):
dif = y - activation(X, w, b)
return np.sum(dif**2/(2*len(y)),keepdims=True)
def accuracy(X, y, w, b):
pre = predict(X, w, b)
return np.sum(np.where(pre==y,1,0))/len(y)
def predict(X, w, b):
result = np.where(activation(X, w, b)<0.5, -1.0, 1.0)
return result
def update(X, y, w, b, eta): # 解析的に重みの更新を行う。etaは学習率
a = (activation(X,w,b)-y)*activation(X,w,b)*(1-activation(X,w,b))
a = a.reshape(-1,1)
w -= eta * 1/float(len(y))*np.sum(a*X,axis=0)
b -= eta * 1/float(len(y))*np.sum(a)
return w, b
def update_2(X, y, w, b, eta): # w,bの値をそれぞれ少しだけ増加させたときにどれほど値が変動するかを計算することで偏微分を計算する。
h = 1e-4
loss_origin = loss(X, y, w, b)
delta_w = np.zeros_like(w)
delta_b = np.zeros_like(b)
for i in range(4):
tmp = w[i]
w[i] += h # パラメーターのうちの1つの値だけ少しだけ増加させる。
loss_after = loss(X, y, w, b)
delta_w[i] = eta*(loss_after - loss_origin)/h
w[i] = tmp
tmp = b
b += h
loss_after = loss(X, y, w, b)
delta_b = eta*(loss_after - loss_origin)/h
w -= delta_w # 値の更新
b = tmp - delta_b
return w, bupdate関数が2パターンありますが、1つ目のupdate()の方は2章で求めた偏微分の式をそのまま適用したものとなっています。2つ目のupdate_2()関数はこのような解析的に値を求めるのではなく、実際に少しだけパラメータ(例えば)の値をズラしたときにどれほど損失関数の値が増減するのかを計算して求めています。忘れがちですが微小変化量hで割ることを忘れないようにしてください。
また、学習率etaの設定をする必要があります。このように、学習モデルの手動で設定する必要がある値をハイパーパラメータと呼ぶことがあります。このetaは2章で扱ったをコードに落としたものなので新しい概念ではありません。
では、これらの関数を定義したところで学習を開始してみます。
weights_1 = np.ones(4)/10 # wの初期値は全部0.1
bias_1 = np.ones(1)/10 # bも初期値を0.1にする。
weights_2 = np.ones(4)/10
bias_2 = np.ones(1)/10
for _ in range(15): # とりあえず15回ほど学習させてみる
weights_1, bias_1 = update(X_train, y_train, weights_1, bias_1, eta=0.1)
weights_2, bias_2 = update(X_train ,y_train, weights_2, bias_2, eta=0.1)
print('acc_1 %f, loss_1 %f, acc_2 %f, loss_2 %f' % ( accuracy(X_test, y_test, weights_1, bias_1), \
loss(X_train, y_train, weights_1, bias_1)\
,accuracy(X_test, y_test, weights_2, bias_2), loss(X_test, y_test, weights_2, bias_2)))
print('weights_1 = ', weights_1, 'bias_1 = ', bias_1)
print('weights_2 = ', weights_2, 'bias_2 = ', bias_2)これの実行結果は以下のとおりです。
acc_1 0.500000, loss_1 0.137683, acc_2 0.500000, loss_2 0.137981
acc_1 0.500000, loss_1 0.127070, acc_2 0.500000, loss_2 0.127983
acc_1 0.500000, loss_1 0.118759, acc_2 0.500000, loss_2 0.120177
acc_1 0.500000, loss_1 0.112744, acc_2 0.500000, loss_2 0.114531
acc_1 0.500000, loss_1 0.108418, acc_2 0.500000, loss_2 0.110474
acc_1 0.500000, loss_1 0.105108, acc_2 0.500000, loss_2 0.107378
acc_1 0.500000, loss_1 0.102345, acc_2 0.500000, loss_2 0.104804
acc_1 0.500000, loss_1 0.099871, acc_2 0.500000, loss_2 0.102508
acc_1 0.800000, loss_1 0.097558, acc_2 0.800000, loss_2 0.100368
acc_1 0.900000, loss_1 0.095350, acc_2 0.900000, loss_2 0.098327
acc_1 1.000000, loss_1 0.093219, acc_2 1.000000, loss_2 0.096359
acc_1 1.000000, loss_1 0.091155, acc_2 1.000000, loss_2 0.094452
acc_1 1.000000, loss_1 0.089152, acc_2 1.000000, loss_2 0.092600
acc_1 1.000000, loss_1 0.087208, acc_2 1.000000, loss_2 0.090799
acc_1 1.000000, loss_1 0.085319, acc_2 1.000000, loss_2 0.089047
weights_1 = [-0.05802281 -0.08174334 0.19659068 0.15205468] bias_1 = [ 0.05802357]
weights_2 = [-0.05802281 -0.08174334 0.19659068 0.15205468] bias_2 = [ 0.05802357]update()、update_2()のどちらを用いてもうまく学習ができていることがわかりますね。また、パラメーターの値もそれほど変わっていないようです。
データ解析の中で微分を行うときはたいていupdate_2()関数のようにあるパラメーターを微小量変化させることでどれだけ値が変化したのかを調べることが多いです。
積分をするなら、このデータの値を単純に足し合わせます。
ただ、今回のモデルでは解析的に微分(特に偏微分)の値を数式で表すことができているのでそれを使って学習させてもみました。
まとめ
今回の章では前回、前々回で扱ったニューラルネットワークの構造を使ってアヤメの2品目のデータを使って分類を行ってみました。
一番シンプルなニューラルネットワークで分類をしてみましたが、ニューラルネットワークの魅力的なところはこのニューロンの数を増やしてさらに層を多くすることでより複雑なデータに対しても学習をすすめることができるという点です。 次回以降ではニューラルネットワークの構造を更に複雑にし、計算量が膨大になるのを防ぐための工夫の1つとして誤差逆伝播法について扱っていきたいと思います。