
- NumPyでニューラルネットワークを実装してみる 基本編
- NumPyでニューラルネットワークを実装してみる 理論編
- NumPyでニューラルネットワークを実装してみる 実装編
- NumPyでニューラルネットワークを実装してみる 多層化と誤差逆伝播法編
- NumPyでニューラルネットワークを実装してみる 文字認識編
本シリーズの記事
今回はニューラルネットワークをNumPyで実装するシリーズの2回目です。いよいよニューラルネットワークの理論について学んでみましょう。
理論的な背景を知ることで、今後の納得感が変わってくるはずです。
まずは最もシンプルな構造について学びます。
ニューラルネットワーク
前回は、脳内の認知メカニズムをざっくりとまとめました。それではこの章からは機械学習の分野で実際に使われているニューラルネットワークについて詳しく見ていきます。
ニューラルネットワークは、先程1章で紹介した脳における神経細胞の情報伝達の仕組みを模倣したものです。
神経細胞の模倣
では、先程学んだ内容を基に神経細胞の情報伝達の仕組みをモデル化していきましょう。 ここで1つ1つの神経細胞を表現しグラフのノードのように見ます。そしてそれぞれの神経細胞をエッジでつなぎます。
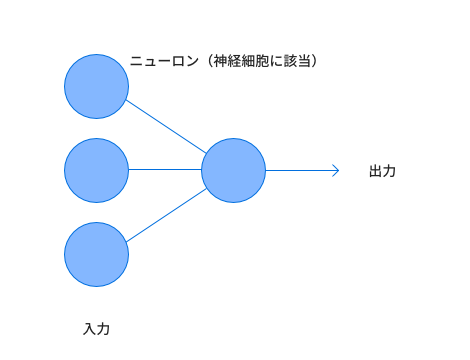
そこで信号を受け取ったニューロンが発火するための条件と発火した際に与える信号を考えます。まずそれぞれのニューロンから入力される値をとします。この3つの値を受け取ったニューロンから出力される値を とします。
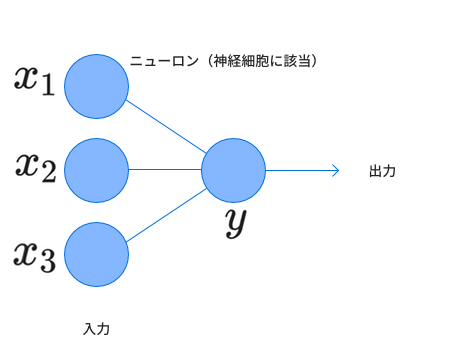
このとき、ある値を超えた時はを超えた分だけの値を出力し、それ以外のときは0を出力するものをとします。 ここにおけるは実際の神経細胞における活性電位(発火するために必要な電位)と見ることができます。実際は信号の強さを表す際、脳の神経細胞では発火の回数で表すのですが今回はそれを値の大きさで代用することにします。
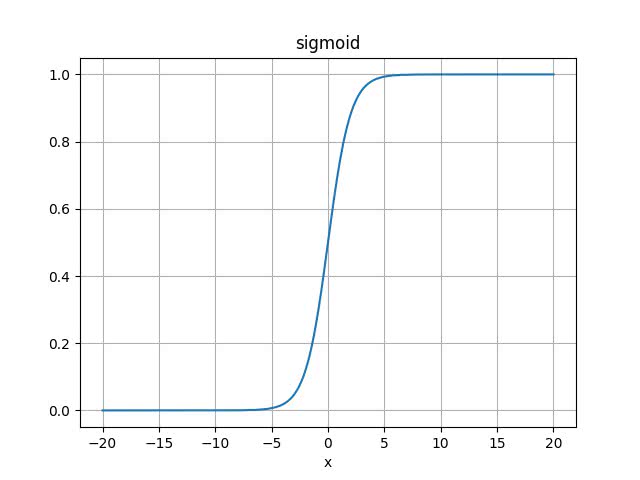
応答の様子は実験の結果よりシグモイド関数に形がよく似ていることが知られています。(ラットの実験の文献しか見つけられませんでした。筆者はどこかでそのような文面を読んだ記憶があるのですが出典を探せず申し訳ありません。)
なので、ここでもシグモイド関数を使ってそれを真似してみましょう。
シグモイド関数は以下のように表されます。
これをグラフにプロットすると、以下の図のようになります。
なので、先程のニューロンモデルにこれを適用すると、
となります。
今回扱うモデルでシグモイド関数のように入力された値に対するニューロンの出力の特性を決める関数を 活性化関数と呼びます。
パラメーターの導入
これでニューラルネットワークの基本構造を理解しました。しかし我々が行いたいのはこれを使って何かしらの学習させることです。
となると、学習の過程で変化する部分が欲しいですね。この状態ですと入力は学習の際は固定された値とみなすことができ、何も変化が起こらないのです。
そこで、これらの入力値に重みを加え、その重みを調整してあげることで学習を進めていくことにしましょう。 また、シグモイド関数の基準点は0にありますがそこに合わせるという意味でバイアスを入力の和に加えることにします。
この2種類のパラメーターを調整していくことにします。
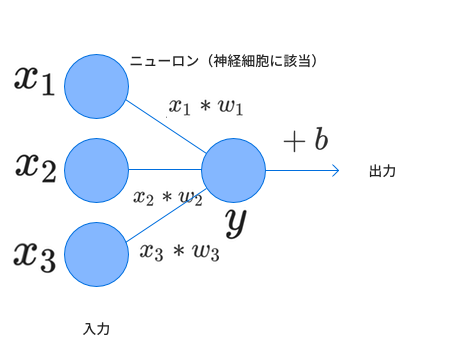
従って、出力 は
となります。これをベクトルに書き換えて、 とすると、内積の形で表すことができ、
となります。
これがニューラルネットワークの基本形となります。次は、このパラメータを学習させていきたいと思います。
損失関数の設定
それでは学習を始めていきますと言いたいところですが、もう1つ準備が必要です。
それは、学習がうまく進んだ理想の状態からどれだけ離れているのかを示そうとして我々が勝手に設定する関数です。一般的に損失関数と呼ばれています。
入力ベクトルに対して目標とする値をと表現します。
まず最初に思いつく損失関数は何でしょうか。2節まででニューラルネットワークの最も基本的なモデルを学んでいます。その出力ととの差をとってそれを合計するというのがまず思いつきますね。
なので損失関数をLとすると、
通常学習をするときは、1つの入力と目標値のセットだけでなく複数のセット(今回はN個のセットを使うとしました)を用いて行います。なのでそれらを合計したものを損失関数としています。
これでも問題ありませんが、このあとに行う学習を見越していくと以下の式のように差の2乗和がよく使われます。
ここでをかけるのは微分するときに具合がいいというだけで、それ以外の理由は特にないので本質的にはあってもなくても問題はありません。
またがかけられているのも、Nの大きさにかかわらずLの大きさが同じオーダーにおさまるように大きさを調整しているだけです。
この設定した損失関数をなるべく0に近づけるというのが今回の目標となります。
学習の進め方
それでは学習の進め方を説明していきたいと思います。
パラメーターをそれぞれ動かしたときに損失関数の値がどれだけ変動するかを基にパラメーターを動かしていきます。まずパラメータを1つだけを動かしてみてどれほど損失関数が変動するかを計算する必要があります。
その計算の仕方は数学的に言うならば偏微分ということになります。
他のパラメーターを動かさず、そのパラメーターを動かした時の変化の度合いを示し、
のかたちで表されます。例えば、2節でのニューラルネットワークの状態だとパラメーターはの4つで、例えばならば
右辺に関しては素直に微分すれば出てくる値ではありますが形があまりきれいにならなかったので、流し見する程度で大丈夫です。 ただ、最後にがかけられていることは覚えておいてください。バイアスにあたるbの場合だとなどのような値ではなく1をかけることになります。
パラメーターがそれぞれだけ変化した時、損失関数Lの変化分は
と表すことができます。これを見ると、を確実に負にするためには学習率を用いて
とすれば、
となります。こうすると偏微分の部分がすべて2乗となるので計算した損失関数の値を減らすことができます。