
- NumPyでニューラルネットワークを実装してみる 基本編
- NumPyでニューラルネットワークを実装してみる 理論編
- NumPyでニューラルネットワークを実装してみる 実装編
- NumPyでニューラルネットワークを実装してみる 多層化と誤差逆伝播法編
- NumPyでニューラルネットワークを実装してみる 文字認識編
本シリーズの記事
本記事でNumPyでニューラルネットワークを実装するシリーズは最後になります。
これまで、ニューラルネットワークの理論の簡単な解説と基本パーツをNumPyで実装してきました。 なんとなく難しそうな印象も、少しずつできそうな気持ちになっているかと思います。
今回は、MNIST文字認識をNumPyを使って実装してみましょう。
NumPyでの実装(MNIST)
データセットの用意
まずは文字認識をするためのデータセットを準備しましょう。
手書きで書かれた0~9の数字の文字画像を分類するタスクデータセットです。今回学習を進めていく対象は手書き数字の認識にしたいと思います。
手書き数字のデータはMNISTのデータセットを使います。MNISTは[Mixed National Institute of Standards and Technology database]の略になっており、28×28のピクセルデータとそれに対応する数字のラベルがセットになっているものが合計7万個(うち6万個が学習用1万個がテスト用)用意されています。
このデータセットは以下のサイトからダウンロードできます。
MNIST handwritten digit database
ここにあるファイルをダウンロードしましょう。以下のコマンドでダウンロードできます。
$ wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
$ wget http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
$ wget http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
$ wget http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Webブラウザからダウンロードする場合のリンクは下記の通りです。
train-images-idx3-ubyte.gz train-labels-idx1-ubyte.gz t10k-images-idx3-ubyte.gz t10k-labels-idx1-ubyte.gz
4つのファイルをダウンロードして、好きなフォルダに移動させてください(上のファイル名をクリックすればダウンロードできます)。同じディレクトリ内でプログラムを実行する前提でコードは書いてありますので注意してください。
そして、以下のプログラムをload_mnist.pyの名前で保存し、実行してみます。
import pickle
import numpy as np
import gzip
key_file ={
'x_train':'train-images-idx3-ubyte.gz',
't_train':'train-labels-idx1-ubyte.gz',
'x_test':'t10k-images-idx3-ubyte.gz',
't_test':'t10k-labels-idx1-ubyte.gz'
}
def load_label(file_name):
file_path = file_name
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
# 最初の8バイト分はデータ本体ではないので飛ばす
one_hot_labels = np.zeros((labels.shape[0], 10))
for i in range(labels.shape[0]):
one_hot_labels[i, labels[i]] = 1
return one_hot_labels
def load_image(file_name):
file_path = file_name
with gzip.open(file_path, 'rb') as f:
images = np.frombuffer(f.read(), np.uint8, offset=16)
# 画像本体の方は16バイト分飛ばす必要がある
return images
def convert_into_numpy(key_file):
dataset = {}
dataset['x_train'] = load_image(key_file['x_train'])
dataset['t_train'] = load_label(key_file['t_train'])
dataset['x_test'] = load_image(key_file['x_test'])
dataset['t_test'] = load_label(key_file['t_test'])
return dataset
def load_mnist():
# mnistを読み込みNumPy配列として出力する
dataset = convert_into_numpy(key_file)
dataset['x_train'] = dataset['x_train'].astype(np.float32) # データ型を`float32`型に指定しておく
dataset['x_test'] = dataset['x_test'].astype(np.float32)
dataset['x_train'] /= 255.0
dataset['x_test'] /= 255.0 # 簡単な標準化
dataset['x_train'] = dataset['x_train'].reshape(-1, 28*28)
dataset['x_test'] = dataset['x_test'].reshape(-1, 28*28)
return datasetMNISTのデータセットにおいては訓練用データは1つの手描き数字について28×28の784個のピクセルデータが保存されており、ラベルデータはその訓練用データの数字(0~9のいずれか)になっています。
load_label関数で、ラベルデータを解凍してone-hotベクトルに変換しています。
one-hotベクトルとは、分類対象のインデックスを1、残りを0にしたものです。例えば、0~9の10分類で3を表したい場合、4番目が3になるので、[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]となります。こうすることで、それぞれの数字である確率を計算する出力ニューロンを作ることができ、その差を確かめることができるようになります。
これを同じディレクトリ内に保存したのち、pythonをインタプリタで起動します。その後以下の操作を行うと読み込み完了です。
import load_mnist as lm
dataset = lm.load_mnist()せっかくなのでいくつかの画像をmatplotlibで表示させてみます。
import matplotlib.pyplot as plt
for i in range(20):
plt.subplot(4, 5, i+1)
plt.imshow(dataset['x_train'][i,:].reshape(28,28))
plt.show()その結果が以下の画像になります。

これからこれらの数字を機械に分類させていきます。
ネットワークの構築
では、データセットを読み込むことができたので、ニューラルネットワークを構築していきましょう。
以下のコードをneuralnet.pyの名前で保存してください。今回は入力ベクトルの要素数が28×28=784個あるのでそれに注意しながら実装を行います。
ニューロンの数は入力層784個、隠れ層100個、出力層10個です。まずはモデルを作るために必要な関数を用意します。
また、学習を効率よくすすめるために、複数のサンプルを一度に計算します。複数のサンプルを一度に計算するためにはどうすればいいでしょうか?入力する行列Xの形状を(サンプル数、784)とすれば問題ありませんね。
また、パラメータの初期値ですが重みパラメータについては標準正規分布に従ったものを今回は使っています。このような分布の方が学習が進みやすいということが経験則的にわかっているためです。
def make_params(shape_list): # shape_list = [784, 100, 10]のように層ごとにニューロンの数を配列にしたものを入力する
weight_list = []
bias_list = []
for i in range(len(shape_list)-1):
weight = np.random.randn(shape_list[i], shape_list[i+1]) # 標準正規分布に従った乱数を初期値とする
bias = np.ones(shape_list[i+1])/10.0 # 初期値はすべて0.1にする
weight_list.append(weight)
bias_list.append(bias)
return weight_list, bias_list次にモデルの計算を行う関数を用意します。ニューラルネットワークでの順伝播方向における計算に当たります。誤差逆伝播ができるように、途中の計算結果を記録する工夫をするといいでしょう。今回は損失関数まですべて記録する関数を作ってしまいました。処理時間を考えると無駄な計算をしてほしくはないのですが、今回はあくまで実装が目的ですのでわかりやすさ重視で実装します。
def sigmoid(x): # シグモイド関数
return 1/(1+np.exp(-x))
def inner_product(X, w, b): # ここは内積とバイアスを足し合わせる
return np.dot(X,w)+ b
def activation(X, w, b):
return sigmoid(inner_product(X, w, b))
def calculate(X, w_list, b_list, t): # 層ごとの計算結果を格納した配列を返す。
val_list = {}
a_1 = inner_product(X, w_list[0], b_list[0]) # (N, 1000)
y_1 = sigmoid(a_1) # (N, 100)
a_2 = inner_product(y_1, w_list[1], b_list[1]) # (N, 10)
y_2 = sigmoid(a_2) # これが本来は求めたい値。(N,10)
y_2 /= np.sum(y_2, axis=1, keepdims=True) # ここで簡単な正規化をはさむ
S = 1/(2*len(y_2))*(y_2 - t)**2
L = np.sum(S)
val_list['a_1'] = a_1
val_list['y_1'] = y_1
val_list['a_2'] = a_2
val_list['y_2'] = y_2
val_list['S'] = S
val_list['L'] = L
return val_list
def predict(X, w_list, b_list, t): # ここで予想を行う。
val_list = calculate(X, w_list, b_list, t)
y_2 = val_list['y_2']
result = np.zeros_like(y_2)
for i in range(y_2.shape[0]): # サンプル数にあたる
result[i, np.argmax(y_2[i])] = 1
return result次に損失関数を計算するloss関数と入力値に対して手書き数字を予想するpredict関数、そして最も重要なパラメータの更新を行うupdate関数を実装します。
update関数の中身は少々煩雑ですが、やっていること自体は前回の記事の逆伝播の図をそのままコードに起こしただけです。
def accuracy(X, w_list, b_list, t):
pre = predict(X, w_list, b_list, t)
result = np.where(np.argmax(t, axis=1)==np.argmax(pre, axis=1), 1, 0)
acc = np.mean(result)
return acc
def loss(X, w_list, b_list, t):
L = calculate(X, w_list, b_list, t)['L']
return L
def update(X, w_list, b_list, t, eta): # etaは学習率。ここでパラメータの更新を行う
val_list = {}
val_list = calculate(X, w_list, b_list, t)
a_1 = val_list['a_1']
y_1 = val_list['y_1']
a_2 = val_list['a_2']
y_2 = val_list['y_2']
S = val_list['S']
L = val_list['L']
dL_dS = 1.0
dS_dy_2 = 1/X.shape[0]*(y_2 - t)
dy_2_da_2 = y_2*(1.0 - y_2)
da_2_dw_2 = np.transpose(y_1)
da_2_db_2 = 1.0
da_2_dy_1 = np.transpose(w_list[1])
dy_1_da_1 = y_1 * (1 - y_1)
da_1_dw_1 = np.transpose(X)
da_1_db_1 = 1.0
# ここからパラメータの更新を行っていく。
dL_da_2 = dL_dS * dS_dy_2 * dy_2_da_2
b_list[1] -= eta*np.sum(dL_da_2 * da_2_db_2, axis=0)
w_list[1] -= eta*np.dot(da_2_dw_2, dL_da_2)
dL_dy_1 = np.dot(dL_da_2, da_2_dy_1)
dL_da_1 = dL_dy_1 * dy_1_da_1
b_list[0] -= eta*np.sum(dL_da_1 * da_1_db_1, axis=0)
w_list[0] -= eta*np.dot(da_1_dw_1, dL_da_1)
return w_list, b_listこれらの関数をすべてneuralnet.pyの名前で保存します。
学習を進める
これで準備が整いました。いよいよ学習を進めていきます。学習の進め方ですが、6万個のデータすべてを一気に読み込んでパラメータをアップデートするのではなく、それぞれ小さいサイズのバッチにしてそれを学習させていきたいと思います。
バッチの選び方は乱数関数を使ってランダムにしています。このような工夫をすることで学習の偏りを防ぐことにもつながります。
load_mnist.pyとneuralnet.pyの2つのファイルと先ほどダウンロードしたmnistのデータセットが同じディレクトリにあることを確認したら、pythonのインタプリタを起動し以下のコードを実行してください。
import numpy as np
import neuralnet as nl
import load_mnist
dataset = load_mnist.load_mnist()
X_train = dataset['x_train']
t_train = dataset['t_train']
X_test = dataset['x_test']
t_test = dataset['t_test']
weight_list, bias_list = nl.make_params([784, 100, 10])
train_time = 10000# 何回学習を行うか指定します
batch_size = 1000 # 1回の学習でいくつのデータを学習するかを指定します。
total_acc_list = [] # 精度と損失がどれだけ変動したかを記録する配列を作る
total_loss_list = []
for i in range(train_time):
ra = np.random.randint(60000, size=batch_size) # 0~59999でランダムな整数をbatch_size分だけ発生させる。
x_batch, t_batch = X_train[ra,:], t_train[ra,:]
weight_list, bias_list = nl.update(x_batch, weight_list, bias_list, t_batch, eta=2.0)
# ここでパラメータの更新をおこなう。etaは学習率でどれぐらいの割合でパラメータを更新するかを決める。
# 今回は2.0で行う。
# 実際は試行錯誤してこの値を決めていくことになる。
if (i+1)%100 == 0: # 5回ごとにどれぐらい学習できているかを確かめる。
acc_list = []
loss_list = []
for k in range(10000//batch_size):
x_batch, t_batch = X_test[k*batch_size:(k+1)*batch_size, :], t_test[k*batch_size:(k+1)*batch_size, :]
acc_val = nl.accuracy(x_batch, weight_list, bias_list, t_batch)
loss_val = nl.loss(x_batch, weight_list, bias_list, t_batch)
acc_list.append(acc_val)
loss_list.append(loss_val)
acc = np.mean(acc_list) # 精度は平均で求める
loss = np.mean(loss_list) # 損失は合計で求める。
total_acc_list.append(acc)
total_loss_list.append(loss)
print("Time: %d, Accuracy: %f, Loss: %f"%(i+1, acc, loss))これの実行結果は以下のようになります。
Time: 100, Accuracy: 0.382900, Loss: 0.403673
Time: 200, Accuracy: 0.587400, Loss: 0.278362
Time: 300, Accuracy: 0.677600, Loss: 0.221165
Time: 400, Accuracy: 0.734600, Loss: 0.186000
Time: 500, Accuracy: 0.768300, Loss: 0.164885
Time: 600, Accuracy: 0.792800, Loss: 0.149276
Time: 700, Accuracy: 0.807700, Loss: 0.139569
Time: 800, Accuracy: 0.823000, Loss: 0.130376
Time: 900, Accuracy: 0.832400, Loss: 0.124007
Time: 1000, Accuracy: 0.839500, Loss: 0.118748
Time: 1100, Accuracy: 0.844200, Loss: 0.114433
Time: 1200, Accuracy: 0.849600, Loss: 0.110778
Time: 1300, Accuracy: 0.854600, Loss: 0.107168
Time: 1400, Accuracy: 0.856600, Loss: 0.104603
Time: 1500, Accuracy: 0.863700, Loss: 0.101315
Time: 1600, Accuracy: 0.864300, Loss: 0.099288
Time: 1700, Accuracy: 0.867300, Loss: 0.097561
Time: 1800, Accuracy: 0.870100, Loss: 0.095302
Time: 1900, Accuracy: 0.868700, Loss: 0.094428
Time: 2000, Accuracy: 0.876000, Loss: 0.091742
Time: 2100, Accuracy: 0.874900, Loss: 0.090509
Time: 2200, Accuracy: 0.878400, Loss: 0.089042
Time: 2300, Accuracy: 0.881700, Loss: 0.087551
Time: 2400, Accuracy: 0.883700, Loss: 0.086134
Time: 2500, Accuracy: 0.884000, Loss: 0.084790
Time: 2600, Accuracy: 0.885900, Loss: 0.083458
Time: 2700, Accuracy: 0.887800, Loss: 0.082649
Time: 2800, Accuracy: 0.889500, Loss: 0.081992
Time: 2900, Accuracy: 0.889800, Loss: 0.081002
Time: 3000, Accuracy: 0.890200, Loss: 0.080084
Time: 3100, Accuracy: 0.890900, Loss: 0.079392
Time: 3200, Accuracy: 0.894700, Loss: 0.078638
Time: 3300, Accuracy: 0.895400, Loss: 0.077517
Time: 3400, Accuracy: 0.898000, Loss: 0.077156
Time: 3500, Accuracy: 0.898000, Loss: 0.076447
Time: 3600, Accuracy: 0.898400, Loss: 0.076063
Time: 3700, Accuracy: 0.899900, Loss: 0.075024
Time: 3800, Accuracy: 0.902200, Loss: 0.074246
Time: 3900, Accuracy: 0.901600, Loss: 0.074015
Time: 4000, Accuracy: 0.902500, Loss: 0.073258
Time: 4100, Accuracy: 0.901100, Loss: 0.073228
Time: 4200, Accuracy: 0.903800, Loss: 0.072166
Time: 4300, Accuracy: 0.904100, Loss: 0.071767
Time: 4400, Accuracy: 0.906000, Loss: 0.071110
Time: 4500, Accuracy: 0.907300, Loss: 0.071035
Time: 4600, Accuracy: 0.906600, Loss: 0.070614
Time: 4700, Accuracy: 0.908100, Loss: 0.069804
Time: 4800, Accuracy: 0.908600, Loss: 0.069464
Time: 4900, Accuracy: 0.909300, Loss: 0.069170
Time: 5000, Accuracy: 0.908400, Loss: 0.068861
Time: 5100, Accuracy: 0.908800, Loss: 0.068615
Time: 5200, Accuracy: 0.909200, Loss: 0.068339
Time: 5300, Accuracy: 0.910300, Loss: 0.068018
Time: 5400, Accuracy: 0.910300, Loss: 0.067600
Time: 5500, Accuracy: 0.911400, Loss: 0.067109
Time: 5600, Accuracy: 0.911300, Loss: 0.066777
Time: 5700, Accuracy: 0.911800, Loss: 0.066371
Time: 5800, Accuracy: 0.912400, Loss: 0.066106
Time: 5900, Accuracy: 0.913200, Loss: 0.065872
Time: 6000, Accuracy: 0.913600, Loss: 0.065197
Time: 6100, Accuracy: 0.913200, Loss: 0.065258
Time: 6200, Accuracy: 0.914100, Loss: 0.064977
Time: 6300, Accuracy: 0.913100, Loss: 0.064849
Time: 6400, Accuracy: 0.914700, Loss: 0.064246
Time: 6500, Accuracy: 0.915600, Loss: 0.064094
Time: 6600, Accuracy: 0.915800, Loss: 0.063901
Time: 6700, Accuracy: 0.915300, Loss: 0.063391
Time: 6800, Accuracy: 0.915500, Loss: 0.063486
Time: 6900, Accuracy: 0.915700, Loss: 0.063242
Time: 7000, Accuracy: 0.915600, Loss: 0.062820
Time: 7100, Accuracy: 0.916600, Loss: 0.062620
Time: 7200, Accuracy: 0.916500, Loss: 0.062367
Time: 7300, Accuracy: 0.916500, Loss: 0.062098
Time: 7400, Accuracy: 0.917900, Loss: 0.062266
Time: 7500, Accuracy: 0.917900, Loss: 0.061837
Time: 7600, Accuracy: 0.918500, Loss: 0.061539
Time: 7700, Accuracy: 0.918200, Loss: 0.061474
Time: 7800, Accuracy: 0.918300, Loss: 0.061461
Time: 7900, Accuracy: 0.918700, Loss: 0.061002
Time: 8000, Accuracy: 0.918300, Loss: 0.060696
Time: 8100, Accuracy: 0.919900, Loss: 0.060329
Time: 8200, Accuracy: 0.920700, Loss: 0.060255
Time: 8300, Accuracy: 0.919500, Loss: 0.060028
Time: 8400, Accuracy: 0.919500, Loss: 0.059927
Time: 8500, Accuracy: 0.921800, Loss: 0.059559
Time: 8600, Accuracy: 0.921100, Loss: 0.059541
Time: 8700, Accuracy: 0.921000, Loss: 0.059460
Time: 8800, Accuracy: 0.921700, Loss: 0.059232
Time: 8900, Accuracy: 0.921700, Loss: 0.059117
Time: 9000, Accuracy: 0.921900, Loss: 0.059048
Time: 9100, Accuracy: 0.922500, Loss: 0.058672
Time: 9200, Accuracy: 0.923100, Loss: 0.058530
Time: 9300, Accuracy: 0.923000, Loss: 0.058436
Time: 9400, Accuracy: 0.922700, Loss: 0.058192
Time: 9500, Accuracy: 0.922800, Loss: 0.058274
Time: 9600, Accuracy: 0.923200, Loss: 0.058136
Time: 9700, Accuracy: 0.923000, Loss: 0.057863
Time: 9800, Accuracy: 0.924300, Loss: 0.057614
Time: 9900, Accuracy: 0.924100, Loss: 0.057330
Time: 10000, Accuracy: 0.925200, Loss: 0.057208徐々に精度が上がっていく様子がわかると思います。これを以下のコードでグラフにしてみます。
import matplotlib.pyplot as plt
plt.subplot(211)
plt.plot(np.arange(0, train_time, 100),total_acc_list)
plt.title('accuracy')
plt.subplot(212)
plt.plot(np.arange(0, train_time, 100), total_loss_list)
plt.title('loss')
plt.show()この出力結果は以下のとおりです。
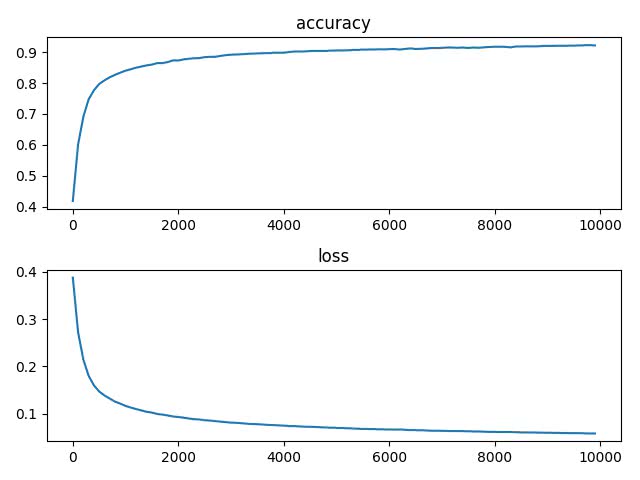
順調に損失関数の値が減っていき、順調に精度が上昇しています。最終的には90%を超える精度を出すことができました。
まとめ
今回は、今まで扱った内容をコードに書き起こしてみました。シンプルな構造のニューラルネットワークだったら0から書き起こすことも可能だということがわかっていただけたでしょうか。
TensorFlowなどのニューラルネットワークをブラックボックス化せずに、NumPyで一度簡単にでもコードを書いてみると何をしているのか理解しやすくなります。
NumPyのコードを書くという意味でもこれらの実装はとても良い練習となっていますので是非他の記事を参考にしながら自分なりに実装してみてください。