
- NumPyでニューラルネットワークを実装してみる 基本編
- NumPyでニューラルネットワークを実装してみる 理論編
- NumPyでニューラルネットワークを実装してみる 実装編
- NumPyでニューラルネットワークを実装してみる 多層化と誤差逆伝播法編
- NumPyでニューラルネットワークを実装してみる 文字認識編
本シリーズの記事
今回は、NumPyとニューラルネットワークを使った手書き文字認識に向けた最終的な理論を勉強しましょう。 これまで扱ってきたニューラルネットワークの構造を拡張して多層ニューラルネットワークにしていきます。 多層ニューラルネットワークの基本を勉強したのちに、手書き文字の認識をしていきます。
ニューラルネットワークの拡張と誤差逆伝播法
手書き数字の文字認識はMNISTと呼ばれる1〜9までの画像データを扱います。入力されるデータは28×28の784ピクセル分のデータです。
そして、学習時間の大幅な短縮に貢献している誤差逆伝播法についても扱っていきます。誤差逆伝播法の説明は以下の記事で詳しく解説しています。
誤差逆伝播法を計算グラフを使ってわかりやすく解説する /deep_learning/2017/04/02/backpropagation.html
多層ニューラルネットワークへの拡張
2章で扱った基本的なニューラルネットの構造は以下のようなものでした。
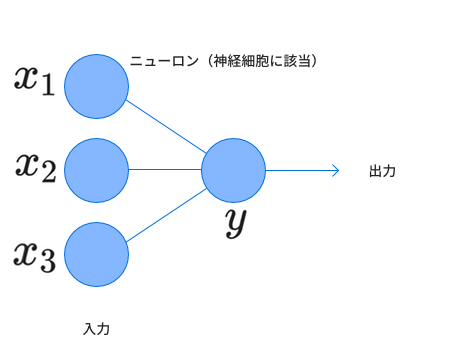
このネットワークは2層のニューラルネットワークと表すことができ、左側を入力層、右側を出力層と呼びます。拡張は2つの方向で行います。
1. 各層のニューロンを増やす
各層ごとのニューロンの数を増やすことで拡張することができます。例えば、入力層でのニューロンの数を5つ、出力層でのニューロンの数を3つに増やすと以下の図のようになります。
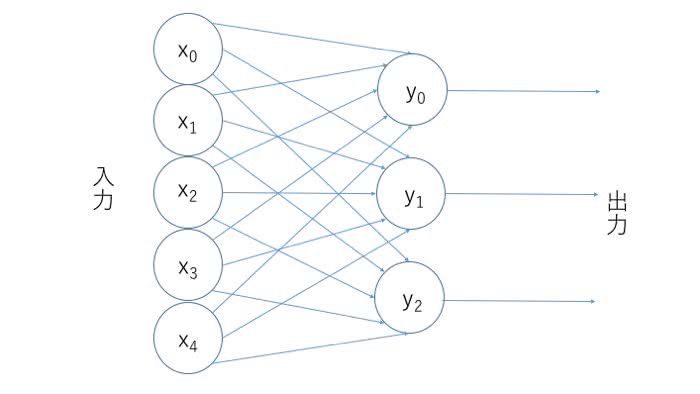
この構造では、出力される値が3つになり、これを元に何かしらの結果を出力することになります。例えば、何かしらの特徴から3つの果物を分類する場合には、それぞれの果物である確率が出力されることでしょう。
今回の手書き文字の場合、使うデータは28×28のピクセルデータ784個が入力層に相当し、入力されたデータが0~9である確率を示す出力ニューロンが10個あるものを作ることができます。
実はこのように層ごとにニューロンを配置することで行列をうまく使って計算することができます。
ここで、 に対する の重みを と表すとします。つまり、に対するの重みをと表すとすると、重み行列Wは
従って、出力 は、バイアスベクトル を用いて、
と表すことができます。1つ1つの要素を見ると、例えばは
で、シグモイド関数と呼び、
を表していました。従って、これらをまとめると先程の行列表記で書き表すことができるのです。このようにして、NumPyでの実装を楽にすることができます。
2. 層を増やす
次に層を増やします。層の増やし方ですが、出力層と入力層との間に隠れ層という名前で挿入していく形になります。 先程のニューラルネットワークに隠れ層を1つ、ニューロンの数4つを挿入してみましょう。
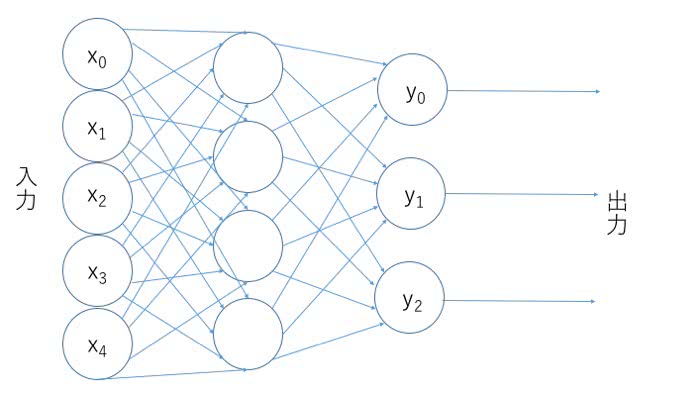
隠れ層での出力a とバイアスベクトル を使うと入力ベクトルを として
従って 出力は、
となります。学習の基本方針は変わらずで、出力の目標ベクトルをとすると損失関数Lは
を最小にすることになります。重みの更新は学習率を用いて
で行われます。
層のニューロンを増やしたり、層を増やしたりすることの直感的な理解はTensorFlow Playgroundを使って自分で試すことができます。以下の記事を参考にしてください。
2節 誤差逆伝播法
これでニューラルネットワークの拡張は完了です。手書き文字認識ではニューロンの数が入力層が784個、隠れ層に1000個、出力層10個といった具合になります。
しかしながら、パラメーターの数がと3層構造にしただけで膨大な量となってしまいます。この要素数の偏微分をいちいち計算していたら1回あたり相当な時間がかかりそうですね。
この誤差の計算を高速にするために考えられたのが誤差逆伝播法です。先程もリンクを張ったように、誤差逆伝播法の詳しい解説は以下の記事に記載してあるので参考にしてください。
誤差逆伝播法を計算グラフを使ってわかりやすく解説する /deep_learning/2017/04/02/backpropagation.html
簡潔に説明すると、偏微分を連鎖律を用いてうまく計算しましょうということになります。連鎖律は以下のような関係が成り立つことを言います。
見た目的には分数の掛け算をしていって最終的に同じ形になるように偏微分の値をかけていくと求める偏微分の値になるものです。これを計算グラフで表すと例えばだとすると
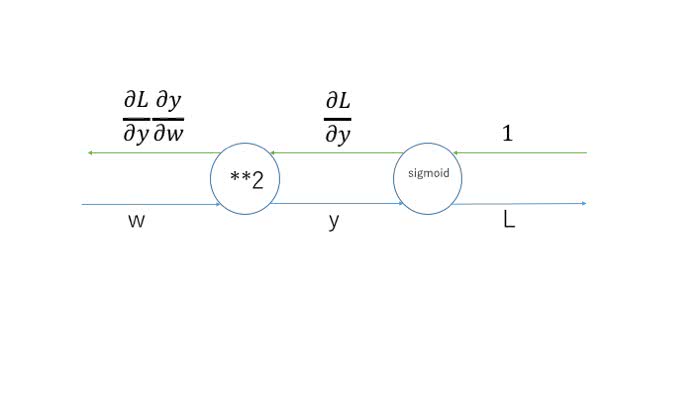
このように表すことができます。下側が順伝播で、上側が逆伝播によって計算された偏微分の値です。
これを組み合わせると、
と表せます。これが誤差逆伝播です。
実は、以前に解析的に偏微分をしたものが誤差逆伝播の結果を使ったものになります。では今回作ったニューラルネットワークに対してはどのように立式できるのでしょうか。
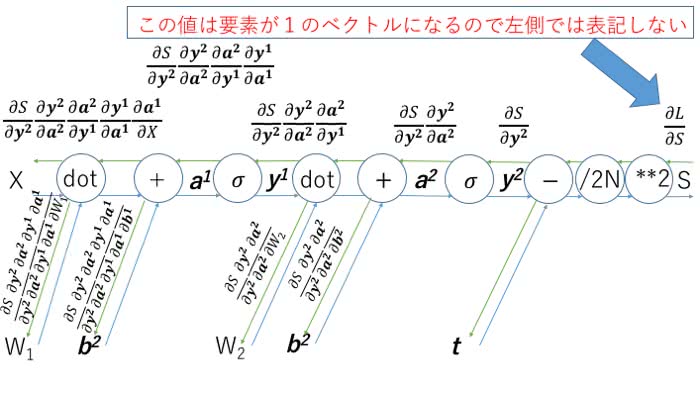

少し図が汚くなりましたが、このような感じになります。1つ1つの偏微分の値について見ていきましょう。内積との区別をするため、対応する要素に同士しか掛け算をしないアダマール積を使って表現します。
このように連鎖律を組み合わせることで偏微分の値を計算することができます。行列が偏微分の値になっているところは出力に対して内積をかけることで計算可能になります。内積の順番は形状を念頭に掛け合わせると順番を間違えないですみます。
偏微分の値を計算したらあとは学習率をかけて、パラメーターから引いてあげればパラメーターの更新をすることができます。
では、なぜ計算時間が短縮されるのでしょうか?
数値微分(パラメーターを少しだけ値を動かしてそのときの損失関数の値の変化を見る方法)ではパラメーターの回数分だけ損失関数を計算する必要が出てきます。今回使用するニューラルネットワークには76万個ものパラメーターが存在するのです。
すべてのパラメータを更新しようと思ったら1回更新するだけで76万回行列演算を繰り返す必要があります。一方で、誤差逆伝播法なら損失関数を計算するのは1回だけですみます。あとは途中での出力を記録さえしていればその値の組み合わせでパラメーターを更新することが可能になります。
まとめ
今回は、手書き数字認識のための前準備を行いました。まずはニューラルネットワークの構造自体を拡張し、計算時間を短縮するためには誤差逆伝播法が有効だという話をしました。
次回はこれらを使っていよいよ手書き数字データを分類していきます。